论文阅读笔记|决策树集成学习中的结构多样性
点击上方蓝字

关注我们
今天,FCS给大家分享一篇人工智能专栏论文——《Structural diversity for decision tree ensemble learning(决策树集成学习中的结构多样性)》的读者给我们带来的论文阅读笔记。如果您也同样对这篇论文感兴趣,或者也想把您阅读我们期刊论文的感受分享给更多的小伙伴,欢迎在文后留言或者与我们联系。
原文信息:
Structural diversity for decision tree ensemble learning
Frontiers of Computer Science,2018,12(3):560-570
Tao SUN, Zhi-Hua ZHOU

长按识别二维码,阅读文章详情
01
决策树与集成学习
决策树是一类著名的预测模型,被广泛应用于数据科学领域。它的优点包括可理解性,以及可以处理各种输入格式、错误和缺失值。它的缺点是不稳定,训练数据中的微小变化可以导致完全不同的决策树。此缺点可以通过决策树的集成学习缓解,与此同时,决策树的属性也决定其适合作为基学习器的选择。在集成学习中,基学习器的多样性度量是关键问题,但是现有方法仍存在一些不足之处。
02
集成学习的多样性度量
集成学习的一个关键因素是基学习器间的多样性,实践表明结合部分正确率高和部分正确率稍低的分类器往往比仅结合正确率高的分类器性能更好。但是如何度量集成多样性仍未解决,现有的多样性度量准则(例如$\kappa$-statistic、Disagreement和Entropy)并没有显现出与集成性能明确的关系。论文作者认为这是由于以往的多样性度量准则仅仅考虑了行为多样性,而忽略了结构多样性。举例说明, 针对任务:判断Y是否大于等于X,其中X与Y取值空间均为[0,10],给定如下图所示的八个实例数据,以下两个决策树的预测结果完全相同,但特征空间分区是完全不同的。仅考虑行为上的一致性而把它们当作等价的基学习器是不合理的。
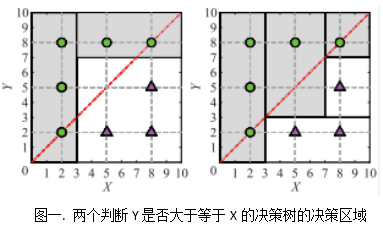
鉴于此,本文作者主张考虑结构多样性,作为行为多样性的补充。与行为多样性不同,结构多样性不依赖具体数据。学习器的结构蕴含了其固有属性,以决策树为例,更深的树通过更长的测试序列预测结果,直观上比浅层树更有“特性”,而浅层树更抽象更具“共性”,决策树的局部结构相似性跟特征空间分区相似性也是密切相关。因此,考虑结构多样性是有意义的。
03
TMD度量准则(Tree matching diversity)
基于对结构多样性的考虑,作者提出Tree matching diversity度量准则,一种易于实现和理解的方法。该方法目前不将叶子结点纳入考量,因为将叶子结点与非叶子节点直观比较有些困难,未来的工作可能考虑更好的利用这些标签信息。
TMD度量准则中有三种节点操作,分别为:
(1) 插入节点
(2) 删除节点
(3) 替换节点的相关特征
针对两个决策树,我们对其中之一进行尽量少的结点操作,使得两个决策树的结构变为一致。在这个过程中结点操作的次数,即为TMD准则中衡量结构多样性的量化数值,这个数值越大,二者结构差异性越大。针对多个决策树集成的整体多样性,度量方法为使决策树之间两两进行度量,得到的结点操作次数的平均值即为整个集成的量化数值,然后再取最大值进行正则化。
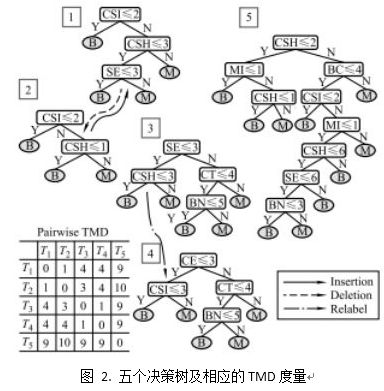
上方图例直观形象地描述了一组决策树集成的TMD应用样例。1号和2号决策树之间需要进行1次结点删除/增加的操作来进行匹配;3号和4号决策树之间需要进行一次结点属性替换来进行匹配;此四个决策树与5号决策树进行匹配均需要多次节点操作。由此两两进行匹配,得到图2左下角的记录表格,可用其中最大值10进行正则化。
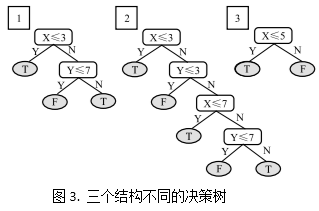
反过来再看图1中的样例,两个决策树的结构分别对应上图的1与2。假设我们已经存在决策树1和3,需要再从1与2中挑选一个决策树用于集成。已有的多样性度量准则基于行为多样性无法区分1与2,而TMD度量准则基于结构多样性建议选择决策树2。但是,在真正实践中,分类器的预测结果往往不尽相同,所以为了得到好的集成效果,我们应该兼顾结构和行为多样性。
04
实证研究
为了研究结构多样性的实用性,作者针对不同的选择性集成方法,将TMD度量准则与不同多样性度量准则结合实验,用以对比单独使用其他多样性度量准则对集成的效果。
实验涉及到的三种选择性集成方法分别基于排序、聚类和优化,三种已知多样性度量方法分别为$\kappa$-statistic、Disagreement和Entropy。以不同的选择性集成方法作为平台,使用10个二分类数据集和10个多分类数据集,将TMD度量结合不同的多样性度量进行实验,以对比TMD度量带来的改变。
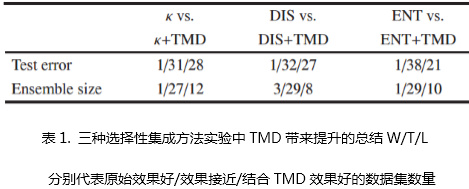
实验结果表明,总体而言,采用TMD度量能够得到更好的甚至显著性的提升,且在20个数据集上都有很好的体现。将三种选择性集成方法的实验结果总结在上表中,我们发现,相比原始的行为多样性度量,结合TMD的度量显著地减少测试误差和集成大小。除此之外,数据表示,将TMD与其他多样性度量结合亦比单独使用TMD效果更好。这些实证结论证明同时考虑行为和结构多样性是有效的。
为了继续探究行为和结构多样性结合使用的优势,作者利用随机子空间思想训练了100个J48决策树,针对每个决策树仅仅随机选取一半特征用于分类,以构建比bagging更具多样性的结构。再次进行上述实验后发现,结合TMD度量依然可以对实验效果有明显的提升。
05
结论
针对集成方法,本文作者提倡除行为多样性以外考虑结构多样性,进而为决策树的集成提出了tree matching diversity度量准则,通过选择性集成方法进行实验,证明了同时考虑结构多样性和行为多样性的必要性。此度量方法亦可以用于其他决策树集成学习方法。本文仅仅讨论了决策树,为其他各式各样的基学习器设计结构多样性将是有趣的研究课题,甚至对于决策树也有更多的简单有效的结构多样性定义有待探索。另外,如何一起利用行为多样性和结构多样性也是未来一个值得研究的方向。
注:本文为该读者的阅读笔记,未经原论文作者和FCS期刊审读。仅供广大读者参考。

了解原论文内容,请点击下方链接:
决策树集成学习中的结构多样性 2018,12(3):560-570
Frontiers of Computer Science


长按二维码关注Frontiers of Computer Science公众号


