小米的语音识别系统是如何搭建的
小米的语音识别系统是如何搭建的
本文参考文献
Attention-based End-to-end Speech Recognition in Mandarin
近期,小米发布了一篇中文的语音识别系统论文,该语音识别系统使用了基于注意力机制的seq2seq模型,并且融合了调帧、权重归一化等技巧,美中不足的是,文中给出的实验结果并不是公开的数据集,而是小米内部的MiTV语音数据集,尽管准确率达到了96.42%,但缺乏公开数据集的验证让论文的说服力有所降低。其实公开的中文语音识别数据库虽然稀少,但也并非没有,例如在openslr网站上,已经开源了两个中文语音识别数据集,分别是清华大学的THCHS-30和希尔贝壳公司的AiShell-1,后者是近期刚刚开源的数据集。
回归正题,本文的亮点主要如下:
在中文语音识别中第一次尝试用基于注意力机制的seq2seq模型;
通过使用调帧的方法来减小源序列长度,其实这一技巧在之前已有论文提出;
采取多种不同的归一化技巧来加速收敛和提高范化能力;
比较了不同注意力机制的影响;
把seq2seq模型运用到语音识别中在之前已经有人做过,例如William Chan提出的Listen, Attend and Spell(LAS)就是一个基于注意力机制的序列建模框架,其通过注意力机制产生一段固定长度的上下文,再经过解码器得到最终的输出。seq2seq模型的优势就在于可以应付输入序列与输出序列长度不一的情况,而语音识别恰好符合。
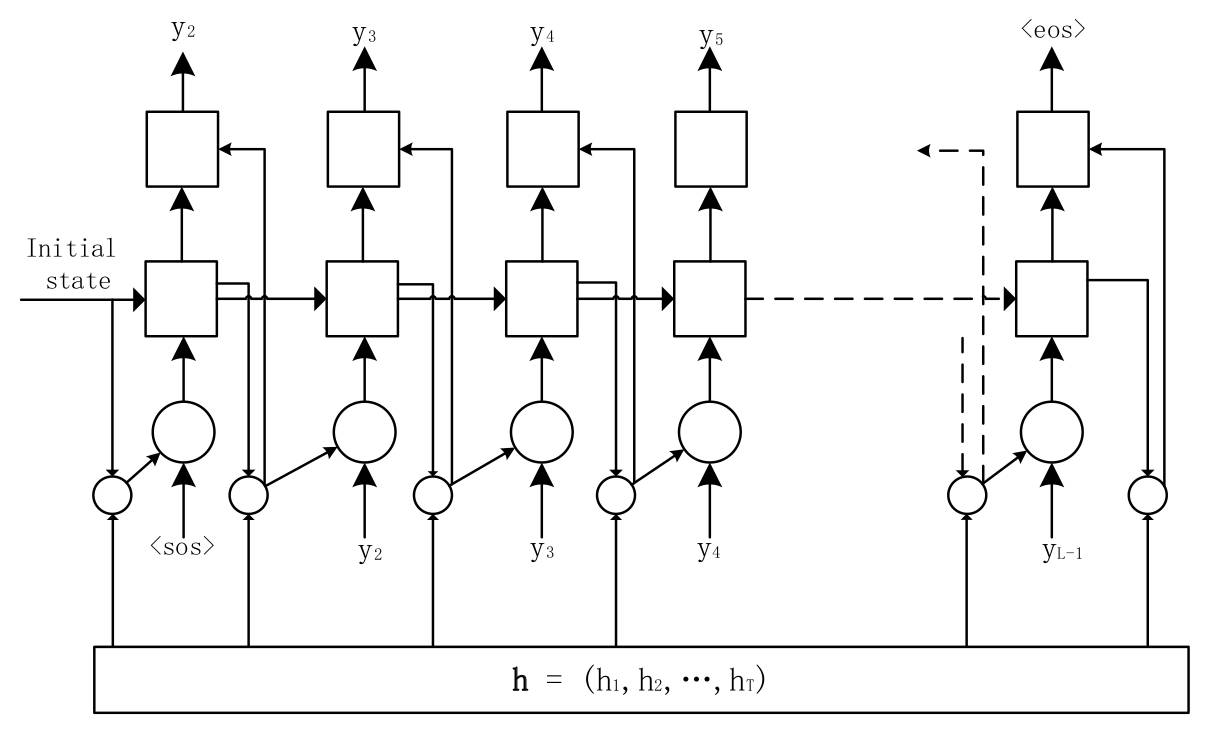
究竟什么是注意力机制?注意力机制一开始是被应用于机器翻译,它所要解决的是序列建模时候源序列与目标序列的对齐问题,在解码器每生成一个单词的时候,注意力机制都会结合编码器上最优可能的隐含状态。
最常见的计算注意力机制的算法如上面的公式所示,AttentionContext函数通常是一个多层感知器,Score函数也是一个多层感知器,最后归一化得到的alpha就是注意力权重因子,这种最早是由Bahdanau提出来的,也可以称之为基于内容的注意力机制,小米在此基础上增加了基于位置的考虑,即将前一时刻的注意力权重考虑在内,具体公式如下。
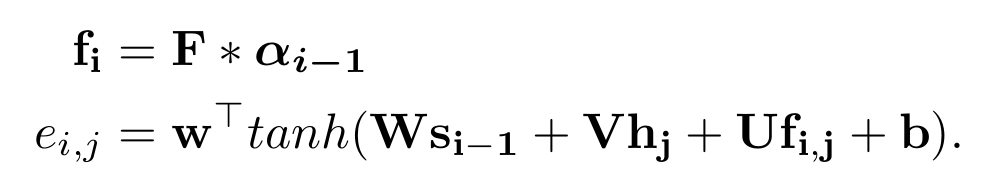
同时,文中中使用了注意力平滑的方法,当采用softmax分布得到的alpha只会集中在少数几帧上,为了解决这个问题,小米将softmax换成了sigmoid分布。
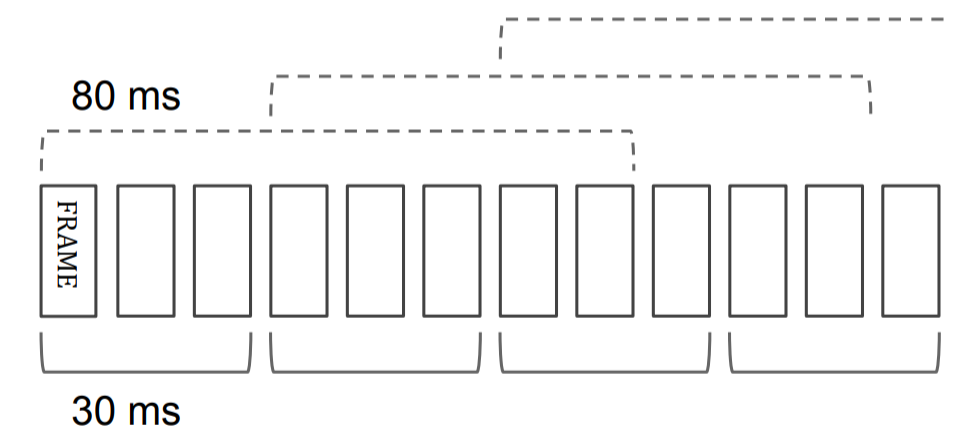
由于在LAS框架中,当输入序列过长时,识别的准确性会显著降低,LAS中的解决方法是使用了金字塔形状的BLSTM来作为编码器,这样就可以缩短编码序列的长度。而小米这里采取的方案是使用基于帧的sub-sampling,具体的方法就是:例如一段音频的原始特征向量是100*39,100表示时长,39表示特征维度,那么传统的做法就是直接设置LSTM的时长为100,每个时间点输入一个1×39的特征,而sub-sampling做法是将8帧拼接起来作为一个大帧,该大帧的维度就是1×312,然后再每隔3帧取另外的8帧作为一个大帧,类似于一维卷积中的stride,如下图所示,这样就可以将源序列的时长缩短。
小米在模型中还使用了正则化技巧:L2正则化以及高斯权重噪声。L2正则化很常见,即在误差函数后面再添一项L2,但是文中还使用了另外一个技巧,就是对所有的权重都增加一个高斯噪声,这样可以增强模型的范化能力。这种做法以前很少见,我比较偏向的做法是对输入特征增加随机的高斯噪声来提高范化能力,相比于小米的做法,对输入特征增加随机噪声就容易很多。
除此之外,文中还使用了trigram语言模型,最终的损失函数是由声学模型和语言模型相加。解码器的分类是6925个字符,当然这个只包括了单个汉字,并没有使用分词的字词,如果采用分词来做分类的话,那么种类就不止6925个了。
模型的详细参数如下:编码器由三层BLSTM组成,每个方向上包含256个神经元,所有的权重向量使用的是正态分布初始化,偏置向量使用的是零向量初始化,并且,在进行梯度消失的时候,使用了梯度截断,阈值为1。
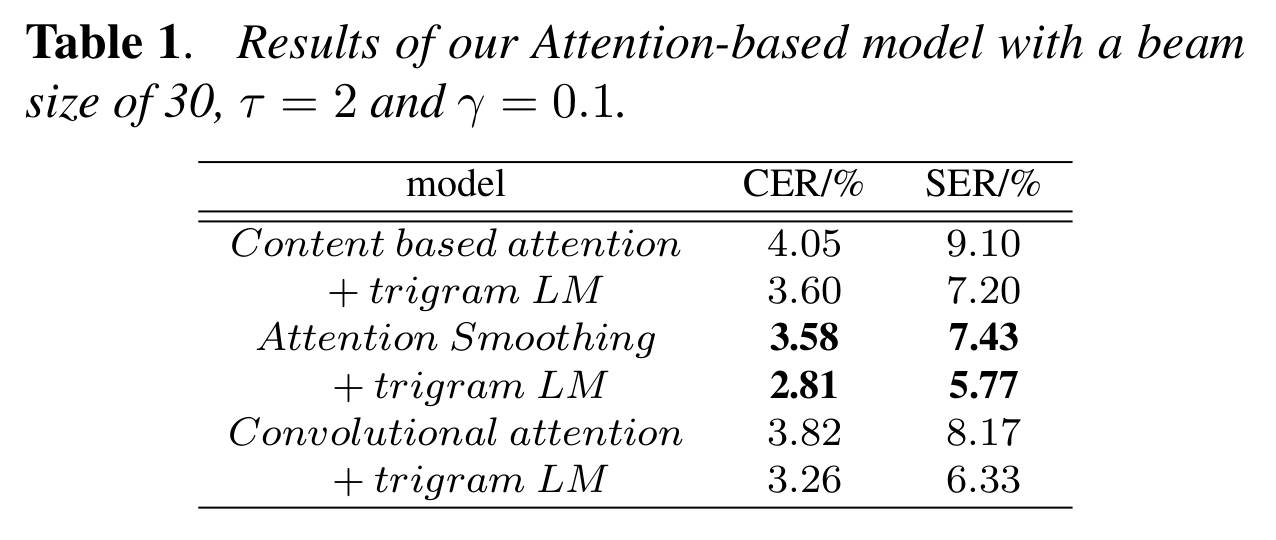
作者比较了三种不同的注意力机制,结果如下表所示,可以看到,采用了注意力平滑+trigram的语言模型表现最好。
总体而言,小米发表的这篇论文亮点不是很足,更多像一个技术报告,而且缺乏公开的数据集实验结果。但是论文传递了一个信号,那就是基于注意力机制的seq2seq模型可以在中文语音识别中成功应用。
题图:Book or Facebook?
你可能会感兴趣的文章有:
动态层归一化(Dynamic Layer Normalization)
详述DeepMind wavenet原理及其TensorFlow实现
Layer Normalization原理及其TensorFlow实现
Batch Normalization原理及其TensorFlow实现
Maxout Network原理及其TensorFlow实现
Network-in-Network原理及其TensorFlow实现
如何基于TensorFlow实现ResNet和HighwayNet
深度残差学习框架(Deep Residual Learning)
推荐阅读 | 如何让TensorFlow模型运行提速36.8%
推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)
深度学习每日摘要|坚持技术,追求原创