浅谈NLP中的对抗训练方式

©作者 | 林远平
单位 | QTrade AI研发中心
研究方向 | 自然语言处理

前言

对抗样本一般需要具有两个特点:
1、相对于原始输入,所添加的扰动是微小的;
2、能使模型犯错。
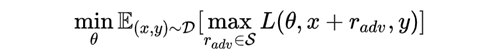

FGM
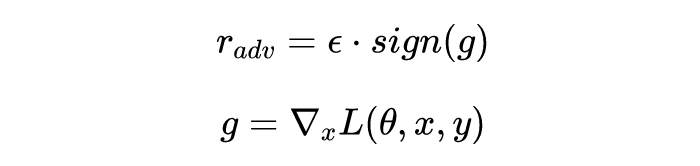

import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
# 初始化
fgm = FGM(model)
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()

PGD
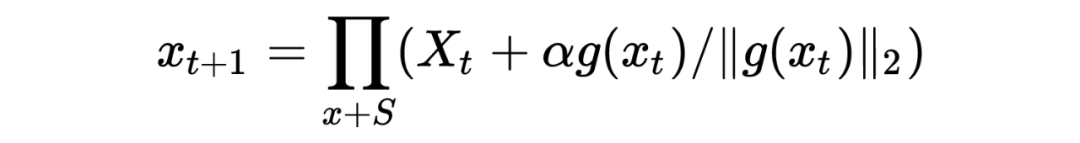
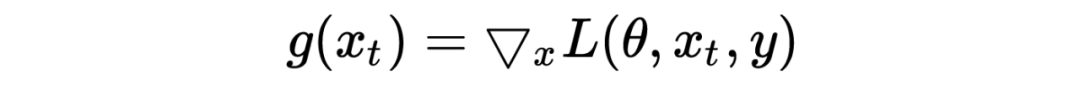

对于每个输入x,假设运行K步:
1、计算x的前向loss、反向传播得到的梯度并保存,备份初始时的embedding,
对于每一步t:
2、根据embedding矩阵的梯度计算出扰动r,并加到当前embedding上,相当于x+r(超出范围则投影回epsilon内)
3、当t不是第K-1步(K从0开始)时:将梯度变回0,根据(2)中的x+r计算前向loss和反向梯度
4、当t是第K-1步(K从0开始)时:恢复(1)的梯度,计算最后的x+r并将梯度累加到(1)上
5、将embedding恢复为(1)时的值
6、根据(4)的梯度对参数进行更新
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()

FreeLB
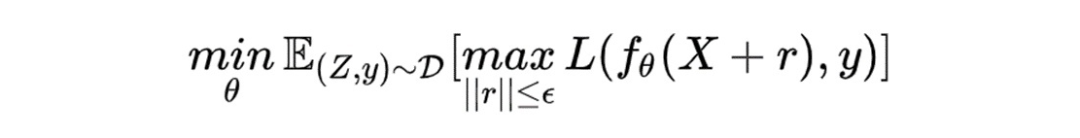

FreeLB 和 PGD 主要有两点区别:
1、PGD 是迭代 K 次 r 后取最后一次扰动的梯度更新参数,FreeLB 是取 K 次迭代中的平均梯度
2、PGD 的扰动范围都在 epsilon 内,因为 PGD 伪代码第 3 步将梯度归 0 了,每次投影都会回到以第 1 步 x 为圆心,半径是 epsilon 的圆内,而 FreeLB 每次的 x 都会迭代,所以 r 的范围更加灵活,更可能接近局部最优

对于每个输入x:
1、通过均匀分布初始化扰动r,初始化梯度g为0,设置步数为K
对于每步t=1...K:
2、根据x+r计算前向loss和后向梯度g1,累计梯度g=g+g1/k
3、更新扰动r,更新方式跟PGD一样
4、根据g更新梯度

class FreeLB():
def __init__(self, model, args, optimizer, base_model='xlm-roberta'):
self.args = args
self.model = model
self.adv_K = self.args.adv_K
self.adv_lr = self.args.adv_lr
self.adv_max_norm = self.args.adv_max_norm
self.adv_init_mag = self.args.adv_init_mag # adv-training initialize with what magnitude, 即我们用多大的数值初始化delta
self.adv_norm_type = self.args.adv_norm_type
self.base_model = base_model
self.optimizer = optimizer
def attack(self, model, inputs):
args = self.args
input_ids = inputs['input_ids']
#获取初始化时的embedding
embeds_init = getattr(model, self.base_model).embeddings.word_embeddings(input_ids.to(args.device))
if self.adv_init_mag > 0: # 影响attack首步是基于原始梯度(delta=0),还是对抗梯度(delta!=0)
input_mask = inputs['attention_mask'].to(embeds_init)
input_lengths = torch.sum(input_mask, 1)
if self.adv_norm_type == "l2":
delta = torch.zeros_like(embeds_init).uniform_(-1, 1) * input_mask.unsqueeze(2)
dims = input_lengths * embeds_init.size(-1)
mag = self.adv_init_mag / torch.sqrt(dims)
delta = (delta * mag.view(-1, 1, 1)).detach()
else:
delta = torch.zeros_like(embeds_init) # 扰动初始化
# loss, logits = None, None
for astep in range(self.adv_K):
delta.requires_grad_()
inputs['inputs_embeds'] = delta + embeds_init # 累积一次扰动delta
# inputs['input_ids'] = None
loss, _ = model(input_ids=None,
attention_mask=inputs["attention_mask"].to(args.device),
token_type_ids=inputs["token_type_ids"].to(args.device),
labels=inputs["sl_labels"].to(args.device),
inputs_embeds=inputs["inputs_embeds"].to(args.device))
loss = loss / self.adv_K
loss.backward()
if astep == self.adv_K - 1:
# further updates on delta
break
delta_grad = delta.grad.clone().detach() # 备份扰动的grad
if self.adv_norm_type == "l2":
denorm = torch.norm(delta_grad.view(delta_grad.size(0), -1), dim=1).view(-1, 1, 1)
denorm = torch.clamp(denorm, min=1e-8)
delta = (delta + self.adv_lr * delta_grad / denorm).detach()
if self.adv_max_norm > 0:
delta_norm = torch.norm(delta.view(delta.size(0), -1).float(), p=2, dim=1).detach()
exceed_mask = (delta_norm > self.adv_max_norm).to(embeds_init)
reweights = (self.adv_max_norm / delta_norm * exceed_mask + (1 - exceed_mask)).view(-1, 1, 1)
delta = (delta * reweights).detach()
else:
raise ValueError("Norm type {} not specified.".format(self.adv_norm_type))
embeds_init = getattr(model, self.base_model).embeddings.word_embeddings(input_ids.to(args.device))
return loss
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
freelb = FreeLB( model, args, optimizer, base_model)
loss_adv = freelb.attack(model, batch_input)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()

总结

参考文献
[1] FGSM: Explaining and Harnessing Adversarial Examples
[2] FGM: Adversarial Training Methods for Semi-Supervised Text Classification
[3] FreeLB: Enhanced Adversarial Training for Language Understanding
[4] 训练技巧 | 功守道:NLP中的对抗训练 + PyTorch实现
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧




