ML:教你聚类并构建学习模型处理数据(附数据集)

翻译: 王雨桐
校对: 顾佳妮
本文约1500字,建议阅读6分钟。
本文以Ames住房数据集为例,对数据进行聚类,并构建回归模型。
摘要
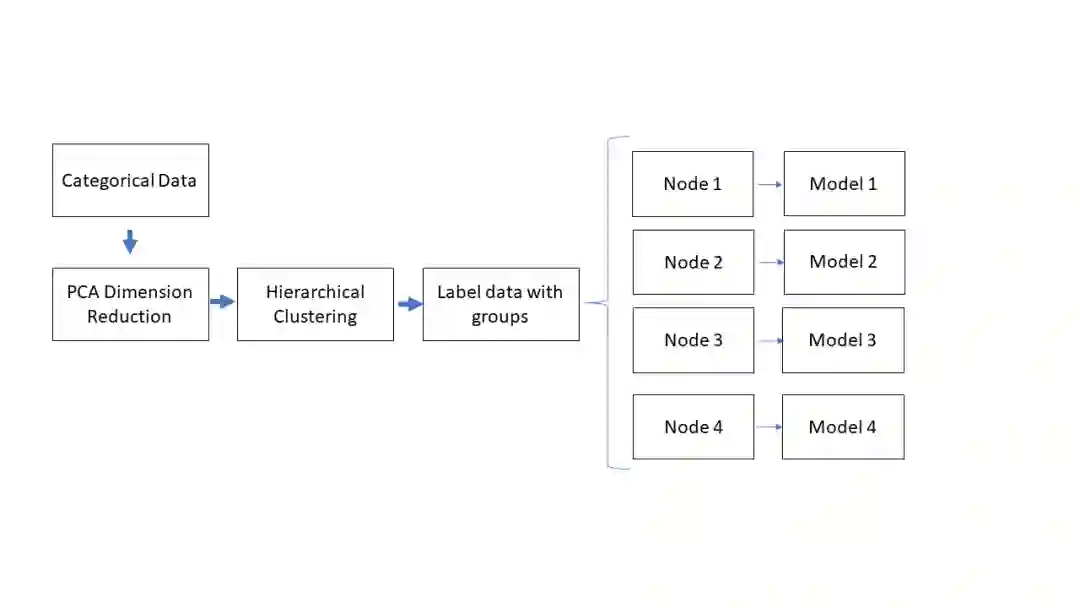
本文将根据41个描述性分类特征的维度,运用无监督主成分分析(PCA)和层次聚类方法对观测进行分组。将数据聚类可以更好地用简单的多元线性模型描述数据或者识别更适合其他模型的异常组。此方法被编写在python类中,以便将来能实现类似网格搜索的参数优化。
结果与讨论
本项目中,我们将机器学习技术应用于Ames住房数据集,用79个解释变量来预测房屋的销售价格,其中包括41个分类变量(分类型变量),38个连续数值变量(连续型变量)。在最初探索性数据分析(EDA)和特征选择的过程中,为了更好地理解数据,我们仅用两个连续变量来拟合数据,以便通过三维散点图反映数据和模型。通过列举38个连续数值变量的所有双变量排列组合并分别拟合线性回归模型,我们选出了两个对销售价格预测能力最强的变量。在考虑整个训练集时,地上居住面积和整体质量参数是最佳的预测指标,但这只解释了房屋销售价73.9%的方差。通过使用41个分类特征来识别数据集内的组群,我们可以将数据集分解为方差更小的子集,并找到更好地描述每个特定房屋子集的模型。
附Ames housing数据集:
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
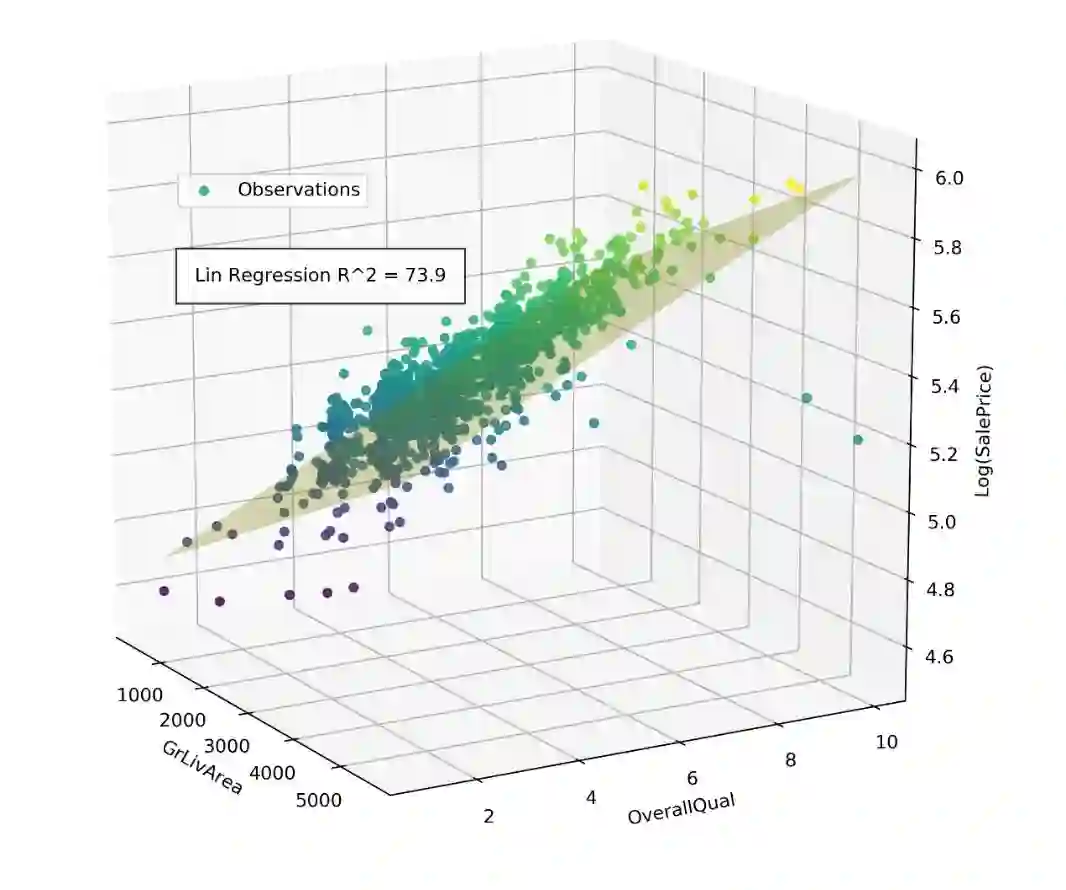
一个简单的线性回归模型可以体现地上居住面积和整体质量对住宅销售价格的影响,它解释了74%的房价变动
由于分类变量较多,并且对Ames房屋市场的专业知识有限,我们使用无监督的聚类方法找到变量里的模式并在此基础上分组。首先通过PCA对数据集进行降维,以避免大量分类变量造成的“维度灾难”效应。PCA还有其他的好处,它能把对总体方差没有贡献的变量数量降到最低,并且将维度降低到三维以便我们直观地改进聚类算法的图形表示(并且将维度降低至三维,给了我们一个图形化的分类效果展示,以便做出直观地改进)。下图展示了由PCA将分类变量降到3维的图形:
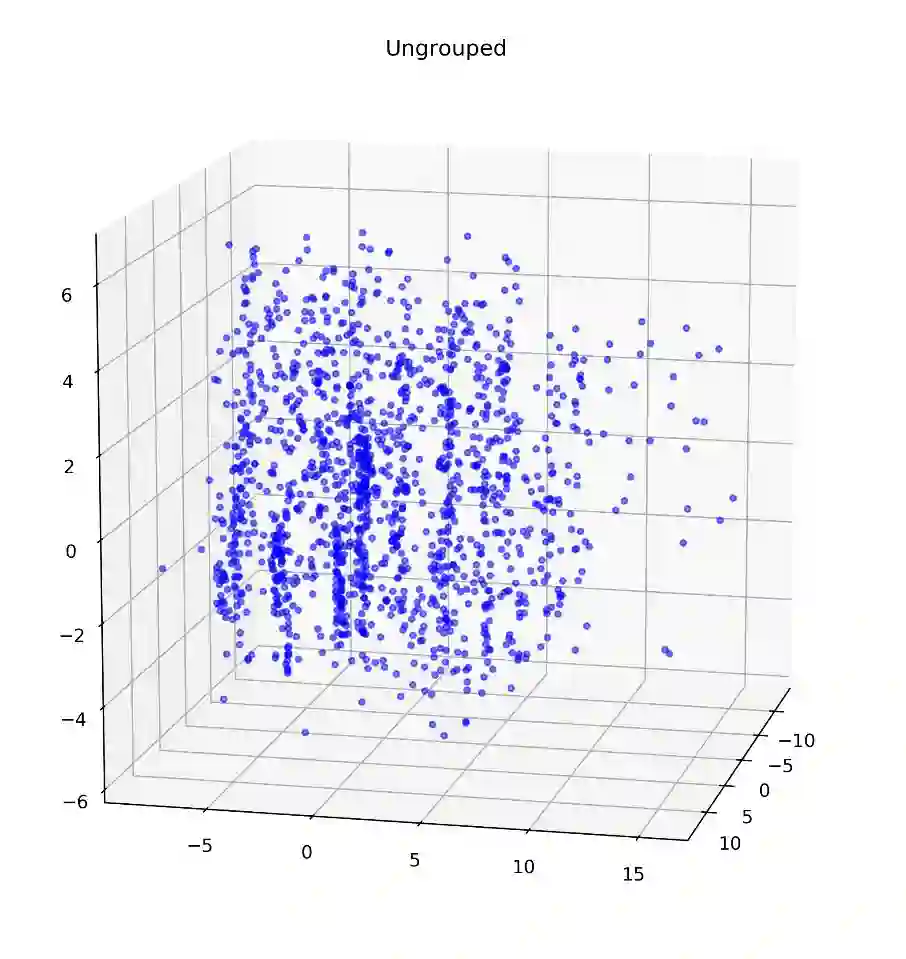
由41个分类变量浓缩后的三维PCA空间数据表示
通过对此图的初步观察,数据大部分的差异体现在新的Y(垂直)维度。在X(宽度)和Z(深度)维度中,差异来源于设定的类别,进而导致数据形成垂直方向的条纹。由于群集的各向异性,我们利用有k-nearest neighbor connector参数的层次聚类算法来定义组,这样就不会将条带分割成多个部分。(我们利用层次聚类算法中的k邻近算法,在不把竖状条纹割开的基础上重新定义各个组。)(在Python的sklearn库中,AgglomerativeClustering方法可以用于聚类。本案例中,基于Ward linkage标准把类的数量设置为6,以及由kneighbors_graph包生成连接数组,其中参数n_neighbors设置为20)。
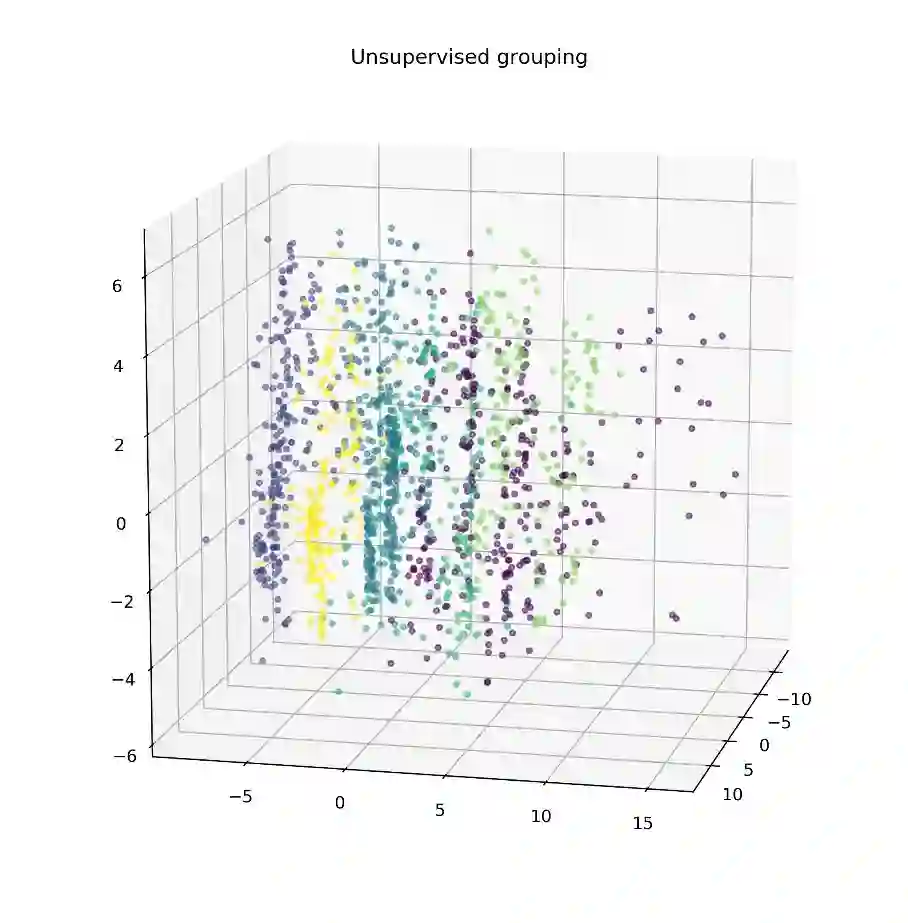
层次聚类分组的PCA空间表示
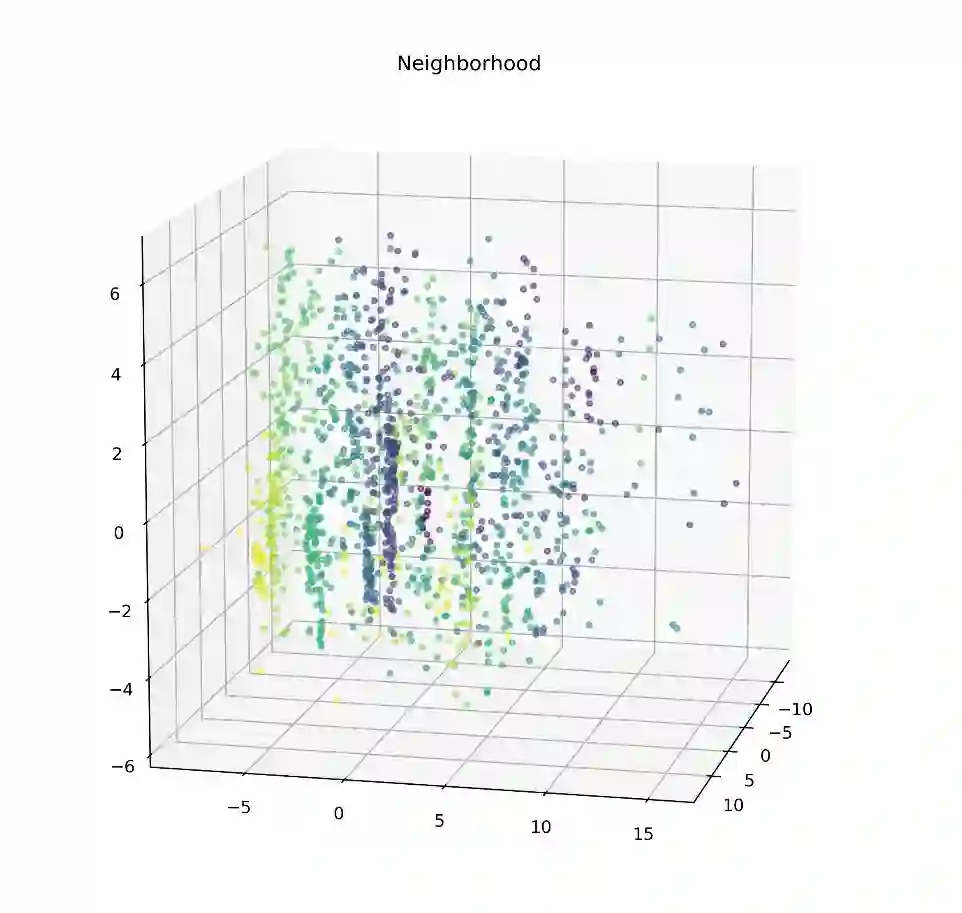
基于邻近地区着色和PCA降维的观测有助于发现影响降维及聚类的因素
由PCA 、聚类方法生成的群集非常好地区别了分组中的垂直“条纹”。为了找到无监督聚类和其所对应的房屋特征之间的相似点,这些群集也基于每个分类变量着色。其中一些彩色的散点图类似于无监督聚类,表明这些特定的房子特征在确定每个数据点的最终PCA向量时起较大的作用。特别注意的是,基于邻近区域(neighborhood)着色突出了与无监督方法相似的垂直分组,这表明邻近区域是影响分解子集的一个重要因素。为了此类应用,我们需要设计更精确的方法来确定每个因素对最终PCA维度的整体“贡献”。
为了确定每个组中哪两大因素是销售价格最好的预测因素,我们用这6个集群把连续数值数据分为子集,并假设一个简单的二元线性回归模型
组别 |
最有影响力的自变量 |
判定系数 |
1 |
Overall Quality : GrLivArea |
79.5% |
2 |
Overall Quality : GarageArea |
68.2% |
3 |
Overall Quality : GarageCars |
73.5% |
4 |
Overall Quality : 1stFlrSF |
62.5% |
5 |
Overall Quality : GarageCars |
85.9% |
虽然有些节点比其他节点更适合线性回归,但相比于将数据作为整体来处理,用模型拟合这些群集在精度上没有累积差异。然而,这只是概念验证的初始迭代,还没有优化关键参数,如n_nodes、(节点数量),PCA dimensions(PCA维度)和KNN connectivity parameters(KNN连通度)。将这些方法编码到一个python类中,它可以协助使用类似于网格搜索的优化过程来确定最佳的集群参数,从而最大化简单线性回归模型的准确性。请参考下列GitHub链接中的"MC_regressor_Code.ipynb":
https://github.com/dgoldman916/housing-ml。
未来工作
此时,“概念验证”的关键缺失是对新数据进行训练和分类的能力。在引入测试集时,要先基于训练得到的参数将新数据被分为有标记的组。这就需要一个有监督的聚类方法,比如决策树或支持向量机(SVM)。在添加此类函数之后,可以将其应用到组的其他工作流程中。我们可以通过预期的最终迭代在拟合穿过节点的更复杂的模型,并将这些模型的结果集中在一起。
原文标题:
Machine Learning: Unsupervised dimension reduction and clustering to process data for pooled regression models
原文链接:
https://nycdatascience.com/blog/student-works/machine-learning-unsupervised-dimension-reduction-and-clustering-to-process-data-for-pooled-regression-models/
译者简介

王雨桐,统计学在读,数据科学硕士预备,跑步不停,弹琴不止。梦想把数据可视化当作艺术,目前日常是摸着下巴看机器学习。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织