不仅搞定“梯度消失”,还让CNN更具泛化性:港科大开源深度神经网络训练新方法
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

paper: https://arxiv.org/abs/2003.10739
code: https://github.com/d-li14/DHM
该文是港科大李铎、陈启峰提出的一种优化模型训练、提升模型泛化性能与模型精度的方法,相比之前Deeply-Supervised Networks方式,所提方法可以进一步提升模型的性能。值得一读。
Abstract
时间见证了深度神经网络的深度的迅速提升(自LeNet的5层到ResNet的上千层),但尾端监督的训练方式仍是当前主流方法。之前有学者提出采用深度监督(Deeply-supervised,DSN)方式缓解深度网络的训练难度问题,但是它不可避免的会影响深度网络的分层特征表达能力,同时会导致前后矛盾的优化目标。
作者提出一种动态分层模仿机制(Dynamic Hierarchical Mimicking,一种广义特征学习机制)加速CNN训练同时使其具有更强的泛化性能。所提方法部分受DSN启发,对给定神经网络的中间特征进行巧妙的设置边界分支(side branches)。每个分支可以动态的出现在主分支的特定位置,它不仅可以保留骨干网络的特征表达能力,同时还可以研其通路产生更多样性的特征表达。与此同时,作者提出采用概率预测匹配损失进一步提升多分支的多级交互影响,它可以确保优化过程的鲁棒性,同时具有更好的泛化性能。
最后作者在分类与实例识别任务上验证了所提方法的性能,均可取得一致性的性能提升。
Method
该部分内容首先简单介绍一下深度监督及存在的问题,最后给出所提方法。由于该部分内容公式较多,文字较多,故这里仅进行粗略的介绍,在后面对进行一些个人理解分析。
Analysis of Deep Supervision
对于深度网络而言,其优化目标可以描述为:
其中 表示待优化的整体损失函数,而 表示针对参数添加的一些正则化处理。对于图像分类而言,上述损失函数可以定义为:
另,由于正则项仅与参数有关,而与网络结构无关,故在后续介绍中对上述公式进行简化,得到:
一般而言,在图像分类任务中,往往仅在网络的head后进行损失计算。这种处理方式对于比较浅的网络而言并没有什么问题,但是对于极深网络而言则会由于梯度反向传播过程中的“梯度消失”问题导致网络收敛缓慢或者不收敛或收敛到局部最优。
针对上述现象,Deeply-Supervised Nets提出了多级监督方式进行训练。该训练方式的优化目标函数可以描述为:
其中 表示额外监督信息的损失。注:GoogLeNet一文采用的训练方式就是它的一种特例。
通过上述上述训练方式,中间层不仅可以从顶层损失获取梯度信息,还可以从分支损失获取提取信息,这使得其具有缓解“梯度消失”,加速网络收敛的功能。
然而,直接在中间层添加额外的监督信息的方式在训练极深网络时可能会导致模型性能下降。众所周知,深度网络具有极强的分层特征表达能力,其特征会随网络深度而变化(底层特征聚焦边缘特征而缺乏语义信息,而高层特征则聚焦于语义信息)。在底层添加强监督信息会导致深度网络的上述特征表达方式被破坏,进而导致模型的性能下降。这从某种程度上解释了为何上述监督方式对模型的性能提升比较小(大概在0.5%左右,甚至无提升)。
Dynamic Hierarchical Mimicking
作者重新对上述优化目标进行了分析并给出猜测:“最本质的原因在于损失函数中相加的两块损失优化目标不一致”。以分类为例,尽管两者均意在优化交叉熵损失,但两者在中间层的优化方向是不一致的,存在矛盾点,进而导致对最终模型性能产生负面影响。
针对上述问题,作者提出一种新颖的知识匹配损失用于正则化训练过程,并使得不同损失对中间层的优化目标相一致,从而确保了模型的鲁棒性与泛化性能。
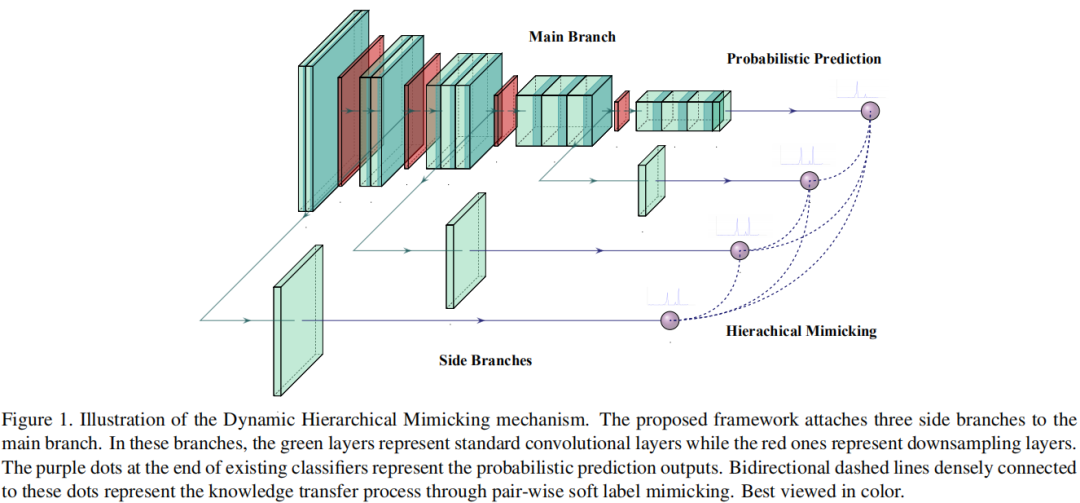
所提方法的优化目标函数可以描述如下公式,其示意图见上图。
其中比较关键在于第三项的引入,也就是所提到的知识匹配损失。注:由于全文公式太多,本人只是相对粗略的看来一遍,没有过于深度去研究。应该不会影响对其的认知,见后续的对比分析。
Experiments
为验证所提方法的有效性,作者在多个数据集(Cifar,ImageNet,Market1501等)上的机型了实验对比分析。
首先,给出了CIFAR-100数据集上所提方法与DSL的性能对比,见下图。尽管DSL可以提升模型的性能,但提提升比较少,而作者所提DHM可以得到更高的性能提升。该实验证实了所提方法的有效性。

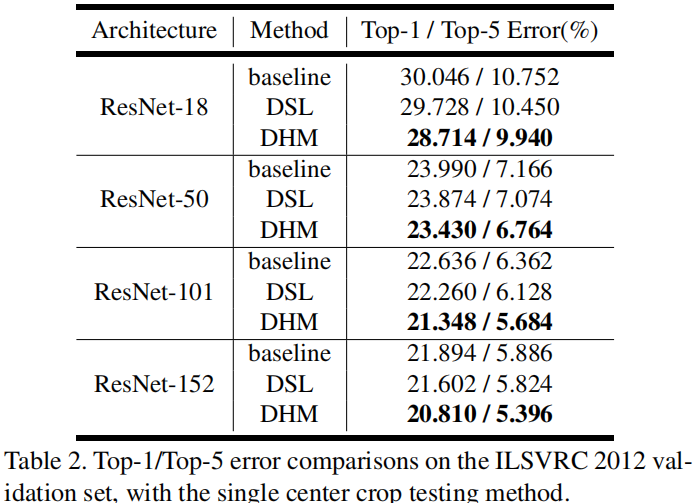
然后,作者给出了ImageNet数据集上的性能对比,见下图。可以得到与前面类似的结论,但同时可以看到:对于极深网络(如ResNe152),DSL的性能提升非常有限,而所提方法仍能极大的提升模型的性能超1%。
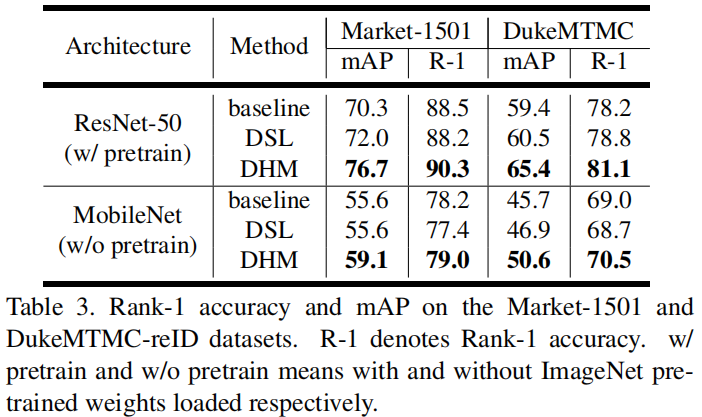
其次,作者给出了Market1501数据集上的性能对比,见下图。结论同前,不再赘述。
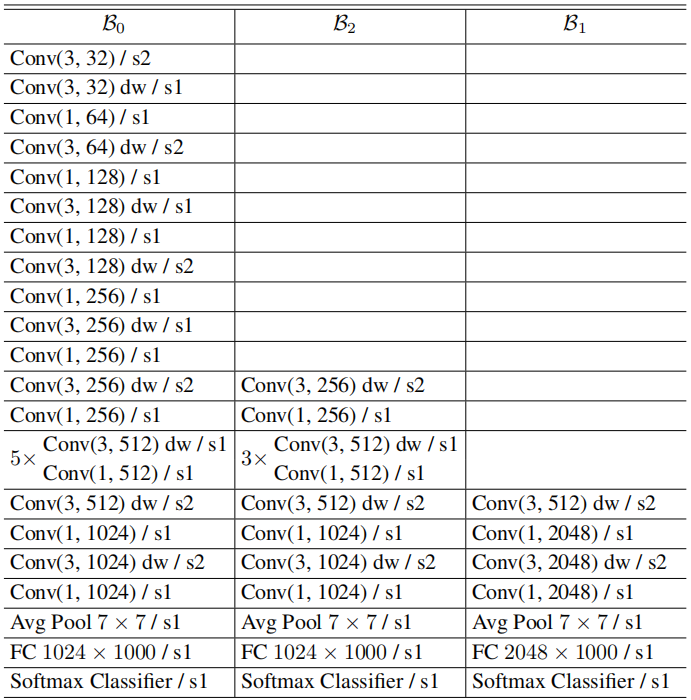
最后,作者还提供了其实验过程中的网络架构,这里仅提供一个参考模型(MobileNet)作为示例以及分析说明。除了MobileNet外,作者还提供了DenseNet、ResNet、WRN等实验模型。
Discusion
实事求是的说,本人在看到最后的网络结构和代码之前是没看明白这篇论文该怎么应用的。只是大概了解DSL破坏了深度网络的分层特征表达能力,针对该问题而提出的解决方案。
看了论文和代码后,基本上明白了作者是怎么做的。就一点:既然DSL破坏了深度网络的分层特征表达能力,那么就想办法去补偿以不同损失反向传播到中间层与底层时优化方向是一致的。那么该怎么去补偿呢?下图给出了图示,中间主干分支表示预定义好的网络结构,左右两个分支表示作者补偿的结构,通过这样的方式可以确保主损失与右分支损失传播到layer3的优化方向一致,主损失与做分支损失传播到layer2的优化方向一致。当然图中两个颜色layer3表示这是不同的处理过程,分支的处理过程肯定要比主分支的计算量小,否则岂不是加大了训练难度?
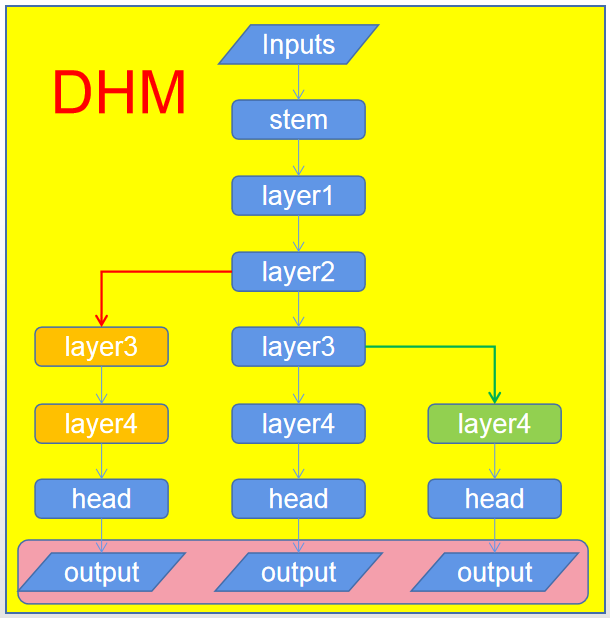
我想,看到这里大家基本上都明白了DHM这篇论文所要表达的思想了。接下来,将尝试将其与其他类似的方法进行一下对比分析。首先给出传统训练方式、DSL训练方式与DHM的对比图(注:图中暗红色区域表示损失计算,具体怎么计算不详述)。
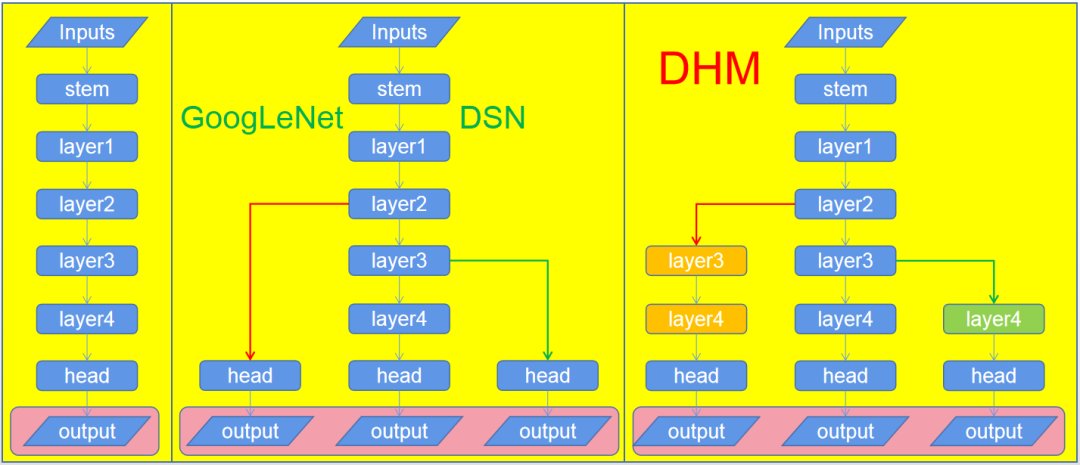
上图给出了常规训练过程、DSL训练过程以及DHM的训练成果对比。常规训练过程仅在head部分有一个损失;而DSN(即DSL)则有多个损失,不同的损失回传的速度时不一样的,比如左分支损失直接传给了layer2,这明显快于中间的主损失,这是缓解“梯度消失”的原因所在;DHM类似于DSL具有多个损失,但同时为防止不同损失对中间层优化方向的不一致,而添加了额外的辅助层,用于模拟深度网络的分层特征表达。
那么DHM是如何缓解“梯度消失”现象的呢?个人认为,它有两种方式:(1) ResNet与DenseNet中的缓解“梯度消失”的方式,这与网路结构有关;(2)分支层数少于主干层数,一定程度上缓解了“梯度消失”。
最后,再补上一个与DHM极为相似的方法DML,两者的流程图如下所示。论文原文确实提到了DML方法,但并未与之进行对比。从图示可以看到两者还是比较相似的,尽管DML初衷是两个网络采用知识蒸馏的方式进行训练,而DHM则是针对DSL存在的缺陷进行的改进。
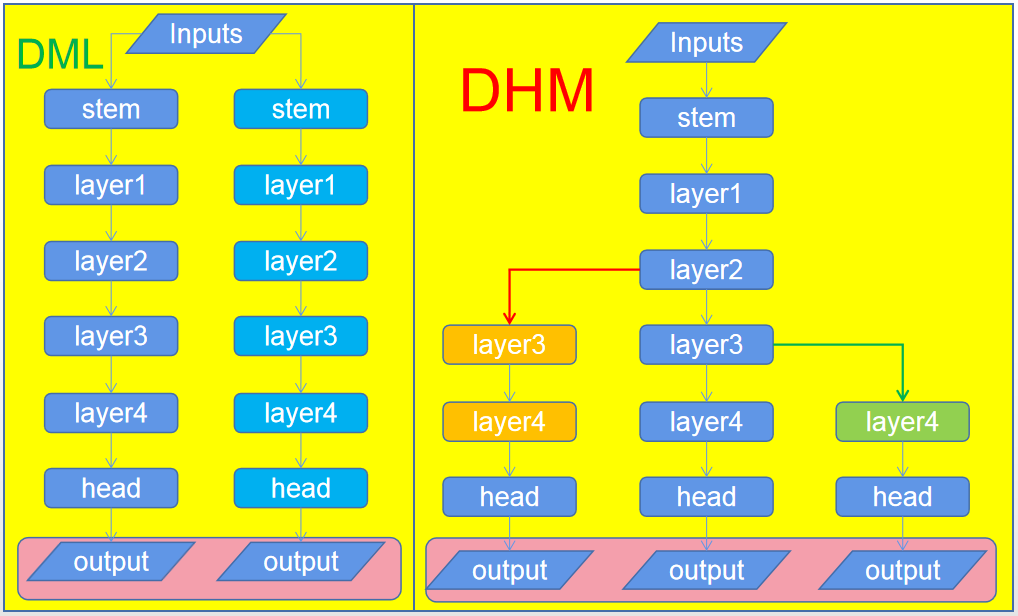
私认为DHM是DML的特例(注:仅仅从上述图示出发),有这么三点原因:
-
损失函数方面,以图像分类为例,DML与DHM均采用交叉熵损失+KL散度计算不同分支损失; -
分支数方面:尽管DML原文是借鉴识蒸馏方式,但其分支可以不止两个,比如扩展到三个呢,四个呢?这两种方式是不是就一样了呢? -
网路结构方面:尽管DML提到的是两个网络,但是两个网络如果共享stem+layer1+layer2部分呢?从这个角度来看,DHM与DML殊途同归了。
做完上述记录后,本人厚着脸皮去骚扰了一下李铎大神,请教了一下。经允许,现将作者的理解摘录如下:
DSL存在的问题:(1) 特征逐级提取问题,如果像上述图中googlenet/dsn那样把head直接接在中间层立刻再接classifier,那么强制要求layer2、layer3、layer4都提取high-level语意特征,这和一般网络里layer2、layer3可能还在提取更low-level的特征相违背;(2) 不同分支的gradient都会回传到shared的主支上,如果这些gradient相互冲突甚至抵消,对于整个网络的优化是产生负面影响的。
DHM的解决方案:(1)第一个问题通过图中的分支网络结构的改进来解决;(2)第二个问题则是通过KL散度损失隐式约束梯度来解决。
OK,关于DHM的介绍,全文到底结束!码字不易,思考更不易,还请给个在看。
Reference
-
Going Deeper with Convolutions. https://arxiv.org/abs/1409.4842 -
Deeply Supervised Networks. https://arxiv.org/abs/1409.5185 -
Deep Mutual Learning. https://arxiv.org/abs/1706.003384

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~


