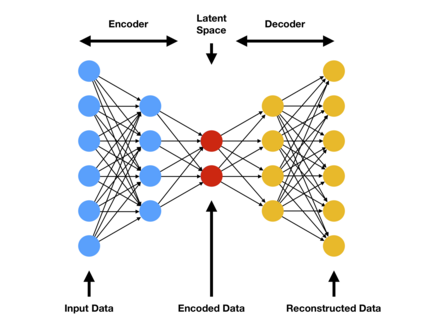
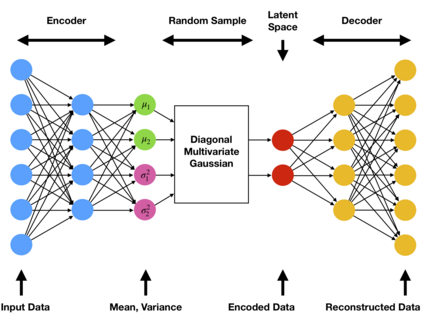
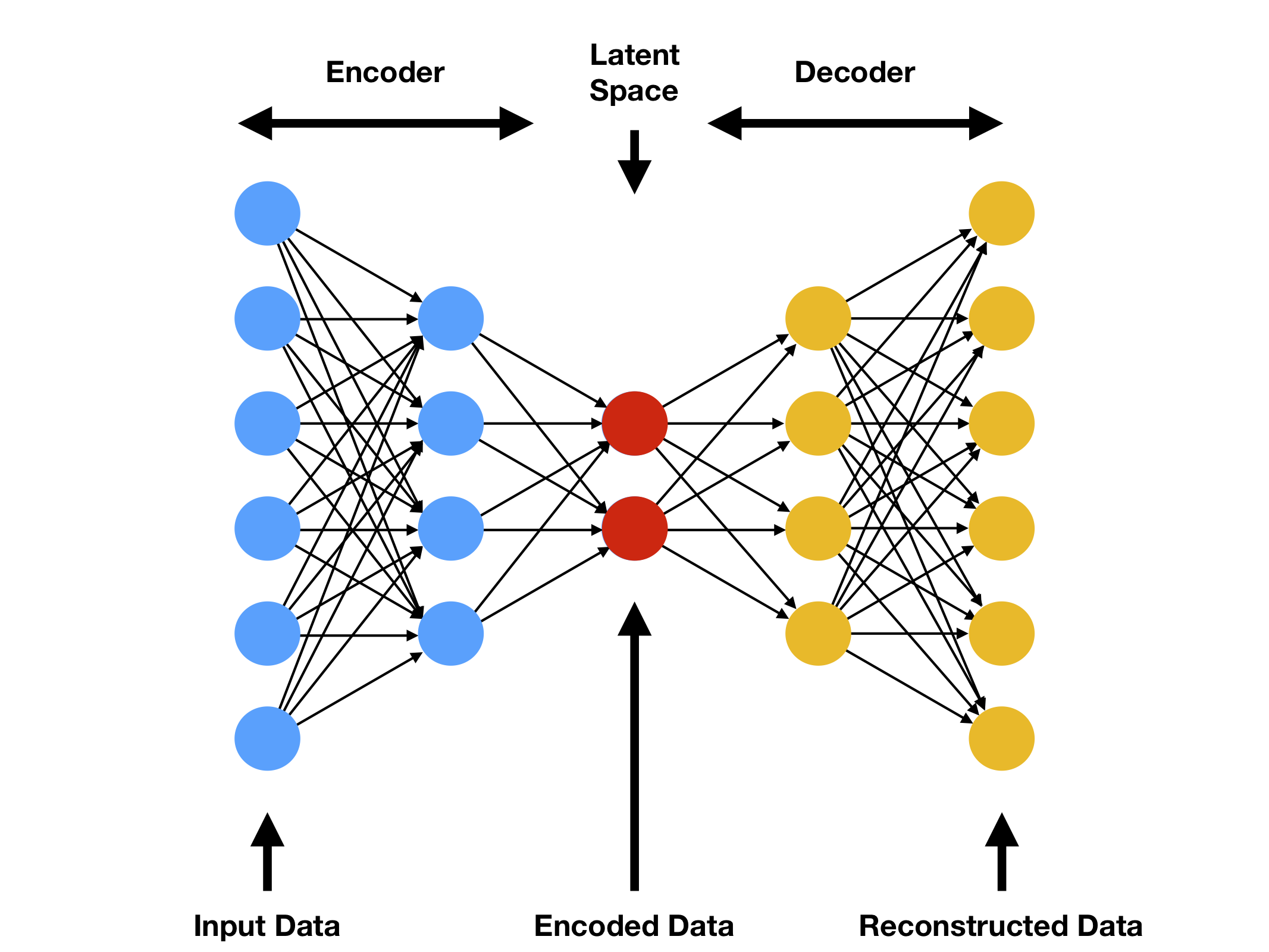
Generative Adversarial Nets (GAN) have received considerable attention since the 2014 groundbreaking work by Goodfellow et al. Such attention has led to an explosion in new ideas, techniques and applications of GANs. To better understand GANs we need to understand the mathematical foundation behind them. This paper attempts to provide an overview of GANs from a mathematical point of view. Many students in mathematics may find the papers on GANs more difficulty to fully understand because most of them are written from computer science and engineer point of view. The aim of this paper is to give more mathematically oriented students an introduction to GANs in a language that is more familiar to them.
翻译:自2014年Goodfellow等人的开创性工作以来,GAN(GAN)受到相当多的关注。这种关注导致GAN(GAN)的新思想、技术和应用激增。为了更好地了解GAN(GAN)背后的数学基础,我们需要更好地了解GAN(GAN),本文试图从数学角度提供GAN(GAN)的概况。许多数学学生可能发现GAN(GAN)的论文更难完全理解,因为大多数论文是从计算机科学和工程师的角度撰写的。本文的目的是用他们更熟悉的语言向数学更具有方向的学生介绍GAN(GAN)。