自然语言处理中的词表征(第二部分)

本文为 AI 研习社编译的技术博客,原标题 :
Word Representation in Natural Language Processing Part II
作者 | Nurzat Rakhmanberdieva
翻译 | 邓普斯•杰弗
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/@rakhmanberdieva93/word-representation-in-natural-language-processing-part-ii-1aee2094e08a
注:本文的相关链接请点击文末【阅读原文】进行访问

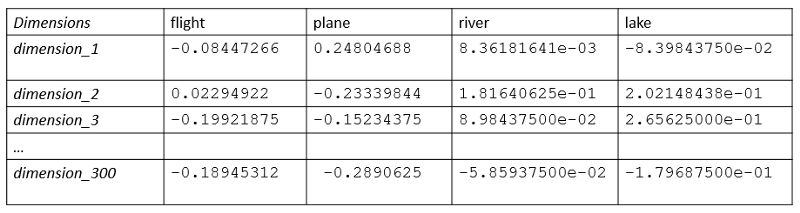
在单词表示系列的前一部分(第一部分)中,我讨论了关于不假设单词的语义(含义)和相似性的固定单词表示形式。在这一部分中,我将描述一个分布式单词表示方法家族。其主要思想是将单词表示为特征向量。向量中的每个条目代表单词含义中的一个隐藏特征。它们可以揭示语义或句法依赖性。在下面的示例中,我们看到300维的单词表示。我们可以到,“fight”和“plane”的向量值具有相似的值,且数值差异很小。同样,“river”和“lake”也有着密切的联系。
因此,这样可以产生有用的特性,例如线性关系。广泛使用的例子King对queen与和man对woman的类比,king和queen的差别几乎与向量空间中的man和woman的差别相同,这导致下面的运算是有效的。
king-queen+man与woman相近
Word2vec
分布式词表示方法中一个比较流行的是Skip-Gram模型,它也是Word2vec库的一部分。它是由Google的Tomas Mikolov领导的研究小组开发的。其主要思想是通过相邻词来表示单词。它试图预测给定单词的所有相邻单词(上下文)。
根据论文,模型的目标函数定义如下:
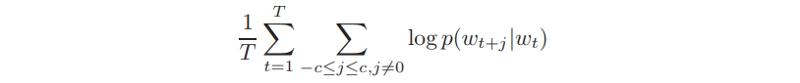
以上是Skip-Gram模型的目标函数
其中w是训练词,c是上下文的尺寸。因此,它的目标是找到能够预测上下文单词的单词表示。
可以在我们的数据集上训练Word2vec,或者加载由Google发布的由部分Google新闻数据集(大约1000亿字)的预训练向量。该模型包含300维向量,包含300万个单词和短语。见链接:https://code.google.com/archive/p/word2vec/。
这些步骤使我们能够使用来自Word2vec库的预训练向量。
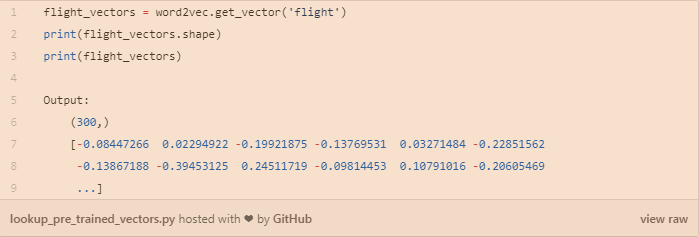
我们可以使用gensim加载预先训练的字向量,例如:

查询预先训练的向量表示,如下图所示方式:
GloVe
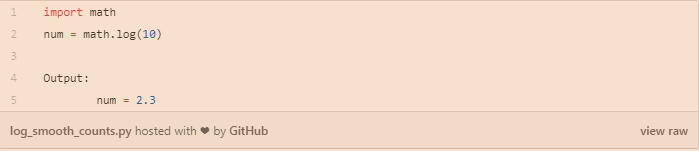
分布式单词表示的另一个代表是Glove,它是Global Vectors的缩写。虽然Word2vec捕获了某些数据一定范围的上下文,但GloVe利用了来自语料库的单词的总体共现统计信息,这是一个大量的文本集合。它包括两个重要步骤。首先,构造一个术语共现矩阵。对于每个单词,我们计算条件概率,例如,对于单词water的P(k|water),其中k是来自词汇表的单词。如果k是stream,则P值较高,如果k是fashion,则期望值较低,因为它们通常不会同时出现。在进行所有统计计算之后,形成大矩阵。然后通过归一化计数和对数平滑来降维高维上下文矩阵,如下所示。
我们仍然使用gensim来加载GloVe向量,它是使用wikipedia数据训练而来。
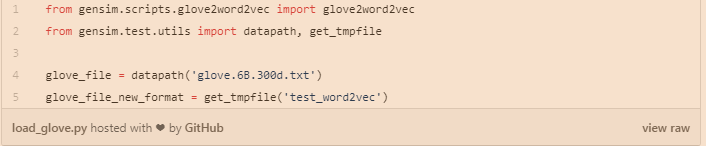
我们需要将GloVe转化为Word2vec的格式,以便可以在gensim中进行使用,例如:

更多的技术细节见链接:https://nlp.stanford.edu/projects/glove/
Glove和Word2vec都允许对相近词进行查找,这可以让我们对相近词结果进行比较。
使用Glove获得flight的相近词。
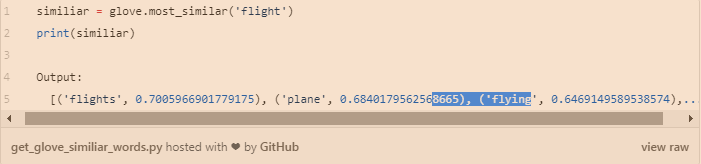
使用Word2vec获得flight的相近词。

如上所示,我们可以看到,这两个向量的输出是不相同的。不同之处在于相似性份数和单词。
在上述方法中,分布式词表示是一种强大的技术。它不会受到简单方法的不良属性的影响,并且可能将单词的语义信息合并到它们的表示中。但是,它不能为词汇表外的词生成向量。此外,对于稀有单词的向量表示的学习还不够好。在这些情况下,最好使用将在下一部分中描述的FastText模型。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1329
AI研习社每日更新精彩内容,观看更多精彩内容:
自然语言处理中的词表征(第一部分)
自然语言处理中的词表征(第二部分)
图片语义分割深度学习算法要点回顾
特朗普都被玩坏了,用一张照片就能做出惟妙惟肖的 Memoji
等你来译:
强化学习的未来——第一部分
初学者怎样使用Keras进行迁移学习
强化学习:通往基于情感的行为系统
如果你想学数据科学,这 7 类资源千万不能错过
假期也要常来【AI求职百题斩】给自己充电哦!

点击 阅读原文 查看本文更多内容↙



