让你在嘈杂环境听得更清晰,人工耳蜗搭载语音增强预处理技术


发布人:Google Research 研究员 Samuel J. Yang 和首席科学家 Dick Lyon
对于世界上约 4.66 亿失聪或听障人士而言,缺乏便利的无障碍服务可能会成为他们参与日常口语对话的阻碍。虽然助听器有助于缓解这一问题,但对许多人来说,仅放大声音远远不够。人工耳蜗 (Cochlear implant,CI) 是另一种可选方案。这是一种电子设备,可通过手术插入内耳的一个部位,即耳蜗 (Cochlea),并通过外部声音处理器对听觉神经形成电刺激。虽然许多已经植入这种人工耳蜗的人可以学会将此类电刺激当作有声语音进行理解,但不同人工耳蜗的听觉体验可能会相差甚远,在嘈杂的环境中尤其具有挑战性。
现代人工耳蜗可以通过由外部声音处理器计算出的脉冲信号(即离散的刺激脉冲)驱动电极。目前,CI 领域仍然面临的主要挑战是如何用最好的方式处理声音(将声音转换成电极上的脉冲),才能有助于用户理解。最近,为推动此问题的进展,行业内和学术界的科学家们组织了一次 CI 黑客马拉松,想要为此问题征集更多想法。
在本文中,我们分享了探索性研究,证明语音增强预处理器(特别是噪音抑制器)可以用于 CI 处理器的输入端,帮助用户在嘈杂环境中更好地理解语音内容。我们还探讨了如何利用这项成果在 CI 黑客马拉松中构建参赛作品、如何继续发展这项成果。
参赛作品
https://github.com/google-research/google-research/tree/master/cochlear_implant


2019 年,一个小型的内部项目证明了在 CI 处理器输入端进行噪音抑制的优势。在这个项目中,参与者听了 60 个预先录制并且经过预处理的音频样本,并按听觉舒适度对这些样本进行排名。CI 用户通过使用其设备中生成电脉冲的现有策略收听音频。
背景音频片段截取自 Kenny MacCarthy 拍摄的 “IMG_0991.MOV”,许可:CC-BY 2.0。
如下图所示,有噪音的语音(最浅的色条)经过噪音抑制处理后,听觉舒适度和语音清晰度通常都会提高,有时甚至会大幅提高。
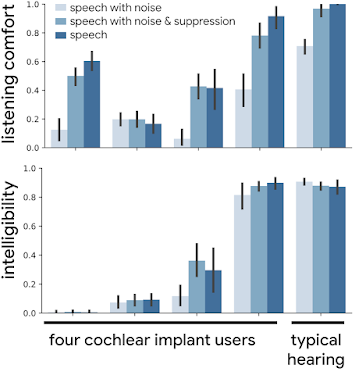
在一项早期研究中,CI 用户在试听经过噪音抑制处理的嘈杂语音样本时,听觉舒适度(定性评分从“非常差” (0.0) 到“尚可” (0.5) 再到“非常好” (1.0))和语音清晰度(即一句话中正确转录的单词占比)都有所提高。
为了参加 CI 黑客马拉松,我们在上述项目的基础上继续利用噪音抑制器,同时还探索了一种能够计算脉冲的方法。
项目的基础上
https://github.com/google-research/google-research/tree/master/cochlear_implant
黑客马拉松参赛 CI 使用了 16 个电极。我们的做法是,将音频分解成 16 个重叠的频段,与耳蜗中电极的位置相对应。接下来,由于声音的动态范围很容易跨越多个数量级,这超过了我们期望电极所代表的范围,所以我们通过应用“每通道能量归一化” (PCEN) ,积极压缩信号的动态范围。最后,用经过范围压缩的信号来创建电极描记图(即 CI 在电极上显示的内容)。
“每通道能量归一化”
https://doi.org/10.1109/ICASSP.2017.7953242
此外,黑客马拉松要求对提交的作品进行多个音频类别的评估,其中包括音乐这一重要音频类别,但众所周知,CI 用户要享受音乐可谓十分困难。然而,训练语音增强网络的目的是抑制非语音的声音,包括噪音和音乐,所以我们需要采取额外措施来避免抑制器乐声(注意,一般来说,在特定情况下,音乐抑制可能是部分用户的首选)。为此,我们将原始音频与经噪音抑制处理的音频“混合”在一起,让音乐不会遭到过度抑制,可以传达到用户耳中,让他们能够享受音乐。开源 YAMNet 分类器按照约为 1 秒的音频窗口,对输入是语音还是非语音进行估计,我们根据其结果,在 0% 到 40% 区间内实时改变原始音频的混合比例(如果所有输入的估计结果为语音,则为 0%,如果估计结果为非语音的输入更多,则为 40%)。
YAMNet
https://tensorflow.google.cn/hub/tutorials/yamnet
为了实现抑制非语音声音(如噪音和音乐)的语音增强模块,我们使用了能够分离不同类别声音的 Conv-TasNet 模型。首先将原始音频波形转换和处理成神经网络可以使用的形式。该模型通过可学习的分析转换对输入音频的 2.5 毫秒短帧进行转换,生成针对声音分离而优化的特征。然后网络根据这些特征产生两个“掩码”:一个掩码用于语音,一个掩码用于噪音。这些掩码表示每个特征与语音或噪音的对应程度。将掩码与分析特征相乘,将合成转换应用于音频域的帧,并将产生的短帧缝合在一起,以此将分离的语音和噪音重建到音频域。最后通过混合一致性层来处理语音和噪音估计值,确保它们与原始的输入混合波形相加,从而提高估计波形的质量。
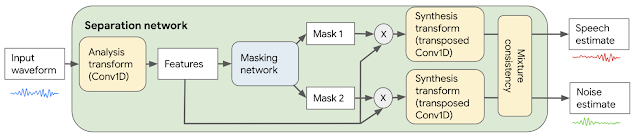
基于 Conv-TasNet 的语音增强系统方框图。
Conv-TasNet
https://doi.org/10.1109/TASLP.2019.2915167
该模型具有因果性 (Causal system) 和低延迟性:对于每 2.5 毫秒的输入音频,该模型都会生成分离的语音和噪音估计值,因此可以实时使用。在黑客马拉松中,为展示在未来硬件计算能力提高后可能实现的成果,我们选择使用一个具有 290 万个参数的模型变体。此模型的规模太大,如今无法实际应用于 CI,但它却展示了未来更强大的硬件可以实现怎样的性能。
我们优化了模型和整体解决方案,同时还使用黑客马拉松提供的声码器 (Vocoder)(需要固定的电脉冲时间间隔)来产生 CI 用户可以感知到的模拟音频。然后,针对典型听力正常的用户,我们进行了 A-B 盲听测试。
听取以下声码器的模拟结果,当输入的声音不包含太多的背景噪音时,重建声音中的语音(来自处理电极描记图的声码器)在合理范围内易于理解,然而语音清晰度仍有改进的空间。我们提交的作品在“噪音环境下的语音”类别中表现良好,并取得了总成绩第二名。
声码器模拟了 CI 用户可能从具有固定时间间隔的电极描记图的音频中感知到的情况,并应用了背景噪音和噪音抑制。
质量方面的瓶颈是刺激脉冲的固定时间间隔牺牲了音频的精确时间结构。与传统植入式刺激模式不同的是,在过滤后的声音波形中产生与峰值同步的脉冲可以捕捉到更多关于声音的音高和结构信息。
声码器模拟,使用与上述相同的声码器,但在处理过程修改后的电极描记图上,让刺激脉冲与声音波形的峰值同步。
值得注意的是,对于真正的 CI 用户而言,第二个声码器输出的音频效果可能过于乐观。例如,此处使用的简单声码器没有模拟耳蜗中的电流扩散是如何模糊刺激的,使其更难分辨不同的频率。但这至少表明,保留精确时间结构是有价值的,而且电极描记图本身并不是瓶颈。
理想情况下,所有的处理方法都将由众多 CI 用户进行评估,电极描记图将直接在他们的 CI 上实现,而不用依靠声码器模拟。
我们正计划在两个主要方向上跟进这一体验。首先,我们计划探索噪音抑制在其他听觉无障碍模态中的应用,包括助听器、转录和振动触觉感官替代。其次,我们将更深入地研究如何为人工耳蜗创建电极描记图模式,利用业界标准的常用 CIS(连续交错采样)模式所不能容纳的精确时间结构。根据 Louizou 的说法:“鉴于单渠道患者收到的频谱信息有限,他们中的部分人员如何能表现得如此出色,这仍然是一个谜。”因此,使用精确时间结构可能是改善 CI 体验的关键一步。
Louizou
https://doi.org/10.1109/79.708543
精确时间结构
https://doi.org/10.1109/TBCAS.2012.2219530
Google 致力于与残障人士协作,一同为残障人士构建技术服务。如果你有兴趣参与合作,帮助改进人工耳蜗(或助听器)的技术水平,请通过 ci-collaborators@googlegroups.com 与我们联系。
ci-collaborators@googlegroups.com
mailto:ci-collaborators@googlegroups.com
感谢人工耳蜗黑客马拉松的组织者为我们提供了此次机会,并与我们携手合作。Google 参赛团队的成员包括 Samuel J. Yang、Scott Wisdom、Pascal Getreuer、Chet Gnegy、Mihajlo Velimirović、Sagar Savla 和 Richard F. Lyon,Dan Ellis 和 Manoj Plakal 提供了指导意见。

推荐阅读



点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看