从LeNet-5到DenseNet

本文作者山隹木又,本文首发于作者的知乎专栏《サイ桑的炼丹炉》, AI研习社获其授权发布。
卷积、池化等操作不再赘述,总结一下从LeNet到DenseNet的发展历程。
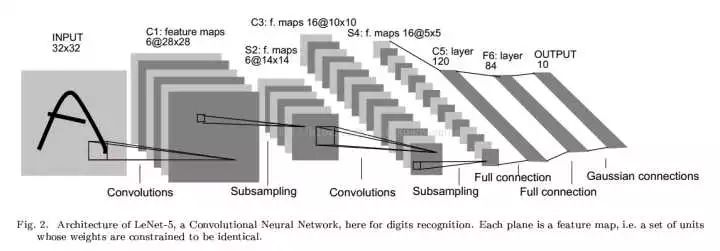
图1. LeNet-5 网络结构
一、LeNet-5
卷积神经网络的开山之作,麻雀虽小五脏俱全,卷积层、池化层、全链接层一直沿用至今。
这个网络结构非常简单,如图1所示。
层数很浅,并且kernel大小单一,C1、C3、C5三个卷积层使用的kernel大小全部都是5×5,不过在我个人看来,这个kernel的大小是经过了无数次实验得来的最优结果,并且有一定的特征提取能力,才能如此经得起时间的考验。C5的feature map大小为1×1是因为,S4的feature map大小为5×5而kernel大小与其相同,所以卷积的结果大小是 1×1 。
S2和S4两个池化层使用的window大小均为2×2,这里的池化有两种,一个是平均池化(在window内对所有数值求平均值),一个是最大池化(取window内的最大值)。
F6是一个有84个神经元的全连接层,猜测这个神经元数量也是实验所得较优的情况得来。
LeNet有一个很有趣的地方,就是S2层与C3层的连接方式。在原文里,这个方式称为“Locally Connect”,学习了CNN很久之后的一天,在回顾CNN原理的时候发现了这种神奇的连接方式:
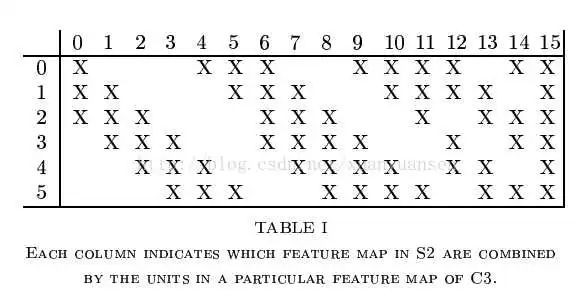
图2. S2与C3层的局部连接
规定左上角为(0,0),右下角为(15,5),那么在(n,m)位置的“X”表示S2层的第m个feature map与C3层的第n个kernel进行卷积操作。例如说,C3层的第0个kernel只与S2层的前三个feature map有连接,与其余三个feature map是没有连接的;C3层的第15个kernel与S2层的所有feature map都有连接。这难道不就是ShuffleNet?
顺便分享一个很好的LeNet可视化项目:LeNet-5可视化(http://t.cn/RbmYJ5b)
二、AlexNet
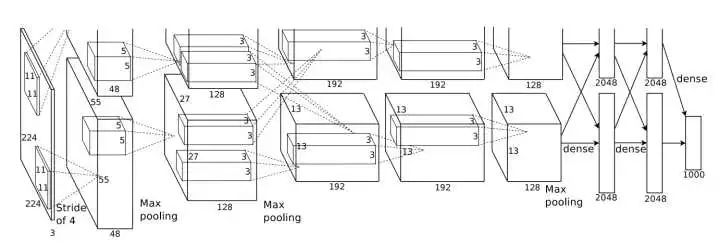
图3. AlexNet结构图
AlexNet在2012年的ImageNet竞赛上以,比以往最低错误率低10个百分点的成绩夺冠。在介绍该网络的论文ImageNet Classification with Deep Convolutional Neural Networks(http://t.cn/RjKHKs0)中有很多干货:
一)、网络结构
网络一共有8层可学习层——5层卷积层和3层全链接层。网络的输入为150,528(224x224x3)维,各层的神经元数量为:
253,440=>186,624=>64,896=>64,896=>43,264=>4096=>4096=>1000(ImageNet有1000个类)
举个例子,计算一个186,624是怎么来的(如果有人会计算253,440,教えてください!):
27x27x256=186,624
举个例子,怎么计算feature map尺寸:
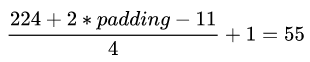
网络与之前的网络相比引入了以下新特征:
1、ReLU非线性单元:
激活函数的作用是为了引入非线性,这么说很抽象,但是在没有激活函数的时候,无论有多少层MLP,得到的网络输出依然是关于输入的线性函数,如下图所示:
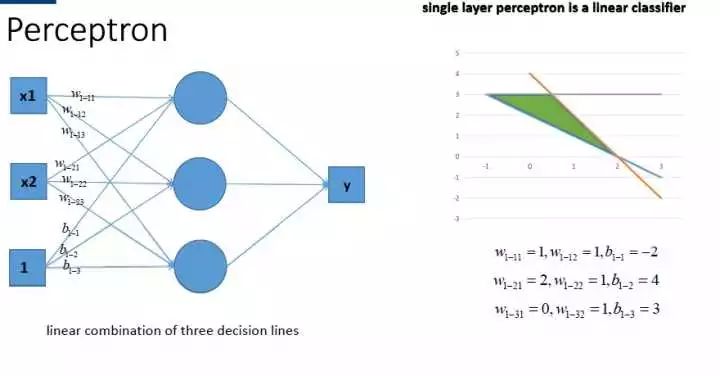
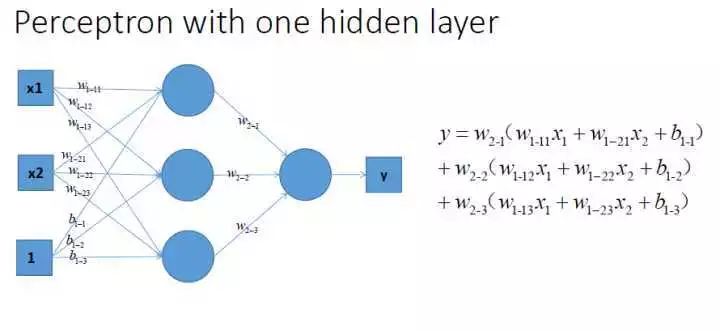
传统的激活函数一般是sigmoid和tanh两种饱和非线性函数,就训练时间来说,使用这些饱和的非线性函数会比使用非饱和的非线性函数ReLU,模型收敛需要更长的时间。而对于大型的数据集来说,更快的学习过程意味着可以节省更多的时间。除此之外,ReLU也引入了一定的稀疏性,在特征表示的范畴内,数据有一定的稀疏性,也就是说,有一部分的数据其实是冗余的。通过引入ReLU,可以模拟这种稀疏性,以最大近似的方式来保留数据的特征。
2、多GPU训练
在论文给出的图3中我们可以看到,两个网络是并行的,但是这并不意味着AlexNet一定是并行结构的,这张图只是告诉我们,将AlexNet部署在多GPU上时的工作方式(为什么要部署在多GPU上?因为当时的GTX580只有3GB的显存,不足以容纳该网络最大的模型):每个GPU上并行地、分别地运行AlexNet的一部分(例如将4096个神经元的全连接层拆分为两个并行的2048个神经元的全连接层,第一个卷积层有96个feature map而在一块GPU上只有48个feature map等),两块GPU只在特定的层上有交互。
3、局部响应归一化层(Local Response Normalization Layer)
LRN层只存在于第一层卷积层和第二层卷积层的激活函数后面,引入这一层的主要目的,主要是为了防止过拟合,增加模型的泛化能力。具体方法是在某一确定位置(x,y)将前后各2/n个feature map求和作为下一层的输入。但是存在争论,说LRN Layer其实并没有什么效果,在这里不讨论。
4、Overlapping Pooling
池化操作提取的是一小部分的代表性特征,减少冗余信息。传统的卷积层中,相邻的池化单元是不重叠的,具体点说就是,对于一个8x8的feature map,如果池化的stride=2、window的size=2,我们得到的就是传统的池化操作。如果stride=2,window的size=3,那么在进行池化的过程中,相邻的池化window之间会有重叠的部分,这种池化就是overlapping pooling。论文也指出,这种池化只能“稍微”减轻过拟合。
二)、减轻过拟合
1、数据增强的两种方式:
1)、平移、翻转、对称等:
从256x256的图片中随机截取224x224的部分出来:
训练时,取出所有的patch以及它们的水平对称结果,这种操作将整个数据集放大了2048倍,为什么是2048倍呢?因为在vertical和horizontal两个方向上,各有32个位置可以进行crop,也就是32x32 个patches。还有它们的horizontal reflection(水平对称),也就是再翻一番,所以,一张图片就可以获得2048个patches。
测试时,取四个角以及中心共五处的patch,加以对这些patch进行水平对称得到的patch来测试网络(一共是10个patches),也就是在预测时将10个patches逐一计算出softmax后的结果,再对所有的预测结果取平均,得到真正的分类。
2)、改变RGB通道的强度:
也就是,对每个RGB图片的像素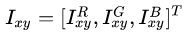
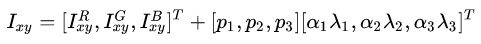
这里的p和λ是RGB值3x3协方差矩阵的特征向量和特征值。α是均值为1标准差为0.1的高斯随机变量。
这么做的原因是利用了自然图片的一条重要性质:物体的鉴别特征并不会因为图片强度和颜色的变化而变化,也就是说,一定程度上改变图片的对比度、亮度、物体的颜色,并不会影响我们对物体的识别。在ImageNet上使用这个方法,降低了1%的top-1 error。
2、Dropout(自己的总结):
1)、Dropout是一种Bagging的近似:
Bagging定义k个不同的模型,从training set采样出k个不同的数据集,在第i个模型上用第i个数据集进行训练,最后综合k个模型的结果,获得最终的模型。但是需要的空间、时间都很大,在DNN中并不现实。
Dropout的目的是在指数级子网络的深度神经网络中近似Bagging。也就是说,在训练时,每次Dropout后,训练的网络是整个深度神经网络的其中一个子网络。在测试时,将dropout层取消,这样得到的前向传播结果其实就是若干个子网络前向传播综合结果的一种近似。
3、Learning rate decay:
随着训练的进行,逐渐减小学习率。
三、VGGNet(deep)
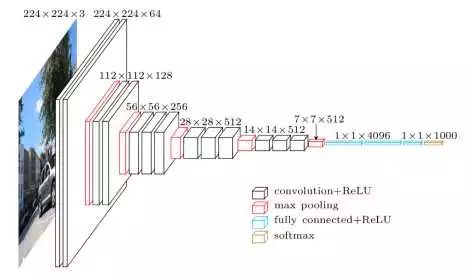
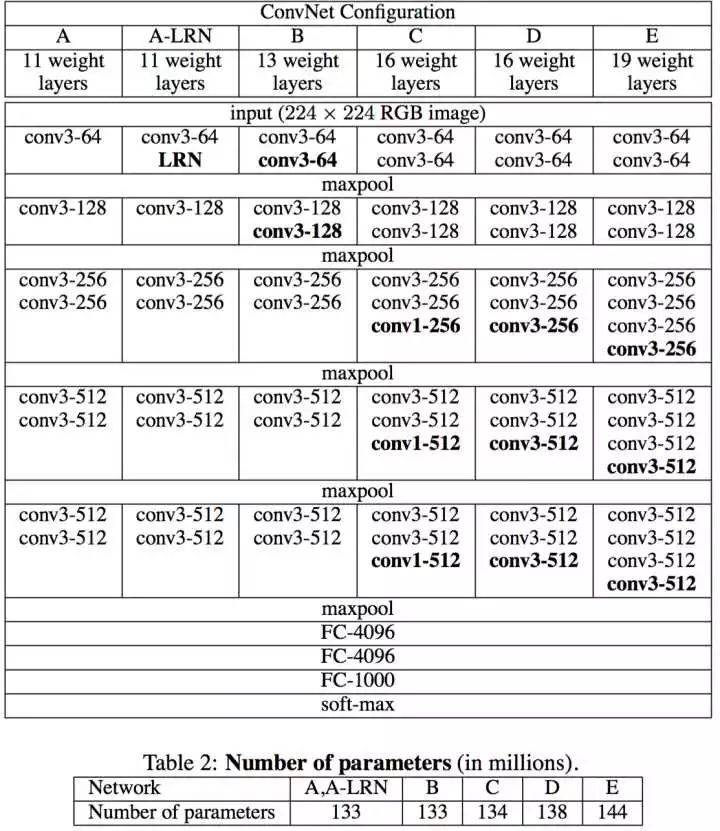
VGGNet与AlexNet很相似,都是卷积池化-卷积池化-...-全连接的套路,不同的是kernel大小,卷积stride,网络深度。
VGGNet将小卷积核带入人们的视线,分析一下大小卷积核的区别与优劣:
在上面提到的AlexNet中第一个卷积层使用的kernel大小为11x11,stride为4,C3和C5层中使用的都是5x5的卷积核;而出现在VGGNet中大多数的卷积核都是大小为3x3,stride为1的。
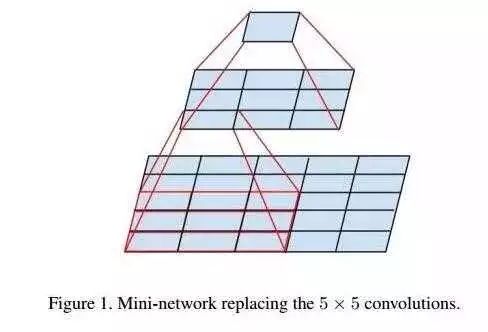
直观上我们会觉得大的卷积核更好,因为它可以提取到更大区域内的信息,但是实际上,大卷积核可以用多个小卷积核进行代替。例如,一个5x5的卷积核就可以用两个串联的3x3卷积核来代替,一个7x7的卷积核就可以用三个串联的3x3卷积核来代替。这样的替代方式有两点好处:
1、减少了参数个数:
两个串联的小卷积核需要3x3x2=18个参数,一个5x5的卷积核则有25个参数。
三个串联的小卷积核需要3x3x3=27个参数,一个7x7的卷积核则有49个参数。
大大减少了参数的数量。
2、引入了更多的非线性:
多少个串联的小卷积核就对应着多少次激活(activation)的过程,而一个大的卷积核就只有一次激活的过程。引入了更多的非线性变换,也就意味着模型的表达能力会更强,可以去拟合更高维的分布。
值得一提的是,VGGNet结构的C里面还用到了1x1的卷积核。但是这里对这种卷积核的使用并不是像Inception里面拿来对通道进行整合,模拟升维和降维,这里并没有改变通道数,所以可以理解为是进一步的引入非线性。
VGGNet相比于AlexNet层数更深,参数更多,但是却可以更快的收敛,在网上被解释为“更深的网络层数和更小的卷积核起到了隐式的正则化效果”,这句话读来让人一头雾水。我自己的解读是:更小的卷积和步长核使得在反向传播的过程中,kernel所需要考虑的loss来自于更多次的卷积,来自于整张feature map的更多patch,并且kernel自身需要更新的参数也变少了,这样梯度下降更新的方向就更加趋向于极值点,起到了一定的正则化作用;而更深的网络代表的是网络更强的表达能力,但是深的网络会引起梯度爆炸或者梯度消失,不知道网络的深度应该怎样与正则化联系起来,欢迎讨论。
原论文中还提到了一种新的测试方式,称作multi-scale testing,数据增强中也使用了multi-scale方法,不多介绍。
总地来说,VGGNet的出现让我们知道CNN的潜力无穷,并且越深的网络在分类问题上表现出来的性能越好,并不是越大的卷积核就越好,也不是越小的就越好,就VGGNet来看,3x3卷积核是最合理的。
四、GoogLeNet (Inception v1~v4, deeper)
一)、Inception v1
有了VGG的铺垫,人们开始意识到,为了更好的网络性能,那有一条途径就是加深网络的深度和宽度,但是太过于复杂,参数过多的模型就会使得模型在不够复杂的数据上倾向于过拟合,并且过多的参数意味着需要更多的算力,也就是需要更多的时间和更多的钱。
GoogLeNet的核心思想是:将全连接,甚至卷积中的局部连接,全部替换为稀疏连接。
1、生物神经系统中的连接是稀疏的;
2、如果一个数据集的概率分布可以由一个很大、很稀疏的深度神经网络表示时,那么通过,分析最后一层激活值的相关统计和对输出高度相关的神经元进行聚类,可以逐层地构建出一个最优网络拓扑结构。也就是说,一个深度稀疏网络可以被逐层简化,并且因为保留了网络的统计性质,其表达能力也没有被明显减弱。
但是由于计算机硬件计算稀疏数据的低效性,现在需要提出的是一种,既能保持网络结构的稀疏性,又能利用密集矩阵计算的高效性的方法。大量研究表明,可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,Inception应运而生。
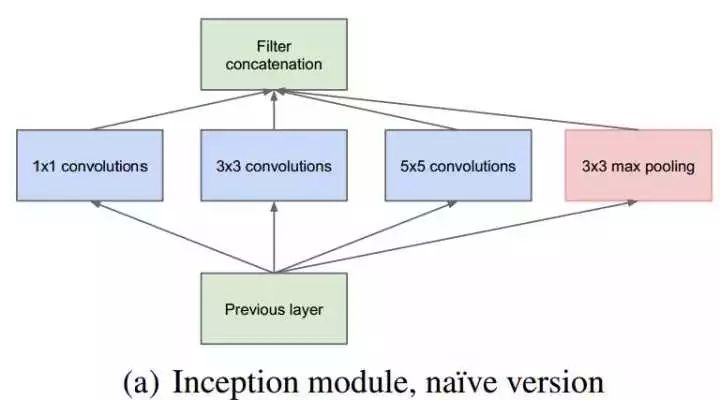
上图结构是Inception的naive版本基本单元,为什么由这种模型stack起来的网络既保持了网络结构的稀疏性,又利用了密集矩阵计算的高效性?
稀疏性是指卷积运算的使用,因为卷积通常对应着一个非常稀疏的矩阵(一个几乎所有元素都为零的矩阵),怎么理解卷积的稀疏性呢?在传统的神经网络中,使用矩阵乘法来建立输入与输出之间的连接关系,其中参数矩阵中的每一个单独的参数都描述了一个输入单元和输出单元的交互,我们使用的kernel的尺寸是远远小于图片的尺寸的,在feature map中,一个神经元只受到少数输入单元的影响,这是不同于密集的全连接的,称之为卷积的稀疏性。
密集矩阵计算依然是存在的,Inception模块中的四个分支可以看作是较为稀疏的部分,但是拼接之后又成为一个大的密集矩阵。
这种基本模块使用了3种不同的卷积核,那么提取到的应该是3种不同尺度的特征,既有较为宏观的特征又有较为微观的特征,增加了特征的多样性。池化层在我的理解就是保留较为原始的输入信息。在模块的输出端将提取到的各种特征在channel维度上进行拼接,得到多尺度的特征。
但是这种naive的版本在进行5x5卷积的时候依然会消耗大量的算力,举个例子分析:
如果previous layer输出的feature map为100x100x128,假设naive版本的5x5卷积核共有256个,需要的参数就为128x5x5x256个。假设,在进行5x5的卷积之前,先进行一次1x1的卷积,那么参数量可以大大降低。假设1x1的卷积核共有32个,5x5的卷积核依然有256个,那么需要的参数量为 128x1x1x32+32x5x5x256,为前一种方法的0.255倍。注意到,这里的1x1卷积是被拿来进行channel维度的整合(降维),而在之前VGG中提到的只是为了引入非线性,毫无疑问,这里不仅降低了计算量,并且增加了非线性,增强了网络的表达能力,是一举两得的事情。
改进版的Inception module如下:
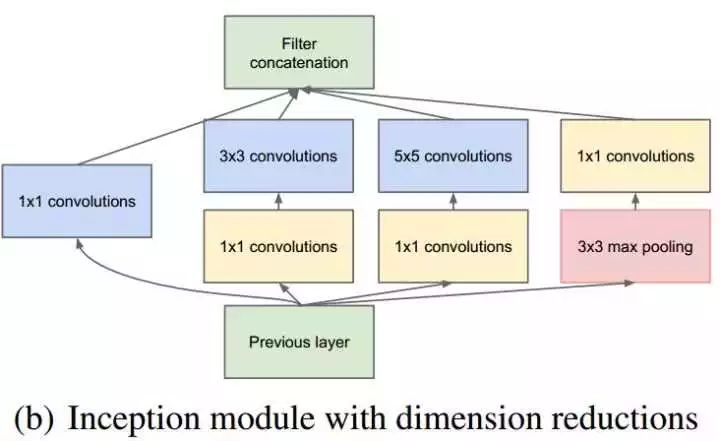
GoogLeNet(Inception-V1)的结构图如下:
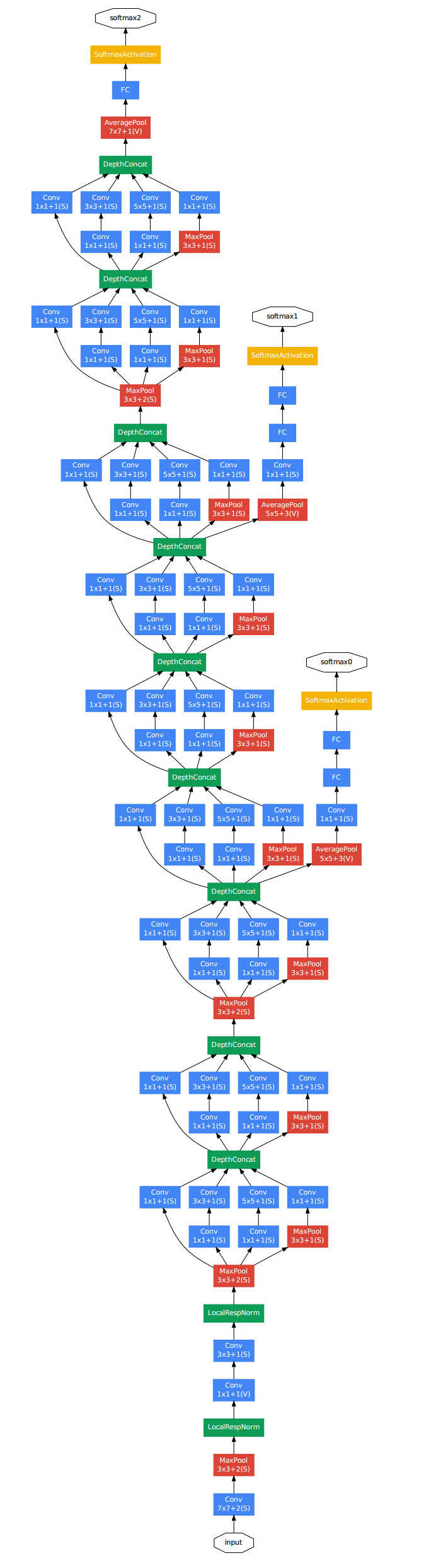
可以看到,GoogLeNet使用的是模块化堆积的方法。
论文中说:模型在分类器之前使用了平均池化来替代全连接层的idea来自于NIN,在最后加入一层全连接层的为了使得模型在其他数据集上进行finetune时更方便。作者们发现将全连接层替换为平均池化层后,top-1准确率(accuracy)上升了0.6%,虽然移除了全连接层,但是dropout依然很重要。
值得注意的是,网络中有三个softmax,这是为了减轻在深层网络反向传播时梯度消失的影响,也就是说,整个网络的loss是由三个softmax共同组成的,这样在反向传播的时候,即使最后一个softmax传播回来的梯度消失了,还有前两个softmax传播回来的梯度进行辅助。在对网络进行测试的时候,这两个额外的softmax将会被拿掉。这样不仅仅减轻了梯度消失的影响,而且加速了网络的收敛。
整个Inception-v1的参数设置如图:
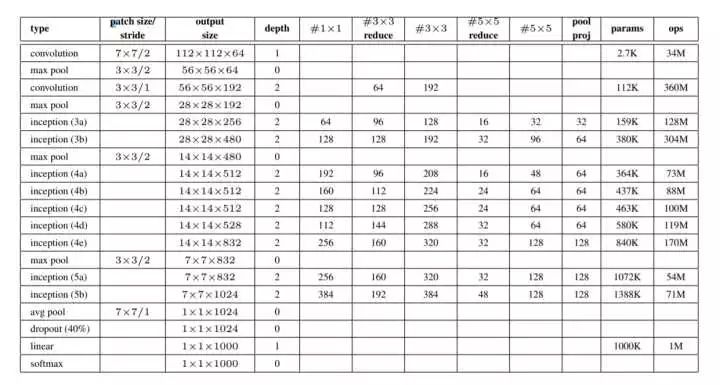
可以看到,随着网络变深,卷积核的个数也在不断增加,这是因为越往后,网络提取到的特征越抽象(例如,人之于眼睛鼻子嘴巴是抽象的),而且每个抽象特征需要的卷积核尺寸也相应大,所以随着层数变深,较大卷积核的数量应当随之提升。
二)、Inception v2 & v3
在具体介绍与v1版本的区别之前我想先直观地说一下batch normalization,因为在v3版本中使用了BN。这是我自己在ipad上记的笔记:


Batch normalization解决的是一个Internal covariate shift问题,论文中将这个问题定义为在训练过程中由于网络参数的改变而引起的网络激活分布的改变。笔记中最后一点关于BN应该放在何处的问题,近段时间也有一些争议,比如这个链接里做的对比BN-before or after ReLU?(http://t.cn/RjKgxNM)结果是将BN放在ReLU后面会有更好的效果。求指点!
那么v2版本到底在哪里进行了改进呢?
首先,参考了前面提到的VGGNet用两个串联的3x3卷积替代一个5x5卷积的方法。
其次,引入非对称卷积。例如,将3x1的卷积和1x3的卷积串联起来,与直接进行3x3卷积的结果是等价的。这种卷积方式大大降低了参数量,从nxn降到了2xn,所以当n越大,降低得越多。但是也并不是适用于所有的卷积方式,论文说明,在实践中在feature map为12x12~20x20时效果较好,也就是在较深层使用时效果好,浅层不太行,并且使用7x1和1x7卷积的串联可以得到很好的效果。有兴趣可以自己查看论文:Rethinking the Inception Architecture for Computer Vision(http://t.cn/RjKevpW)。
文章在不同深度的网络使用了不同类型的inception module,三种模块如下图所示:
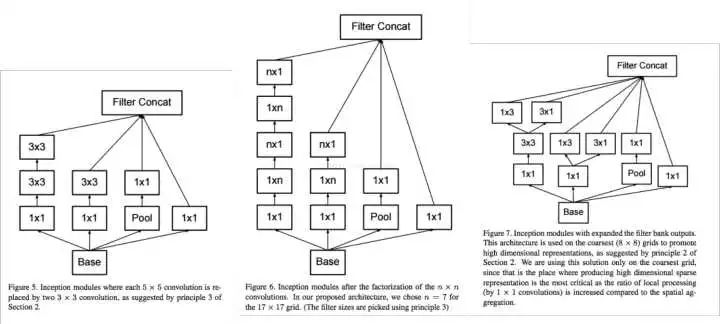
整个网络的结构如图所示:
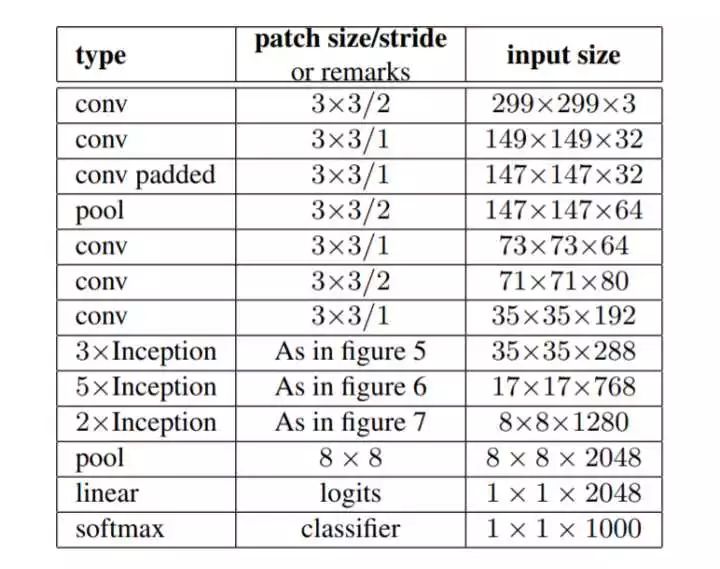
网络在很深的层次才使用了含有非对称卷积的Inception module,比如在8x8这种分辨率最低的feature map才使用了第三种Inception module,其原因是,这些最粗糙的网格,最靠近网络的末端,对于这些深层的网络来说,最关键的一点是要产生高维的稀疏表示,所以这些深层更需要的是局部处理(比如1x1的卷积得出的是最稀疏的结果),第三种Inception module是这三种模型中可以得到最稀疏结果的模型。
在ImageNet上的测试结果为:
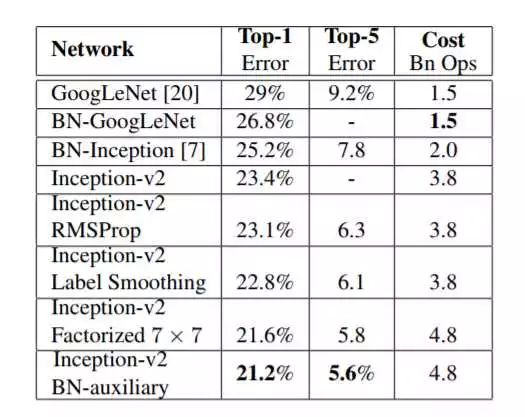
Inception-v2是最原汁原味的版本,下面的Inception-v2 RMSProp、Inception-v2 Label Smoothing、Inception-v2 Factorized7x7、Inception-v2 BN-auxiliary是经过了一系列改进后的结果,具体操作请参考论文。
"Inception-v3 = Inception-v2 + Factorization + Batch Normalization"
三)、Inception-v4 &Inception-ResNet-v2(建议先看第五部分ResNet):
我们先看Inception-ResNet-v2:
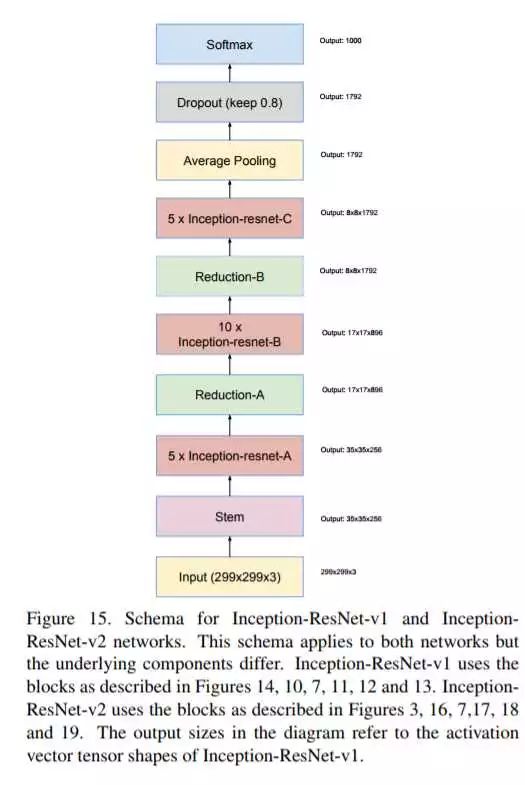
网络的结构如上图,下面我们看看如何与ResNet结合(主要体现在Inception-resnet-A\B\C模块里):
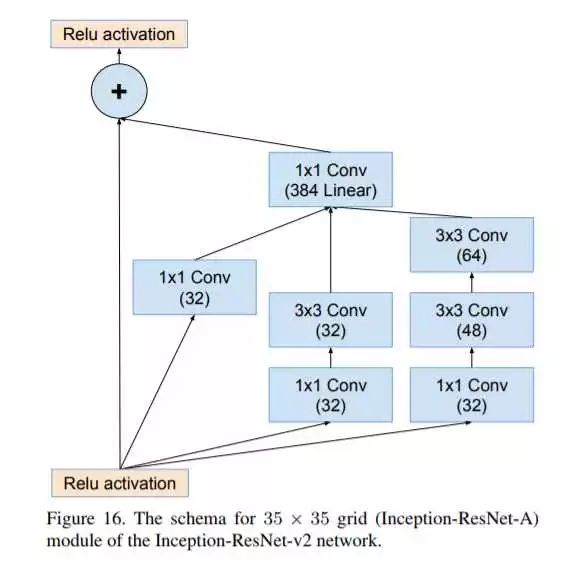
Inception-resnet-A
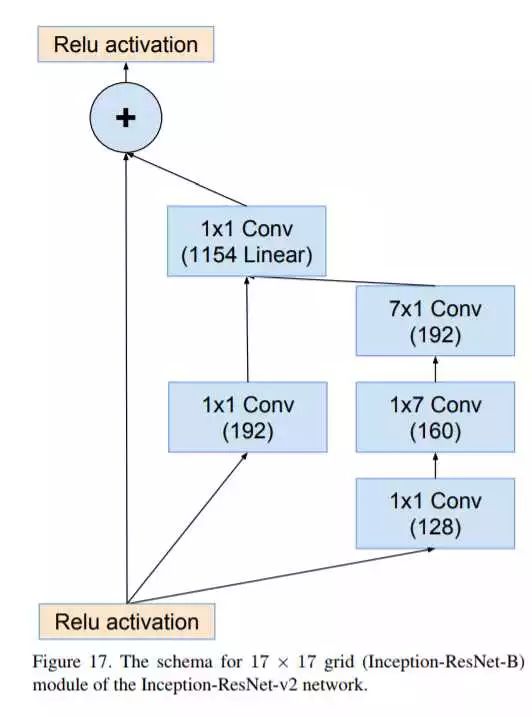
Inception-resnet-B
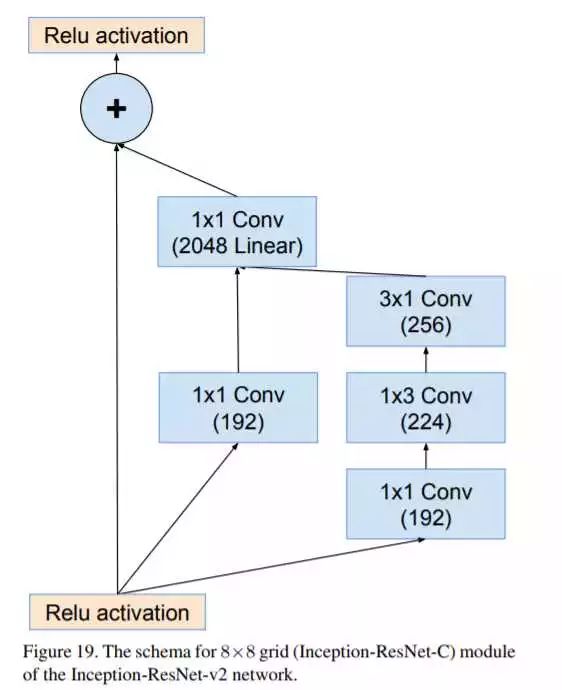
Inception-resnet-C
可见,对每个Inception-resnet模块而言,综合了之前版本的Inception模块版本和ResNet的残差单元。除此之外,Google还优化了一个性能与Inception-ResNet-v2相仿的Inception-v4版本,不多讨论,可以自行看论文,对每个Inception模块的优化情况。
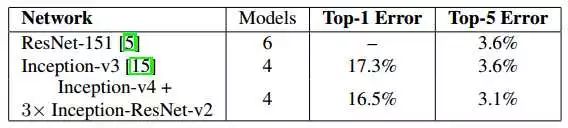
下面是模型在ImageNet数据集上的测试结果:
单模型:
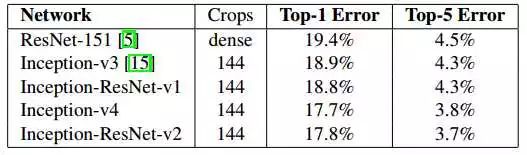
组合模型:
五、ResNet
首先,我想以拙见说一说什么是残差:
残差的定义是,观测值与估计值之间的差距,显然残差网络里的残差与这个定义不同。
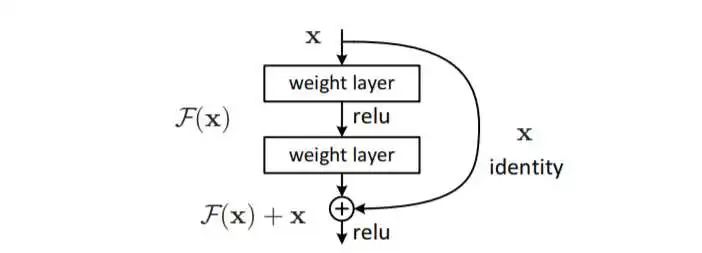
假设我们有一个identity,用x表示。同时我们有一种想要的映射H(x),并且希望可以由两层weight layer的传播来得到这种映射。那这样我们就得到了一个神经网络。但是,如果我们定义残差为F(x)=H(x)-x,并且希望用两层的weight layer的传播来拟合残差,那么我们想要得到的理想映射H(x)=F(x)+x。这就是残差网络的基本理念,网络学习的是去拟合残差,而不是直接拟合输入和输出直接的映射。
引入残差单元:
接下来放几张作者在ICML2016上解读残差网络的PPT:
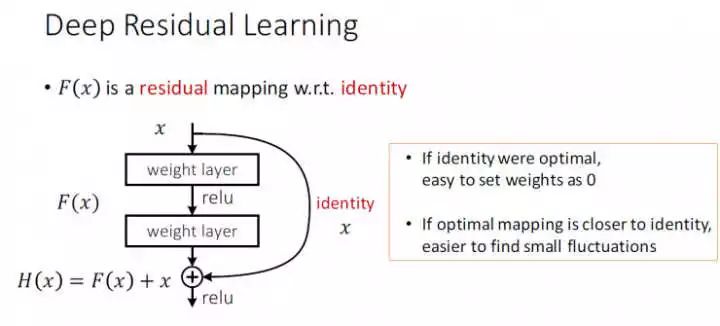
也就是说,如果identity是最优的,它就是我们想要的理想映射,那么我们可以直接将F(x)的参数全部置零;如果identity和H(x)很相近,那么我们就可以通过学习残差来修正这种差别。这个箭头称作shortcut connection,idea来自于highway network的skip-connection。

残差网络的设计理念是:保持简洁+VGG-SYTLE+就是要深
分享一个翻译版本的论文:中文版残差网络论文(http://t.cn/RC0XKlr)
我又要放自己的笔记了,这是一篇分析为啥深度残差网络性能好的论文,并且提出了一种新的残差单元,Identity Mappings in Deep Residual Networks(http://t.cn/Rj9ARVM):
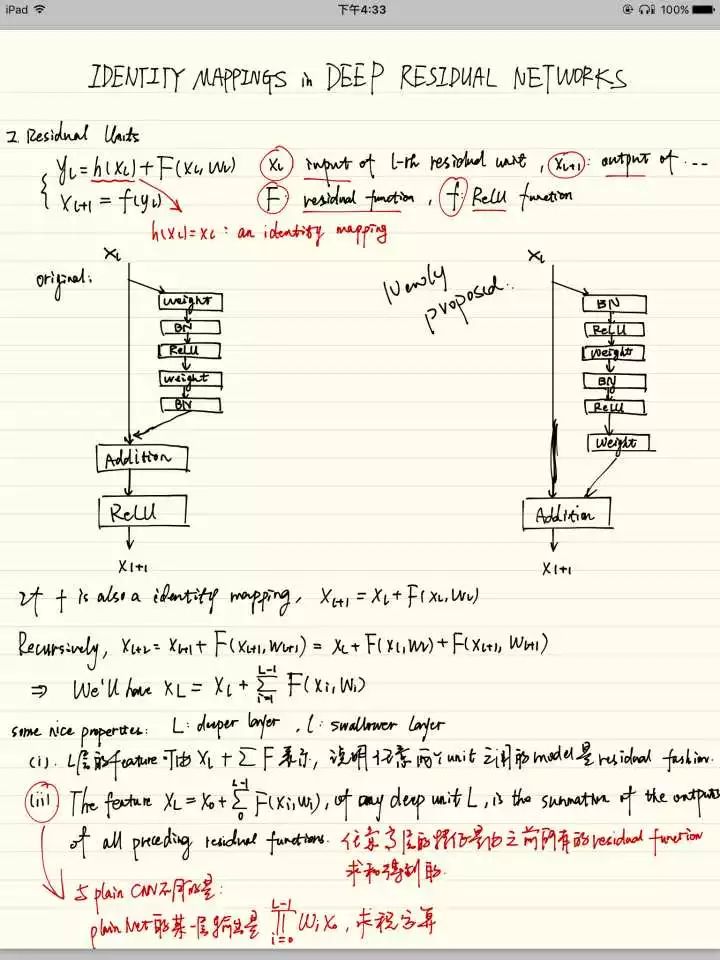

这里分析了为什么深度残差网络却没有因为网络加深而带来的梯度消失或者题都爆炸问题,因为残差结构的特殊性,在由loss对输入求导的时候,导数项会被分解为两个,而有一个直接对输入的导数项并不会消失,所以梯度一直存在。

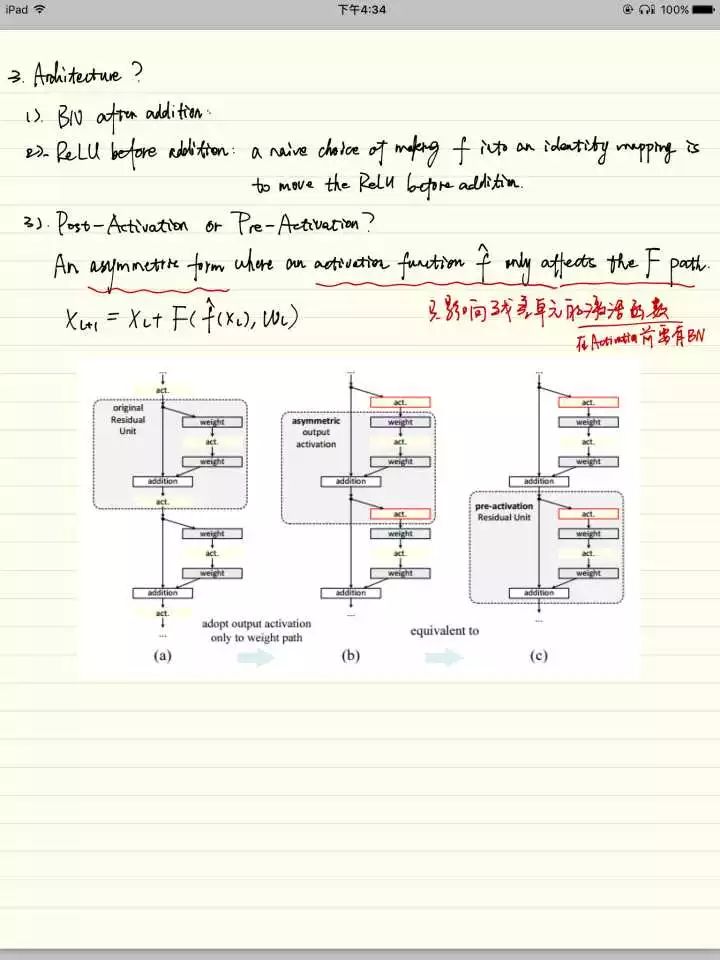
因为之前提到的没有shorcut connection的网络里,考虑activation的位置没有什么意义。但是在有分支的残差网络里,因为存在着addition,那么和identity相加的值应该是激活前还是激活后的就值得考虑。这里比较了各种残差单元的优劣,也就是说,将identity先进行BN,再激活,再传入weight layer进行计算的效果是最优的。
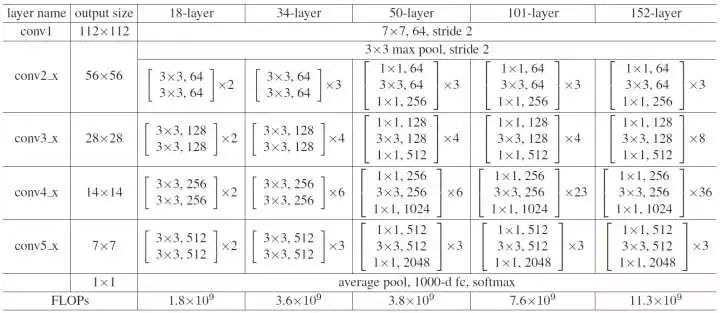
ResNet可以逐渐加深,常用的有ResNet-50、ResNet-101、ResNet-152。像ResNet-1001这么庞大的model一般的GPU难以加载。这些模型的参数如图:
六、DenseNet
首先介绍什么是Dense Block:
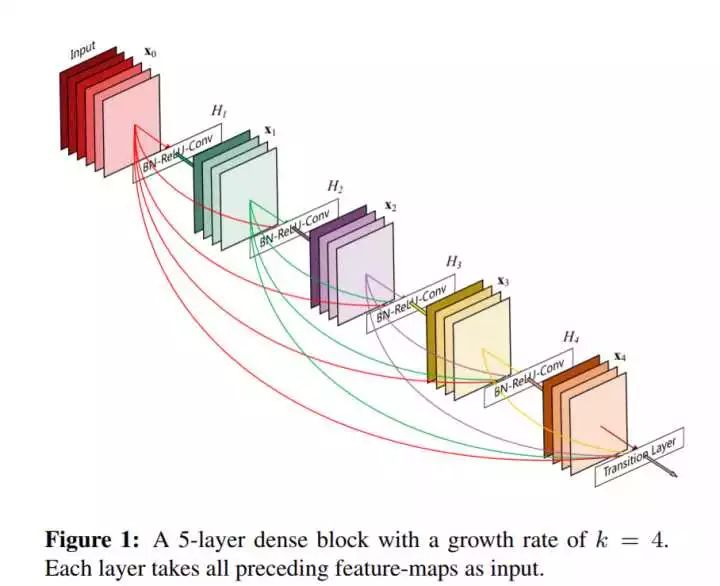
如图所示的结构就叫作Dense Block,它包括输入层在内共有5层,H是BN+ReLU+3x3Conv的操作,并不改变feature map的大小。对于每一层来说,前面所有层的feature map都被直接拿来作为这一层的输入。growth rate就是除了输入层之外,每一层feature map的个数。它的目的是,使得block中的任意两层都能够直接”沟通“。
其实在Dense Block输出的地方还有一个bottleneck layer,在bottleneck layer中的操作是一个1x1的卷积,卷积核共有4k个,降低channel维度,也就是减少了模型的参数。
在transition layer中有进一步压缩的操作称为compression,减少百分之θ的feature map数量,论文中使用的θ=0.5。
然后介绍DenseNet的模型:
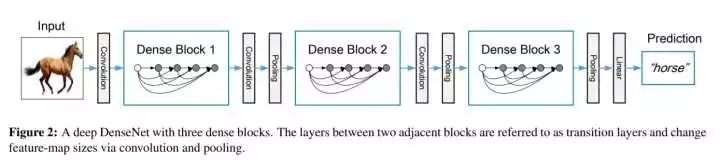
也就是说,DenseNet其实是由若干个Dense Block串联起来而得到的,在每个Dense Block之间有一个Convolution+Pooling的操作,也就是图1中的transition layer。transition layer存在的意义是实现池化,作者在论文中承认了pooling的重要性。
分析一下为什么会从ResNet发展到DenseNet:
借用论文里的话,ResNet直接通过"Summation"操作将特征加起来,一定程度上阻碍(impede)了网络中的信息流。DenseNet通过连接(concatenate)操作来结合feature map,并且每一层都与其他层有关系,都有”沟通“,这种方式使得信息流最大化。其实DenseNet中的dense connectivity就是一种升级版的shortcut connection,提升了网络的鲁棒性并且加快了学习速度。
DenseNet的各种模型结构如图:
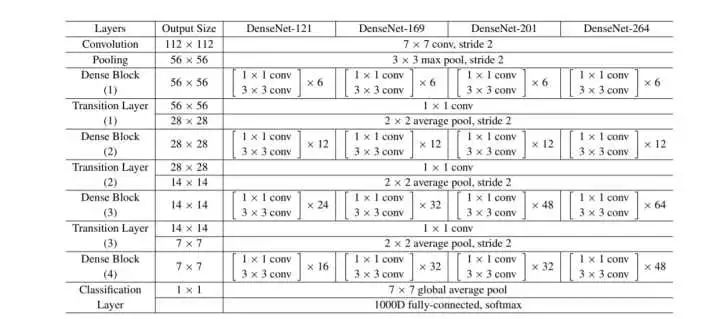
图中的每个conv代表的都是BN+ReLU+Conv的一连贯操作。
(完)

不要等到算法出现accuracy不好、
loss很高、模型overfitting时,
才后悔没有好好掌握基础数学理论。
走稳机器学习第一步,夯实数学基础!
“线性代数及矩阵论、概率论与统计、凸优化”
3大数学基础课程,火热团购中!
扫码参团

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
为什么ResNet和DenseNet可以这么深?
▼▼▼