CVPR 2021 | 微软提出"解构式关键点回归", 刷新COCO自底向上多人姿态检测记录!

随着深度学习的发展,运用计算机视觉中的人体姿态估计技术已经能够高精度地从人体的图片中检测出人体关键点,并恢复人体位姿。在应用端,此技术也已经在人机交互、影视制作、运动分析、游戏娱乐等各领域大放异彩。
相比单人姿态检测,由于不知道图像中每个人的位置和总人数,多人姿态检测技术在预测图片中每个人的不同关键点所在的位置时更加困难。其困难在于:不仅要定位不同种类的关键点,还要确定哪些关键点属于同一个人。
针对这一困难,学术界有两种解决方案,一种是自顶向下的方法,先检测出人体目标框,再对框内的人体完成单人姿态检测,这种方法的优点是更准确,但开销花费也更大;另一种则是自底向上的方法,常常先用热度图检测关键点,然后再进行组合,该方法的优点是其运行效率比较高,但需要繁琐的后处理过程。
最近,也有学者采用了基于密集关键点坐标回归的框架(CenterNet)对图片中的多人姿态进行检测。此方法要求对于图中的每个像素点都要直接回归 K 个关键点的位置,虽然简洁,但在位置的准确度方面却一直都显著低于先检测再组合的方法。
而微软亚洲研究院的研究员们认为,回归关键点坐标的特征必须集中注意到关键点周围的区域,才能够精确回归出关键点坐标。基于此,微软亚洲研究院提出了一种基于密集关键点坐标回归的方法:解构式关键点回归(Disentangled Keypoint Regression, DEKR)。这种直接回归坐标的方法超过了以前的关键点热度图检测并组合的方法,并且在 COCO 和 CrowdPose 两个数据集上达到了目前自底向上姿态检测的最好结果。相关工作“DEKR: Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression”已经被CVPR 2021收录。

论文地址:
https://arxiv.org/pdf/2104.02300.pdf
代码地址:
https://github.com/HRNet/DEKR
DEKR 方法有两个关键:
1.用自适应的卷积激活关键点区域周围的像素,并利用这些激活的像素去学习新的特征;
2.利用了多分支的结构,每个分支都会针对某种关键点利用自适应卷积学习专注于关键点周围的像素特征,并且利用该特征回归这种关键点的位置。
通过以上两个技术关键,DEKR 学到的特征更加专注于目标关键点周围,因此,回归出的关键点具有很高的精度。

密集关键点回归框架对于每个像素点都会通过回归一个 2K 维度的偏移值向量来估计一个姿态。这个偏移值向量图是通过一个关键点回归模块处理骨干网络得到的特征而获得的。
解构式关键点回归(DEKR)的框架如下图所示,研究员们将骨干网络生成的特征分为K份,每份送入一个单独的分支。每个分支用各自的自适应卷积去学习一种关键点的特征,最后用一个卷积输出一个这种关键点的二维偏移值向量。在图中,为了表示方便,假设了 K=3,事实上,在 COCO 数据集的实验中,K 为17。
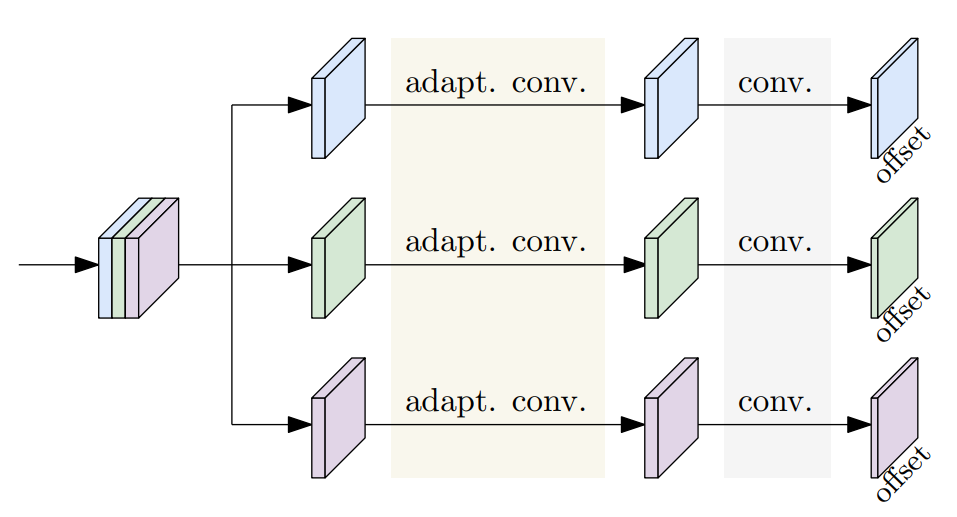
图1:解构式关键点回归(DEKR)的框架
一般来说,人体的关键点与中心点的距离比较远,一个在中心点处的普通卷积只能看到中心点周围像素的信息,而一系列在中心点处的普通卷积则可以看到更远的在目标关键点周围的像素信息,但是它不能集中地去激活这些关键点周围的像素。
因此,研究员们采用了自适应的卷积学习来激活关键点周围信息的特征。换句话说,自适应卷积就是普通卷积的加强版。
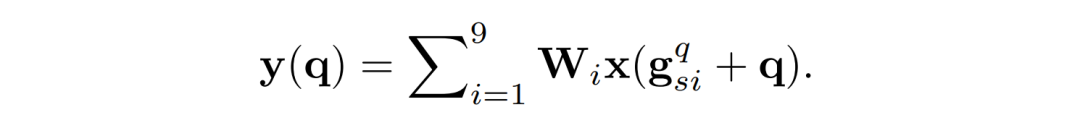
以上公式中,W 代表卷积核的权重。q 是二维的位置,g_si^q 代表了偏移量,而两者相加代表了被激活的像素点。这个偏移量可以像可形变卷积(Deformable Convolution)一样用额外的普通卷积进行估计,也可以将空间形变卷积(Spatial transformer network)从全局模式扩展到逐像素模式。
在上述选择中,研究员们采用了后者:为每个像素预测仿射变换矩阵和平移矩阵。从而将这两个矩阵作用于普通卷积的卷积核,得到自适应卷积的卷积核。
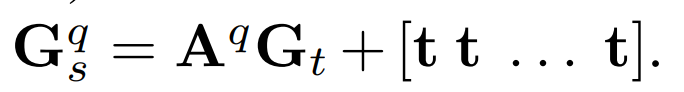
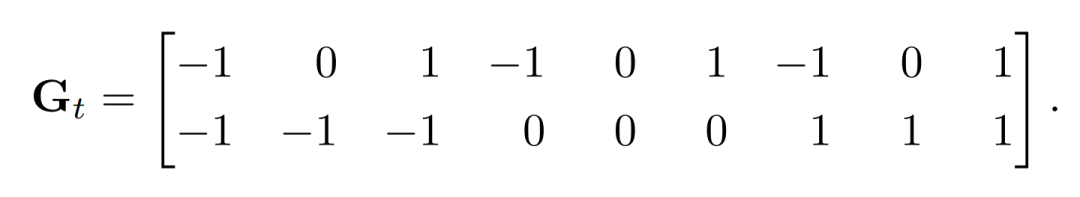
研究员们还进一步用了多分支的结构。每个分支分别用不同的自适应卷积激活对应的关键点周围的像素,然后回归出相应的关键点。研究员们将骨干网络输出的特征分成了 K 个特征,然后利用这些特征估计对应关键点的偏移值向量图。
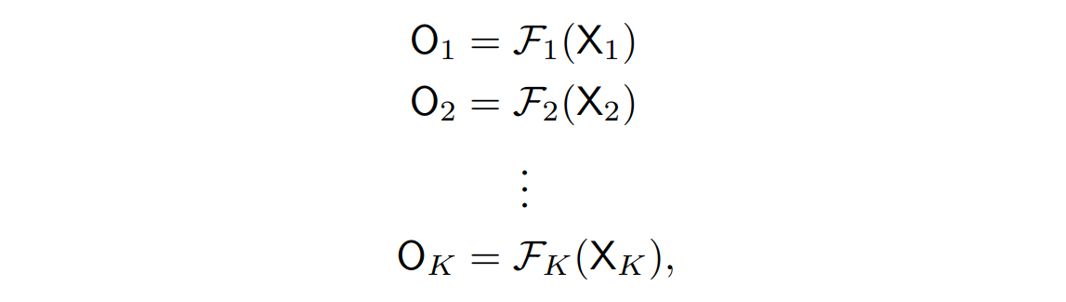
上述每个公式都代表了其中一个分支为了回归一种关键点所进行的操作。可以看出,这些分支结构相同,但是被相互独立地训练。
图2展示了鼻子、左肩、左膝、左脚踝这些关键点对应分支学到的人的中心点处自适应卷积激活的像素位置。可以观察到通过多分支的结构,每个分支都可以用其自己的自适应卷积集中激活相应关键点位置附近的像素。
通过多分支结构,研究员们显式地将特征解构分别预测了不同的关键点,这让优化变得更加容易,进而让模型可以准确地预测出关键点的位置。

图2:鼻子、左肩、左膝、左脚踝这几个关键点对应分支学到的人的中心点处自适应卷积激活的像素位置。
在损失函数方面,关键点偏移值向量图的损失函数是用人的大小来正则化的光滑 L1 损失函数。公式如下:
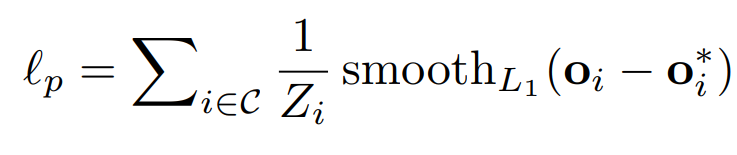
此外,在关键点和中心点热度图的损失函数设计中,研究员们还用一个独立的热度图估计分支估计了 K 张关键点热度图和一张中心点热度图,中心点热度图显示了像素是人的中心点的置信度。热度图用来给回归出的人体姿态进行打分并且排序,热度图的损失函数为加权的 L2 损失函数。
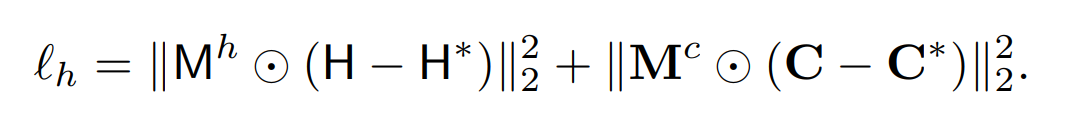
结合 L1 和 L2 损失函数就可生成总体的损失函数。具体而言就是由关键点回归的损失函数与关键点和中心点热度图的损失函数加权而成。
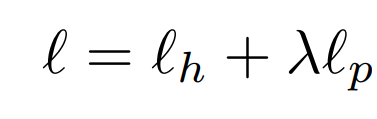
在上式中,λ 是一个权重系数,研究员们设置为0.03。
在 COCO 数据集中,研究员们首先将模型在 COCO train2017 上进行了训练,训练时使用了随机旋转、随机缩放、随机平移、随机水平翻转的增广方式,然后对于 HRNet-w32 骨干网络,将图片裁剪到512×512;对于 HRNet-w48,将图片裁剪到640×640,并用 Adam 优化器训练网络,一共训练了140回,初始学习率为 1e-3,分别在第90回和第120回降为 1e-4 和 1e-5。
随后,研究员们又在 COCO val2017 和 COCO test-dev2017 上进行了测试。在测试时,保持了图片长宽比不同,把图片的短边缩放到512/640。此外,还采用了翻转测试,将原始的热度图、关键点位置图和翻转后的热度图、关键点位置图分别做了平均。同时研究员们也尝试了多尺度测试,平均了各个尺度的热度图,并且收集了三个尺度的回归结果。
在 COCO val2017 测试集上的结果如表1所示,表中的“AE”指的是 Associative Embedding。可以看到 DEKR 在 COCO val2017 达到了很好的结果。
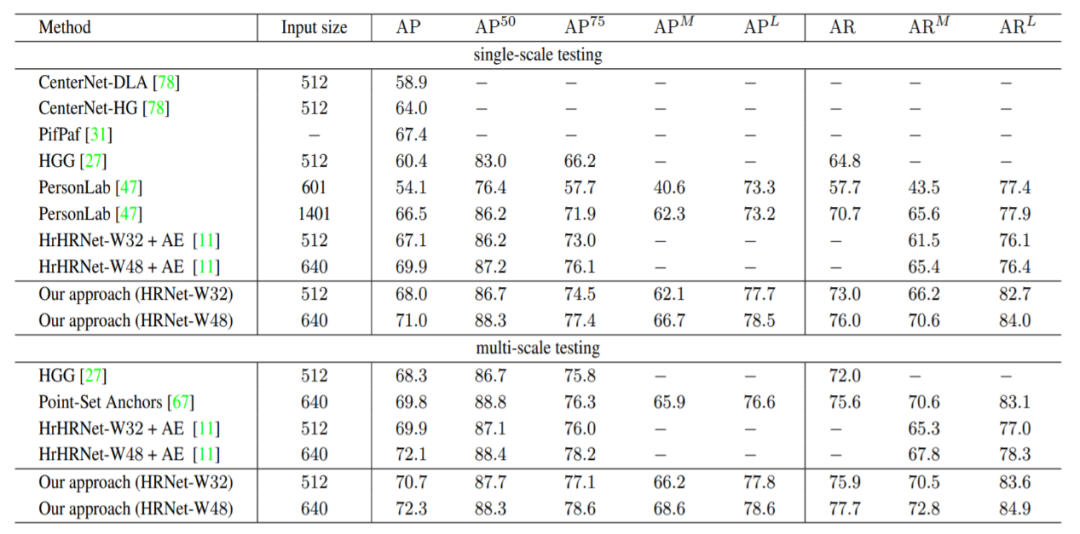
表1:在 COCO val2017 中的测试结果
在 COCO test-dev2017 上的结果如表2所示,DEKR 方法是已知第一个在 COCO test-dev2017 上仅用单尺度测试就达到了 70AP 的方法。
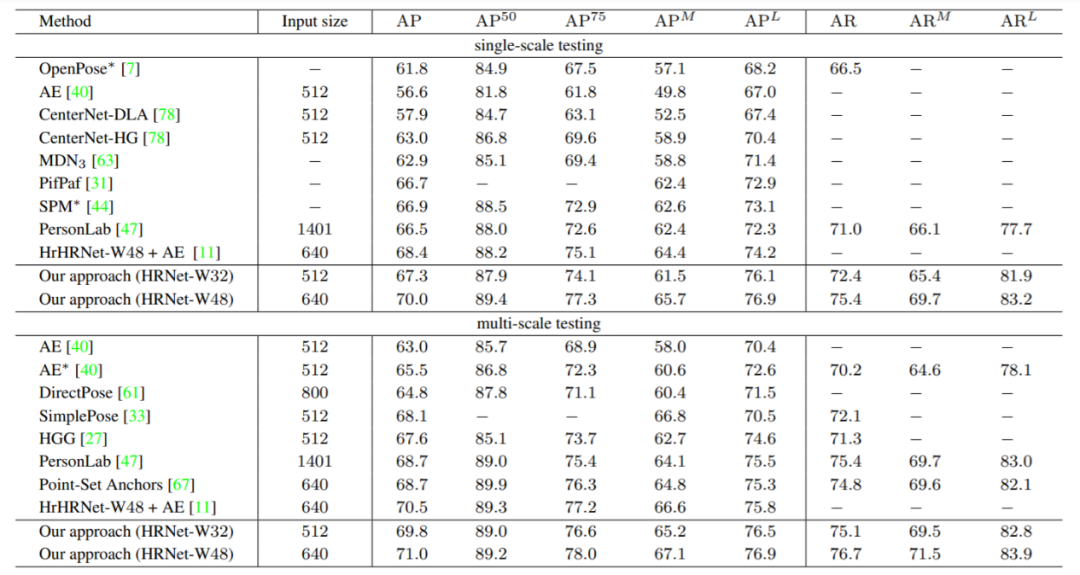
表2:在 COCO test-dev2017 中的测试结果
在 CrowdPose 数据集中,研究员们在 CrowdPose 训练集和验证集上训练了网络,训练的方法除了回合数,其余的都与 COCO 数据集完全一致。模型在 CrowdPose 数据集一共训练了300回合,初始学习率为1e-3,分别在第200回和第260回降到 1e-4 和 1e-5。
在 CrowdPose 测试集上的结果如表3所示。
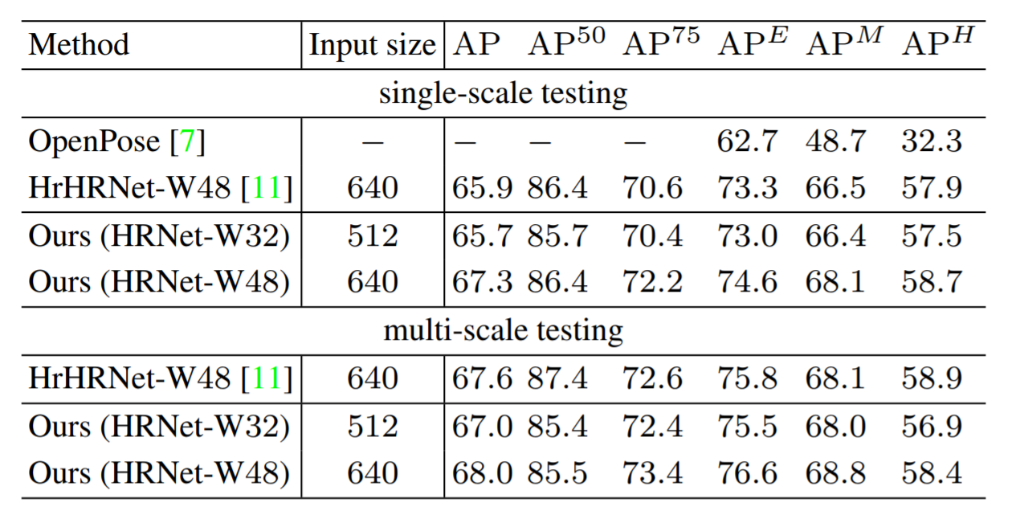
表3:在 CrowdPose 测试集中的测试结果
在消融实验中,自适应卷积在基准方法的基础上将 AP 提高了3.5,然后多分支结构进一步将 AP 提高了2.6,两者结合将基准的 AP 提高了6.1。
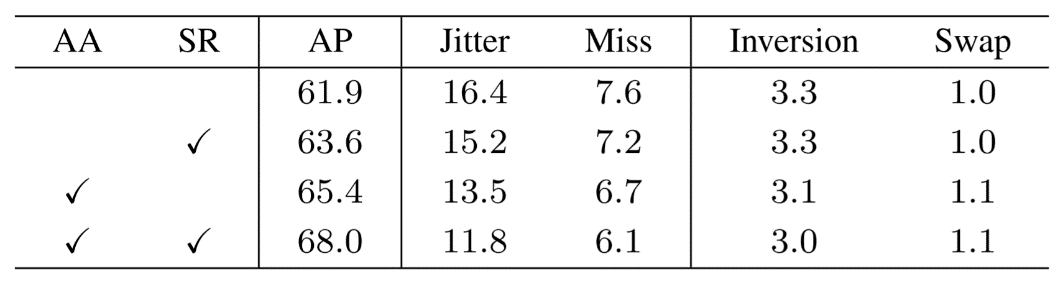
表4:消融实验结果
此外,通过错误分析工具可以看到 Jitter 和 Miss 两种错误显著减少,分别减少了4.6和1.5。这也证明了 DEKR 方法确实提高了关键点回归的位置准确度。
图3展示出了模型在回归关键点时注意到的区域,左栏为基准方法,右栏为 DEKR。为了展示得更加清楚,研究员们只用了鼻子和两个脚踝这三个关键点作为例子。从图中可以看到 DEKR 的自适应卷积和多分支结构确实让特征更加集中注意到关键点周围的区域。

图3:模型在回归关键点时注意到的区域,左栏为基准方法,右栏为 DEKR
研究员们将回归出的关键点匹配到了距其最近的从热度图检测出的关键点,这种匹配的做法对单尺度测试(ss)结果影响不大,但是提高了多尺度测试(ms)的结果。其在三个测试数据集不同的骨干网络下的结果如表5所示。
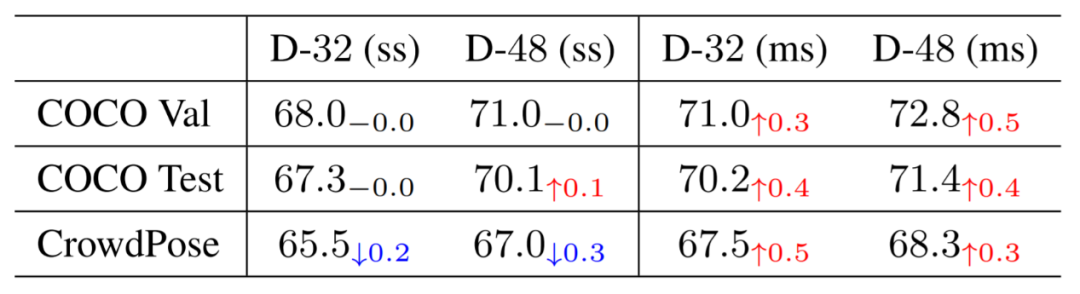
综上,DEKR 显著地提高了关键点回归的质量,并且达到了现阶段自底向上姿态检测的最好结果。DEKR 将用于回归的特征解构,这样每个特征都可以集中注意到相应关键点区域,进而更准确地回归对应关键点。
你也许还想看:






