基于深度学习的单模医学图像配准综述(附VoxelMorph配准实例和代码)

极市导读
本文将问题分为线性配准和非线性配准、基于全分辨率图像的配准和基于patch的配准以及传统的配准方法和基于学习的配准方法三类,并介绍了配准网络框架、实例以及代码。>>加入极市CV技术交流群,走在计算机视觉的最前沿
一、配准简介
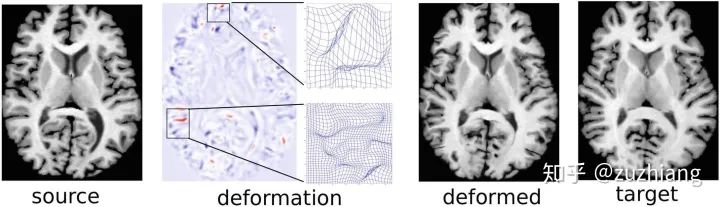
二、配准问题分类
1. 线性配准和非线性配准
2. 基于全分辨率图像的配准和基于patch的配准
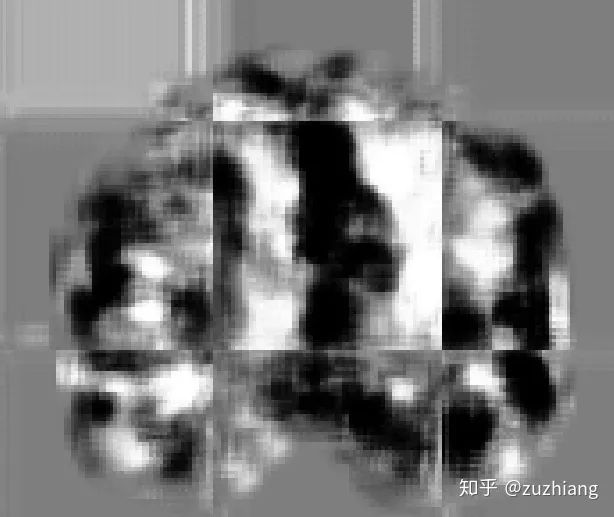
3. 传统的配准方法和基于学习的配准方法
1)传统的配准方法
2)基于学习的配准方法
i)有监督的基于学习的配准方法
ii)无监督的基于学习的配准方法
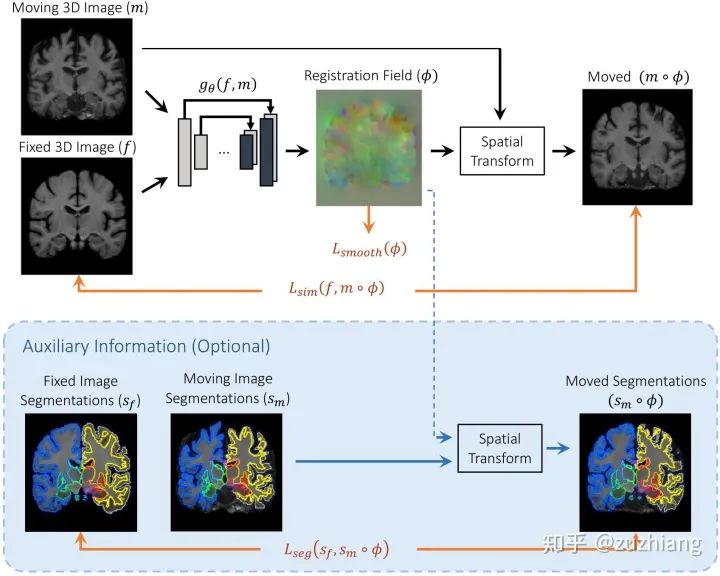
三、配准网络框架
1. 配准网络框架

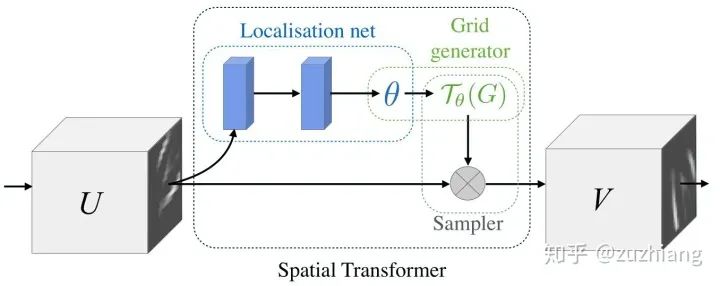
2. 空间转换网络
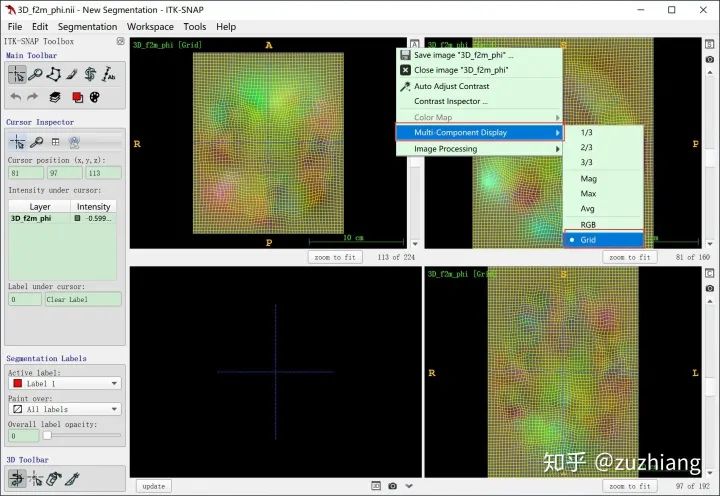
3. 损失函数
四、VoxelMorph配准实例
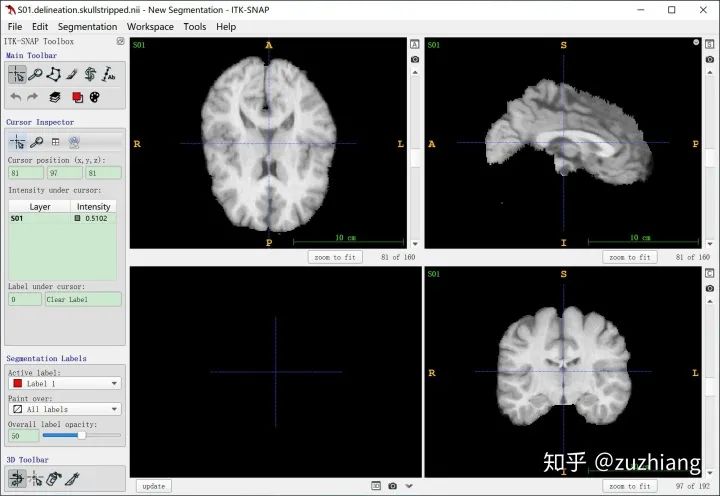
1. 数据集及预处理
LPBA40 Subjects Native Space: MRI data and brain masks in native space和
LPBA40 Subjects Delineation Space: MRI and label files in delineation space两个选项中下载得到的分别是native space和delineation space的图像数据,delineation space的数据集已经对齐到mni305空间(具体是什么我也不是很清楚)了,只需要做简单归一化效果就会很好,而native space的我配准的效果一直不好,所以建议用delineation space的图像。
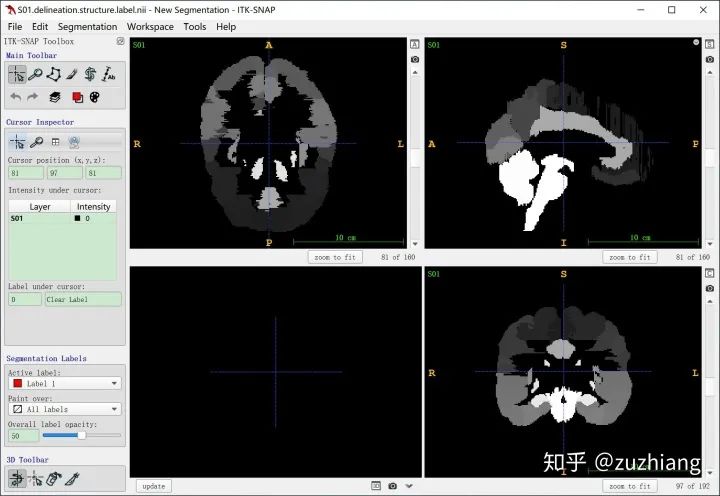
2. baseline
3. 训练
4. 测试
五、VoxelMorph代码
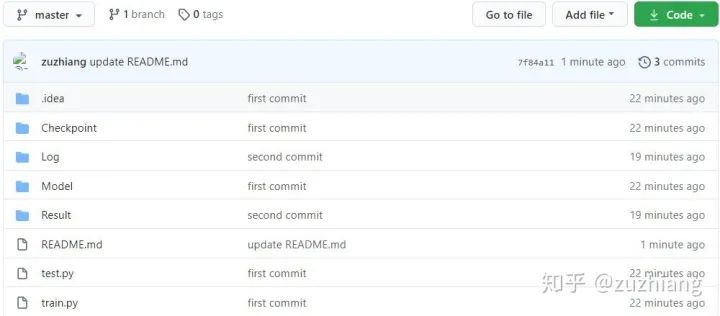
-
Checkpoint:存放训练好的模型的文件夹; -
Log:存放日志文件的文件夹,记录各个参数下各种loss值的变化; -
Model -
config.py:模型配置文件,用来指定学习率、训练次数、loss权重、batch size、保存间隔等,分为三部分,分别是公共参数、训练时参数和测试时参数; -
datagenerators.py:根据图像文件的路径提供数据,使用了torch.utils.data包来实现的; -
losses.py:各种损失函数的计算,包括形变场平滑性损失、MSE、DSC、NCC、CC、雅克比行列式中负值个数等; -
model.py:配准网络(U-Net)和空间变换网络(STN)的实现,并且将两者进行了模块化分离。 -
Result:存放训练和测试过程中产生的图像数据的文件夹; -
test.py:测试代码; -
train.py:训练代码。
0.6855077809012164,作为对比,ANTs包中的SyN算法配准的DSC值为
0.6939350219828658。
-
train:训练图像数据,包括S11-S40共30个图像,只进行过裁剪到大小,和局部归一化操作; -
test:测试图像数据,包括S02-S10共9个图像,只进行过裁剪到大小,和局部归一化操作; -
label:标签数据,包括S01-S40共40个图像,只进行过裁剪到大小的操作,无归一化; -
fixed.nii.gz:即S01图像,作为固定图像。
[2] Z.W. Zhou, M.M.R. Siddiquee, N. Tajbakhsh, J.M. Liang, "UNet++: A Nested U-Net Architecture for Medical Image Segmentation", CVPR, 2018.
[3] Fan J, Cao X, Wang Q, Yap PT, Shen D. Adversarial learning for mono- or multi-modal registration. Med Image Anal. 2019 Dec;58:101545. doi: 10.1016/j.media.2019.101545. Epub 2019 Aug 24. PMID: 31557633; PMCID: PMC7455790.
[4] J. F. Fan, X. H. Cao, Z. Xue, P. Yap, and D. G. Shen, “Adversarial similarity network for evaluating image alignment in deep learning based registration,” vol. 11070, pp. 739–746, 2018.
[5] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” pp. 2017–2025, 2015.
[6] G. Balakrishnan, A. Zhao, M. R. Sabuncu, A. V. Dalca, and J. V. Guttag, “An unsupervised learning mod- el for deformable medical image registration,” pp. 9252–9260, 2018.
[7] S.Y. Zhao, Y.Dong, E.Chang, and Y.Xu, “Recursive cascaded networks for unsupervised medical image registration,” pp. 10600–10610, 2019.
[8] Kuang D. (2019) Cycle-Consistent Training for Reducing Negative Jacobian Determinant in Deep Registration Networks. In: Burgos N., Gooya A., Svoboda D. (eds) Simulation and Synthesis in Medical Imaging. SASHIMI 2019. Lecture Notes in Computer Science, vol 11827. Springer, Cham. https://doi.org/10.1007/978-3-030-32778-1_13
推荐阅读




登录查看更多
相关内容
Arxiv
0+阅读 · 2020年12月3日
Arxiv
0+阅读 · 2020年12月1日
Arxiv
10+阅读 · 2018年5月10日
Arxiv
3+阅读 · 2017年8月2日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年12月3日
Arxiv
0+阅读 · 2020年12月1日
Arxiv
10+阅读 · 2018年5月10日
Arxiv
3+阅读 · 2017年8月2日