改善机器人模仿学习的决断力


发布人:Google 机器人团队研究员 Pete Florence 和研究工程师 Corey Lynch
尽管过去几年机器人学习取得了长足的进步,但在尝试模仿精确或复杂行为时,机器人智能体的某些策略仍然难以果断地选择操作。细想这样一项任务:机器人在桌子上滑动滑块,尝试将其精准地放入槽中。有很多可能的方法来完成这项任务,但是每一种方法都需要精确的移动和修正。机器人必须只遵从其中一个选择,还必须能够在每次滑块滑得比预期更远时改变方案。尽管人们可能认为这种任务很简单,但对于基于学习的现代机器人来说,情况往往并非如此,它们经常要学习被专家观察员描述为不果断或不精确的行为。
示例:基线显式行为克隆模型艰难地尝试完成任务,其中机器人需要在桌上滑动滑块,然后将其精准地插入固定装置中
为了让机器人变得更加果断,研究人员常常利用离散化的 (discretized) 动作空间,强制机器人选择选项 A 或选项 B,而不会在所有选项之间摇摆不定。举例来说,离散化是我们近期 Transporter Network 架构的关键元素,也是许多游戏智能体的显著成就中所固有的,比如 AlphaGo、AlphaStar 和 OpenAI 的 Dota 机器人。
AlphaGo
https://ai.googleblog.com/2016/01/alphago-mastering-ancient-game-of-go.html
AlphaStar
https://deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning
Dota 机器人
https://arxiv.org/abs/1912.06680
但是离散化有自身的局限性,对于在空间连续的现实世界里运行的机器人来说,离散化至少有两个缺点:(i) 它限制了精度,(ii) 它引发了维数灾难 (Curse of dimensionality),因为沿许多不同的维度离散可能会极大地增加内存和计算要求。与此相关的是,在 3D 计算机视觉领域,许多近期进展是由连续而非离散的表征驱动。
近期进展
https://dellaert.github.io/NeRF/
带着学习决断性策略且克服离散化缺点的目标,我们近期在 CoRL 2021 上发布了“隐性行为克隆 (Implicit Behavioral Cloning)”即隐性 BC 的开源实现。
CoRL 2021
https://www.robot-learning.org/
隐性行为克隆
https://arxiv.org/abs/2109.00137
开源实现
https://github.com/google-research/ibc
隐性 BC 是一个新的、简单的模仿学习方法,我们发现其在模拟基准任务和需要精准和果断行为的现实机器人任务上都取得了很好的结果,这包括根据我们团队最近用于离线强化学习基准 - D4RL,在人类专家任务上取得的前沿 (SOTA) 结果。在其中七项任务的六项中,隐性 BC 取得的结果优于先前最好的离线强化学习方法,即 Conservative Q Learning。有趣的是,隐性 BC 无需任何奖励信息即可取得这些结果,即它可以使用相对简单的监督学习,而不是更复杂的强化学习。
模仿学习
https://arxiv.org/pdf/1811.06711.pdf
D4RL
https://ai.googleblog.com/2020/08/tackling-open-challenges-in-offline.html
离线强化学习
https://arxiv.org/abs/2005.01643


我们的方法是一种行为克隆,可以说是让机器人从演示中学习新技能的最简单方法。在行为克隆中,智能体学习如何使用标准监督学习 (Supervised learning) 模仿专家行为。一般来说,行为克隆涉及训练显式神经网络(如下方图左所示),该网络接收观察并输出专家操作。
行为克隆
https://proceedings.neurips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf
隐性 BC 的核心思想是改为训练神经网络,同时接收观察和操作,然后输出一个比专家操作数低、比非专家操作数高(如下方图右所示)的数字,将行为克隆转变为基于能量的建模问题。在训练后,对于给定的观察,隐性 BC 策略通过查找具有最低分数的操作输入来生成操作。
基于能量的建模问题
https://arxiv.org/pdf/2101.03288.pdf
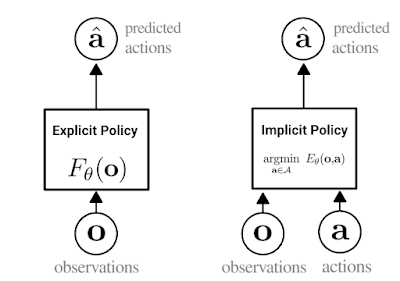
显式(左)和隐式(右)策略之间差异的描述。在隐式策略中,“argmin”表示与特定观察配对时,最小化能量函数值的操作
为训练隐性 BC 模型,我们使用了 InfoNCE loss,它训练网络为数据集中的专家操作输出低能量,为所有其他操作(如下所示)输出高能量。有趣的是,这种使用同时接收观察和操作的模型的想法在强化学习 (reinforcement learning) 中很常见,但在监督策略学习中并不常见。
隐式模型如何拟合不连续性的动画。在本例中,训练隐式模型以拟合阶跃(单位阶跃)函数。左:拟合黑色 (X) 训练点的二维图像,颜色代表能量值(蓝色表示低能量,棕色表示高能量)。中:在训练过程中能量模型的三维图像。右:训练损失曲线
阶跃(单位阶跃)函数
https://en.wikipedia.org/wiki/Heaviside_step_function
经过训练后我们发现,相对于先前显式模型在其上表现较差(如本文第一个图所示)的不连续性 (discontinuities),隐式模型特别擅长精确建模,从而产生能够在不同行为之间果断切换的新策略。
但是为什么传统显式模型行不通?现代神经网络几乎总是使用连续 (Continuous activation functions) 激活函数,比如,Tensorflow、Jax 和 PyTorch,都只附带连续激活函数。在试图拟合不连续数据时,用这些激活函数构建的显式网络不能表示不连续性,所以必须在数据点之间绘制连续性曲线。隐式模型的关键特性是它们能够表示明显的不连续性,即使网络自身仅由连续层组成。
Tensorflow
https://tensorflow.google.cn/api_docs/python/tf/keras/activations
Jax
https://flax.readthedocs.io/en/latest/flax.nn.html#activation-functions
PyTorch
https://pytorch.org/docs/stable/nn.html
我们也为这个特性建立了理论基础,尤其是通用近似 (universal approximation) 的概念。这证明了隐式神经网络可以表示的函数类别,有助于证明和指导未来的研究。
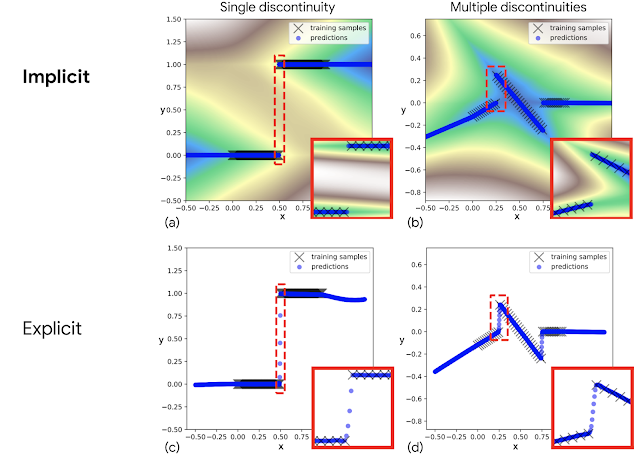
拟合不连续函数的示例,隐式模型(上图),与之相比的显式模型(下图)。红色部分突出显示的插图显示了隐式模型可表示不连续性,见 (a) 和 (b),而显式模型必须在不连续点之间绘制连续线,见 (c) 和 (d)
我们最初尝试这种方法时面临的一个挑战是“高动作维度”,这意味着机器人必须决定如何同时协调多个电机。为了扩展至高动作维度,我们使用了自回归模型或朗之万动力学。
自回归模型
https://deepgenerativemodels.github.io/notes/autoregressive/
朗之万动力学
https://arxiv.org/abs/1903.08689
在实验中,我们发现隐性 BC 在现实世界里表现得尤其好,与基线显式 BC 模型相比,隐性 BC 在 1mm 精度滑动插入的任务中表现更好(10 倍数量级)。在此任务中,隐式模型在将滑块滑动到位之前会进行几次连续的精确调整(如下)。这项任务需要多个决断性要素:由于滑块的对称性和推动动作的任意顺序,有许多不同的可能解决方案,且机器人需要在切换滑块滑动方向前,不连续地决定这个滑块何时被推到“足够”远的地方。这与连续控制的机器人的优柔寡断形成了对比。
在桌子上滑动滑块并将其精准插入槽中任务示例。这些是我们隐式 BC 策略的自主行为,仅使用图像(来自所示相机)作为输入
用于完成此任务的多种不同策略。这些是我们隐式 BC 策略的自主行为,仅使用图像作为输入
在另一项有挑战性的任务中,机器人需要按颜色将滑块排序,由于排序的任意顺序,这有大量可能的解决方案。在这项任务中,显式模型照例优柔寡断,而隐式模型表现得相当好。
在有挑战性的连续多项目排序任务中比较隐式(左)和显式(右)BC 模型。(4 倍速)
在我们的测试中,尽管模型从未看见人类的手,但即使在我们试图干扰机器人时,隐性 BC 模型还可以表现出稳健的反应行为。
尽管干扰了机器人,隐性 BC 模型仍保持稳健的行为
总体而言,我们发现在几个不同的任务域中,与目前最先进的离线强化学习方法相比,隐性 BC 策略可以获得更好的结果。这些结果包括有挑战性的任务,这些任务要么演示较少(低至 19)、具有基于图像观察的高观察维度,要么是高达 30 的高操作维度,即机器人需要配备大量的执行器。
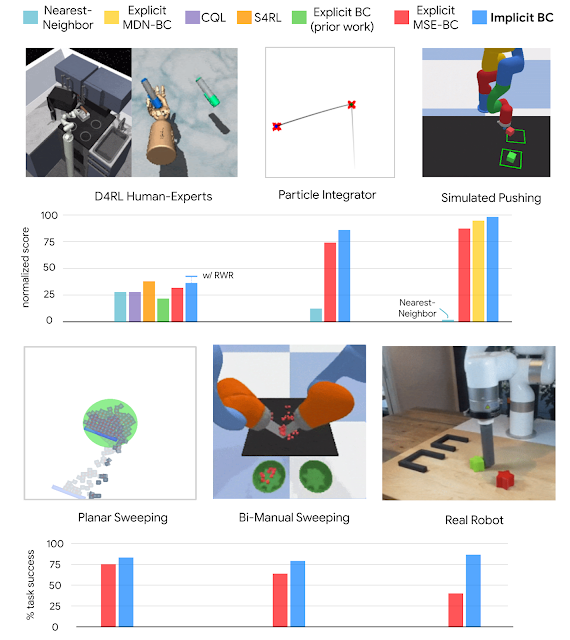
在多个域上,隐性 BC 的策略学习结果与基线相比较
尽管存在局限性,但带有监督学习的行为克隆仍然是机器人从人类行为示例中学习的最简单方法之一。正如我们在这里展示的,在机器人进行行为克隆时,将显式策略替换为隐式策略,有助于其克服“不能决断的困难”,让它们可以模仿更加复杂、更加精确的行为。虽然我们这里的重点是机器人学习,但是隐式函数对明显不连续性和多模态标签建模的能力,或许在机器学习的其他应用领域也能带来更广泛的好处。
Pete 和 Corey 总结了与其他合著者一起进行的研究:Andy Zeng、Oscar Ramirez、Ayzaan Wahid、Laura Down、Adrian Wong、Johnny Lee、Igor Mordatch 和 Jonathan Tompson。作者还想要感谢 Vikas Sindwhani 提出项目指导建议,Steve Xu、Robert Baruch 和 Arnab Bose 负责机器人软件基础架构,Jake Varley 和 Alexa Greenberg 负责机器学习基础架构,Kamyar Ghasemipour、Jon Barron、Eric Jang、Stephen Tu、Sumeet Singh、Jean-Jacques Slotine、Anirudha Majumdar 以及 Vincent Vanhoucke 提供有用的反馈和讨论。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看