ICCV2019 | 百度&港大提出CSVT:大规模弱标注中文场景文本数据集及一种新的弱监督端到端文本识别新方法
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文授权转载自:CSIG文档图像分析与识别专委会
作者:

本文介绍来自百度的一篇ICCV 2019论文“Chinese Street View Text: Large-scale Chinese Text Reading with Partially Supervised Learning”。该论文主要针对中文场景文字数据标注难、成本高的问题,构建一个新的大规模中文街景集合,包括部分精标注+大量弱标注的场景文字数据,同时设计全监督+弱监督的部分监督端到端文字识别算法,性能超越全监督端到端训练方法,同时大幅降低额外训练数据标注成本。对该集合进一步扩充后的ICDAR 2019-LSVT竞赛集合及榜单已开放,开发者可直接提交新结果进行榜单评测更新。
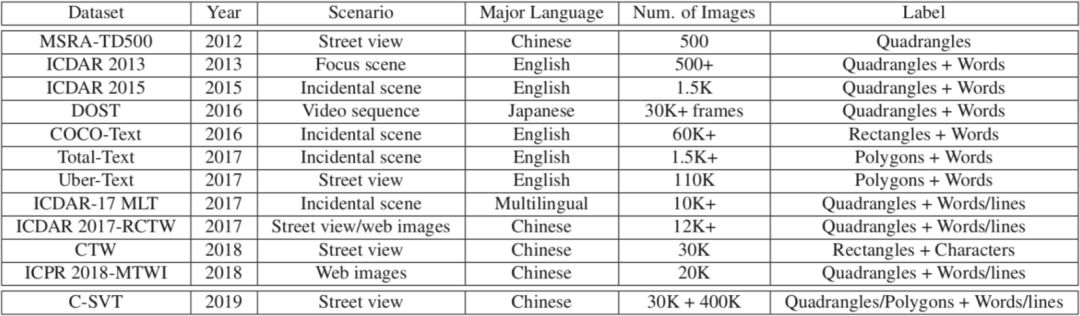
计算机视觉领域场景文字识别是重要的AI技术之一,打通了图像和文本的信息鸿沟,拥有广泛的应用场景和使用价值,近些年来受到学术界和工业界的广泛关注。现有学术界研究方法主要以研究英文文字检测识别为主,在视觉技术领域,东方文字,例如:中文场景文字识别问题尚未得到充分研究和关注。现有业界最好的文字检测识别方法应用中文文字识别场景,存在明显的性能效果损失现象。由于中文场景词表规模远大于拉丁字符类别,训练数据中大部分类别样本数量有限,同时不同类别之间存在长尾分布不均的问题,因此,中文文字识别需要更多的训练样本,具有极大的识别难度和挑战。标注困难高成本问题制约了真实场景数据的大规模扩增及数据训练。
针对上述问题,围绕中文大类别识别场景,我们引入弱标注数据的概念,针对街景场景只标注关键词信息,忽略非重要信息而无需精确位置标注,克服大量全监督训练数据标注高成本、低效率问题。
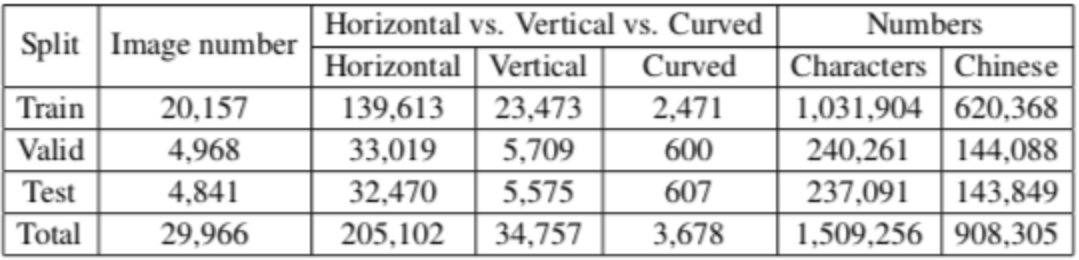
1)我们构建一个新的大规模中文街景文字数据集(C-SVT),总计43万张街景图片数据,其中包括3万张精标(标注所有文字框的位置+文字内容)和40万弱标注数据(仅标记图片中感兴趣文字内容),数据量是已有公开中文场景文字集的14倍及以上。
2)针对部分监督训练问题,本文提出一种端到端-部分监督学习算法,实现端到端中文场景文字识别。 充分利用大类弱标注数据,设计在线匹配模块在弱标注图片中定位匹配度最大的候选文字框,实现精标注、弱标注数据同时端到端训练。
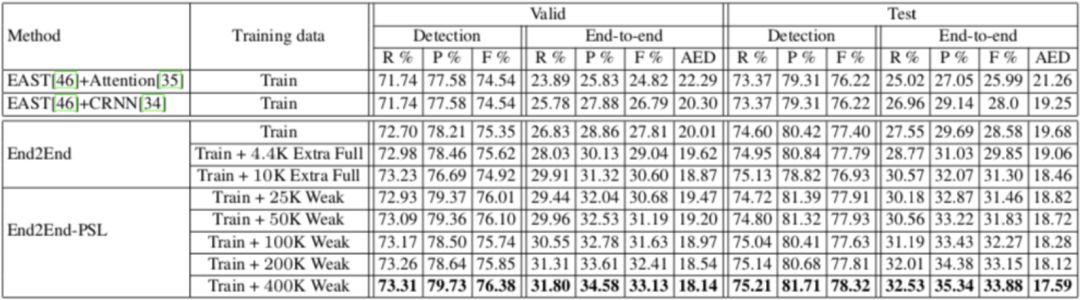
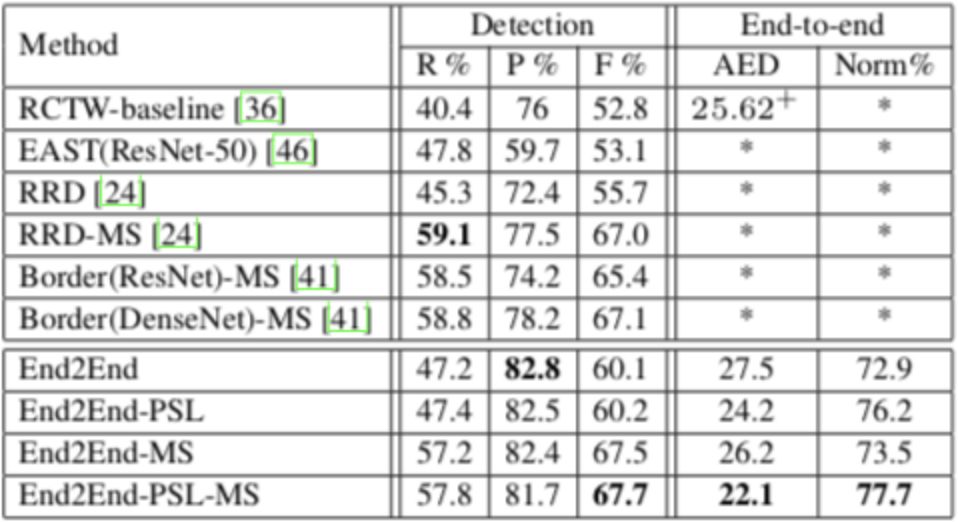
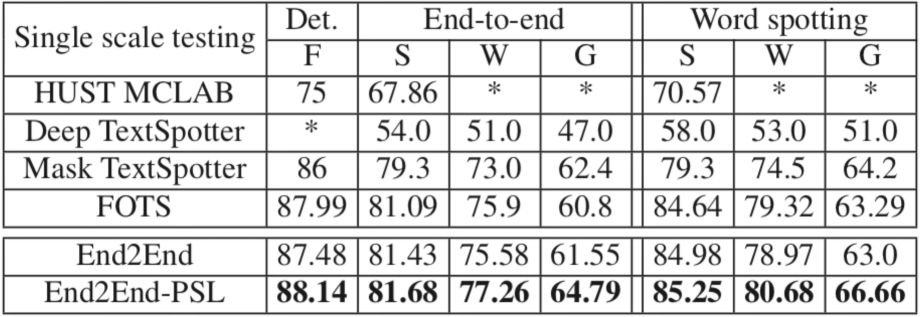
3)基于端到端-部分监督学习方法,弱标注成本是精标注的1/90。弱标注数据量从零扩增到40万,CSVT测试集上单模型平均编辑距离AED错误率相对降低20%,显著优于全监督端到端训练效果。同时,端到端部分监督学习算法ICDAR2017-RCTW中文数据集、ICDAR2015公开英文数据集上,端到端评测单模型效果取得SOTA结果。

数据集分包括3万精标注及40万弱标注数据。在完整标注部分中,所有词条的水平词条、竖直词条位置标注为四点,所有弯曲文字标注为多边形,采用多点进行位置标注。


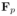 ,作为RNN+Attention序列识别分支的输入。对于弱监督数据,通过设计在线候选匹配Online Proposal Matching(OPM)分支计算给定的弱标GT文字
,作为RNN+Attention序列识别分支的输入。对于弱监督数据,通过设计在线候选匹配Online Proposal Matching(OPM)分支计算给定的弱标GT文字
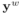 与后续区域特征的相似度,对匹配度最大的候选特征Proposal计算识别Loss,得到弱标注样本的识别分支Loss为
与后续区域特征的相似度,对匹配度最大的候选特征Proposal计算识别Loss,得到弱标注样本的识别分支Loss为
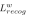 ,实现弱标注数据训练过程中的反向计算。
,实现弱标注数据训练过程中的反向计算。
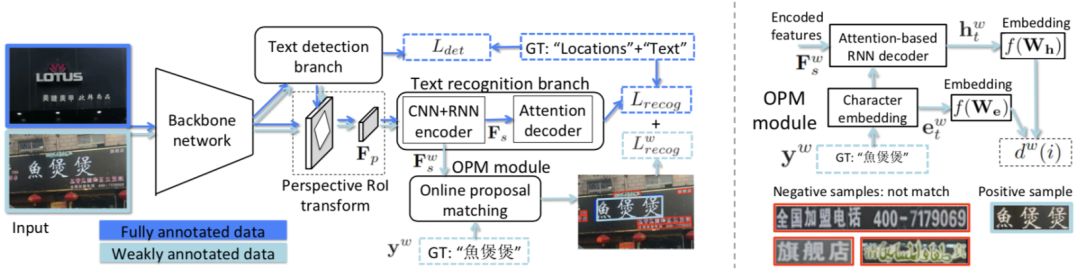
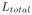 ,完成对整个部分监督训练网络Loss优化
,完成对整个部分监督训练网络Loss优化
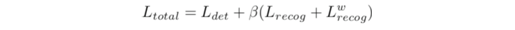


论文地址:Y. Sun, et al, Chinese Street View Text: Large-scale Chinese Text Reading with Partially Supervised Learning, in Proc. of ICCV 2019, https://arxiv.org/abs/1909.07808
[1] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens van der Maaten. Exploring the limits of weakly supervised pretraining. ECCV, 2018.
[2] Xinyu Zhou, et al. EAST: An efficient and accurate scene text detector. In Proc. of CVPR, 2017
[3] Baoguang Shi et al. ICDAR2017 competition on reading Chinese text in the wild (RCTW-17). ICDAR, 2017.
[4] Xuebo Liu et al. FOTS: Fast oriented text spotting with a unified network. In Proc. of CVPR, 2018
审校:殷 飞 发布:金连文
重磅!CVer-场景文本识别交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪&去雾&去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。一定要备注:研究方向+地点+学校/公司+昵称(如场景文本识别+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



