【干货】基于属性学习和额外知识库的图像描述生成和视觉问答
【导读】这篇论文提出一种将高层次的概念与CNN-RNN成功结合的方法,并且实验表明这种方法在图像语义生成和视觉问答方面都取得了显着的进步。通过设计一个视觉问答模型,将图像内容的内部表示与从知识库中提取的信息相结合,以回答广泛的基于图像的问题,最终的模型在几个主要的基准数据集上实现了图像语义生成和视觉问答的最佳结果。
论文:Image Captioning and Visual Question Answering Based on Attributes and External Knowledge

▌摘要
视觉问答问题最近取得的许多进展是通过卷积神经网络(CNN)和递归神经网络(RNN)的组合来实现的。这种方法没有明确表示高层次的语义概念,而是试图直接建立图像特征和文本特征之间的关系。本文首先提出一种将高层次的概念与CNN-RNN成功结合的方法,并且表明它在图像语义生成和视觉问答方面都取得了显着的进步。进一步研究表明,同样的机制可以用来结合外部的知识,这对于回答高层次的视觉问题是至关重要的。
具体而言,这篇文章设计了一个视觉问答模型,将图像内容的内部表示与从知识库中提取的信息相结合,以回答广泛的基于图像的问题。它特别允许询问在图像本身不包含选择适当答案所需的信息的地方。最终的模型在几个主要的基准数据集上实现了图像语义生成和视觉问答的最佳结果。
▌简介
视觉问答(VQA)在计算机视觉方面提出了新的挑战,因为它们需要在两种不同形式的信息之间进行翻译。从这个意义上来说,这个问题类似于语言之间机器翻译的问题。在机器语言翻译方面,有一系列的结果表明,即使不开发更高层次的世界状态模型,也可以获得良好的性能。
自然语言是专门设计的,以便在人类之间传递信息,而图像则是复杂的。鉴于这两种信息形式之间的差异,受机器语言翻译启发的方法如此成功似乎令人惊讶。这些基于RNN的方法可直接从图像特征转换为文本,而无需设计高层语义特征,代表了关键的视觉语言(V2L)问题的当前研究状态,例如图像语义生成和视觉问答。
视觉问答(VQA)是比图像语义生成更具有挑战性。它与计算机视觉中的许多问题截然不同,因为在训练的时候无法预知要回答的问题是什么。然而,视觉问题回答是比图像语义生成更为复杂的问题,不仅仅是因为它需要访问图像中不存在的信息。这可能是常识,或关于图像主题的具体知识。例如,如下图所示,“一群人在沙滩上享受阳光灿烂的日子”,如果有人问“为什么有雨伞?”,为了回答这个问题,机器不仅要检测现场的“沙滩”,还必须知道“在晴朗的海滩上常常使用遮阳伞”。QA是一个更“完整的”任务,因为它需要超越单一子域的多模态知识

本文的贡献是两方面的。首先,提出了一个基于属性的CNN + RNN架构神经网络,可以应用于多个V2L问题。通过插入对人类有意义的场景属性的明确表示来实现这一点。每个语义属性对应于从训练图像描述中挖掘出的单词,并且表示关于图像内容的更高级的知识。针对每个属性对基于CNN的分类器进行训练,并且图像的属性可能性集合形成图像内容的高级表示。然后训练RNN,根据可能性生成图像的语义,或者回答问题。提出的基于属性的模型在图像语义生成的任务中产生比当前最先进的方法更好的性能。
基于提出的基于属性的V2L模型,本文的第二个贡献是引入一种将图像外部的知识(包括常识)合并到VQA过程中的方法。在这项工作中,本文将自动生成的图像描述与从外部知识库(KB)提取的信息融合,以提供有关图像的一般问题的答案。图像描述采用一组语义标注的形式,外部知识是从知识库中挖掘的基于文本的信息。
▌模型介绍
模型完成两方面工作,一是基于属性的图像语义生成,二是在生成的语义的基础上,引入额外的知识库,进行视觉问答。
基于属性的图像语义生成
1. 图像属性的生成
从标注的数据集中提取,256个被使用最多的词,除去15个在几乎所有标注中都有出现的词("a","on","of"等),相同语义的不管时态和单复数都看成是一个词
根据属性集,从每幅图像的标注中,提取出训练图像的属性
测试集图像的属性的生成:可以看成是一个多标签分类问题,建立每个属性与图像的区域的对应关系。 如一张图片上有“草地”“狗”“球”等,哪些地方是草地,哪些地方是狗等等。
图像属性的训练过程:可以由下面的结构图表示,它是一个VGGNet结构的CNN网络,先在ImageNet上预训练,得到单标签下的参数初值。然后,在MSCOCO数据集上,做一个多标签分类,分类数为属性集的大小,训练得到优化后的参数。在得到测试图像的属性时,先将测试图像分为不同的部分,然后经过得到该图片的属性。
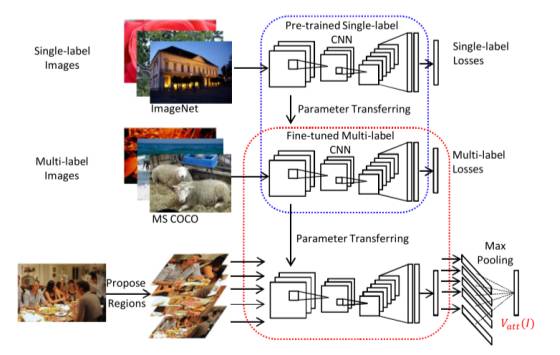
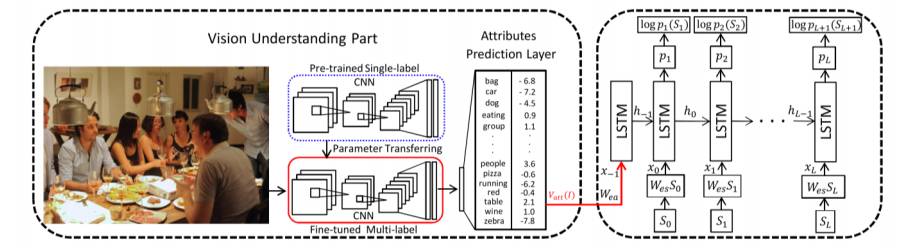
图像语义标注的生成
使用上一步生成的属性作为输入,用一个LSTM网络,最大化给定图片的正确描述的概率,训练得到语义标注的模型,结构图如下所示。
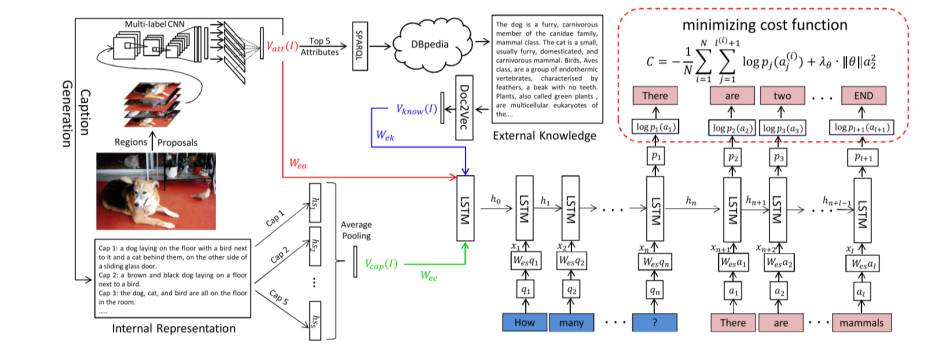
和知识库联系在一起的VQA
从文本知识库(DBpedia)中查出与图像的属性相关的信息。进一步的,可以选择从问题相关的属性进行查询。
使用Doc2Vec将从知识库中检索到的信息转换成等长特征表示。
将“属性”、“标注”、“知识库提供的信息”使用LSTM训练。
加入VQA之后的整体架构如下图所示
▌实验结果
下图展示了在视觉问答中本文提出的方法和现有最好方法的一部分比较结果。

▌结论
在本文中,首先研究了将中间属性预测层引入主要的CNN-LSTM框架的重要性,而这一点在以前的几乎所有工作中都被忽略了。本文实现了一个可以应用于图像语义生成任务的基于属性的模型。本文已经表明,在所有情况下,图像内容的明确表示都会提高V2L的性能。事实上,在提交本文时,提出的图像语义生成模型比几个语义生成数据集上的最新技术要好。 其次,在本文中,已经表明,可以扩展先进的基于RNN的VQA方法,以便包含回答关于图像的一般的开放式问题所需的大量信息。目前可用的知识库并不包含很多有利于这一过程的信息,但仍然可以用来显着提高需要外部知识(如“为什么”的问题)的性能。然而,提出的方法是非常普遍的,并且如果可用的话,它们将适用于更多的信息知识库。本文会进一步实施反映问题内容和图像内容的知识选择方案,以便更具体地提取相关信息。目前,提出的系统是三个VQA数据集的最新技术,并在VQA评估服务器上获得最佳结果。 进一步的工作包括产生反映问题和图像内容的知识库查询,以便提取更具体的相关信息。知识库本身也可以改进。例如,Open-IE提供了更多的常识性常识,比如“猫吃鱼”。这些知识将有助于回答高层次的问题。
参考链接:https://arxiv.org/abs/1603.02814
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!





