“玩转标签,发现层次的力量!”:跨模态哈希方法研究

「论文访谈间」是由 PaperWeekly 和中国中文信息学会社会媒体处理专委会(SMP)联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。


论文动机
近年来,随着智能终端等多媒体设备的普及,人们可以通过图片、文字等多种模态来表征数据。相应地,跨模态检索,即给定一个查询模态(如文本),检索另一模态(如图片)的实际应用也随即产生。为了有效地处理海量多媒体数据,跨模态哈希(Cross-Modal Hashing)凭借其低廉的存储成本和查询时间成本,已被广泛应用于跨模态检索应用当中。其中,有监督的跨模态哈希方法由于很好地利用了数据的语义标签,提高了检索性能,而受到越来越多研究学者的关注。
跨模态数据往往呈现底层特征异构、高层语义相关的特点。在有监督的跨模态哈希方法中,如何利用数据标签,使数据在映射到汉明空间后,保持原始空间中的相似性关系,建立跨模态之间的关联,是需要解决的关键问题。
通常,现有的方法在处理多标签数据时,将数据的多个标签看做是独立的,简单地根据数据是否共享至少一个标签来判断它们的相似性。但是这种方法忽略了标签之间存在的语义相关关系。然而在许多实际应用场景中,例如时尚电商等领域,为了帮助用户浏览,时尚物品通常会被预先建立的类别层次结构组织起来,即每一个物品都由一组不同粒度的层次类别所标记,如下图所示。

显然,不同层次的类别从不同的角度表征了时尚物品之间的语义相似性。从最细粒度层出发,物品 I1 和物品 I3 是不相似的,分属 “Mini Skirt” 和 “Long Skirt” 两个类别。但从粗粒度层来看,它们共属于“Skirt”这个类别,因此又是相似的。
针对已有研究的局限性,作者试图通过挖掘多标签数据的类别层次结构中所传达的丰富语义信息,提高有监督的跨模态哈希方法的检索性能。
模型
作者希望利用层次标签信息来监督跨模态哈希映射的过程,使得到的哈希码更多地保留数据在原始空间中的相似性关系。具体地,作者提出了一个新颖的有监督层次跨模态哈希模型 HiCHNet,统一了层次判别性学习和正则化跨模态哈希两个主要过程,整体框架图如下所示:
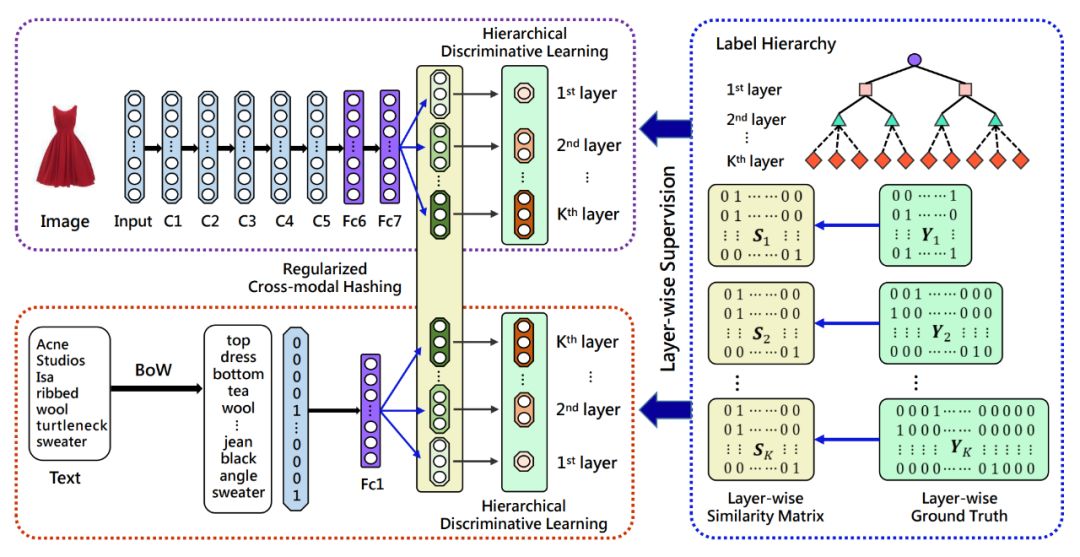
该框架由一个端到端的双路径神经网络组成。其中,每条路径分别代表一种模态。为了充分利用预先建立的标签层次结构,作者首先使用一组“分层哈希表示”来表征数据的模态特征,这些表示对应于不同粒度的类别。
基于此,作者一方面通过在每一层哈希表示上进行对应层类别的多分类操作,使不同层的哈希表示对于对应层次的类别更具有判别性;另一方面引入了层次正则化,以全面保留类别层次结构编码的语义相似性关系。这样,经过各层哈希码串联得到的目标哈希码,同时保留了层次判别性和层次语义相似性。
符号表示
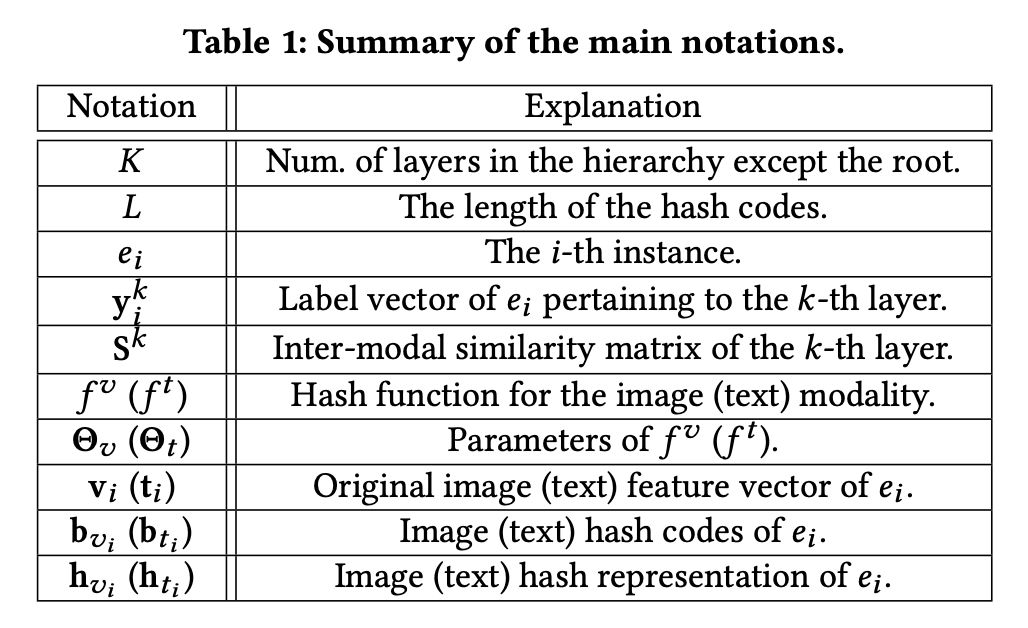
在具体介绍模型各个部分之前,作者列举了在文章中使用的各符号的指代含义,如下表所示:
分层哈希表示
作者首先利用深度神经网络来提取图片和文本特征。对于图片模态,采用 VGG-F 卷积神经网络结构来提取图片的原始特征。对于文本模态,设计全连接神经网络,提取文本特征。在获得了图片和文本特征之后,为了充分利用类别层次结构来监督哈希映射的过程,作者设计了多个全连接层,分别对应层次类别标签中的每一层。以图片或文本表示作为输入,得到图片或文本的分层哈希表示,具体公式如下:
这种哈希表示是最终哈希码的前身,通过如下符号函数,便可以得到二进制的层次哈希码。
层次判别性学习
为了全面编码类别层次结构中的语义相似信息,使获得的层次哈希码对于对应层次的类别更具有判别性。作者为两种模态分别引入了 K 个多分类网络。第 k 层分类任务以第 k 层哈希表示作为输入,第 k 层的类别标签作为真实标签。以图片模态为例,具体公式如下:
考虑到不同粒度的类别对判别性学习的贡献可能不同,作者为每一层分别设置置信度系数。最后,利用负对数似然函数(交叉熵函数)为代价函数,得到如下公式:
其中, 是第 k 层标签的置信度系数。
层次正则化跨模态哈希
在这一部分,作者采用层次正则化去保持不同模态之间的语义相似性。此外,作者还设置二值化惩罚函数来进一步增强哈希码的学习,得到更加准确的哈希码。
语义相似性保持
当数据从原始空间映射到汉明空间时,保持数据在原始空间中的语义相似关系是跨模态哈希关心的主要问题。为了实现这一点,作者根据数据在每一层上的类别关系,即在该层是否有相同的类别,建立了层次相似矩阵。层次相似矩阵的取值有 1 和 0 两种情况,分别表征数据点在对应层上的相似和不相似关系。
为了更好地在汉明空间中保持这种关系,作者希望当层次相似矩阵值为 1 时,最小化实例哈希码在该层上的汉明距离;当值为 0 时,则最大化。在模型的完整训练过程中,哈希表示可以充当哈希码的连续化代理表示。因此作者利用第 k 层的哈希表示的乘积来表明相应图片和文本在第 k 层的语义相似性,通过最大似然函数实现相似关系的保持。经代数转化,可以得到如下的目标函数:
此外,考虑到不同粒度的标签在保持相似性关系时的重要性不同,作者在上述的目标函数中再一次引入了层次置信度系数。
二值化差异惩罚
在前面的语义相似性保持的过程中,使用哈希表示作为哈希码的代理,进行了一系列的操作。除此之外,为了产生最优的哈希码代理,作者进一步计算了哈希表示与哈希码之间的二值化差异,公式如下:
综上所述,对于层次正则化跨模态哈希部分,作者得出了如下的目标函数:

值得一提的是,为了更好地弥合不同模态之间的语义鸿沟,并提高跨模态哈希的性能,在训练阶段,对于两种模态的数据,作者采用了统一的哈希码进行表示,公式如下:
联合模型与优化
在训练时,作者将上述的层次判别性学习与正则化跨模态哈希结合起来同时训练,得到最终的目标函数如下所示。其中,作者设置了一个非负平衡参数,调节上述两部分在模型中的重要性。
以上就是模型的细节内容。
实验
作者在两个具有层次标签的数据集 FashionVC 和 Ssense 上进行了实验。其中,FashionVC 为现有公开的数据集,作者对其进行了预处理,使其符合实验的要求,由 35 个层次类别标记,包含 19862 个图片-文本对;Ssense 是本文作者从时尚平台 Ssense 上爬取,经预处理获得 15696 个图片-文本对,该数据集由 32 个层次类别标记。关于数据集的统计信息如 Table 2 所示。
此外,作者采用 MAP 作为评价指标,针对两个经典的跨模态检索任务:使用文本检索图片数据库与使用图片检索文本数据库,与现有的一些经典跨模态哈希方法进行比较。其中,CCA、SCM-Or、SCM-Se、DCH 和 CDQ 属于浅层学习方法,SSAH 和 DCMH 属于深度学习方法。
1. 对于浅层学习方法,作者采用了两种特征进行实验,分别为 VGG-F 特征和 SIFT 特征。
大量实验证明,作者提出的模型在跨模态检索任务上具有一定的优越性。具体数值结果如下:
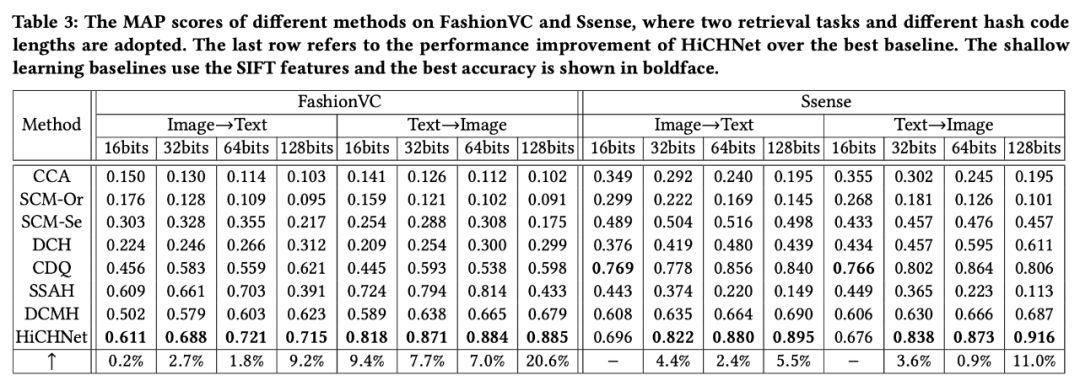
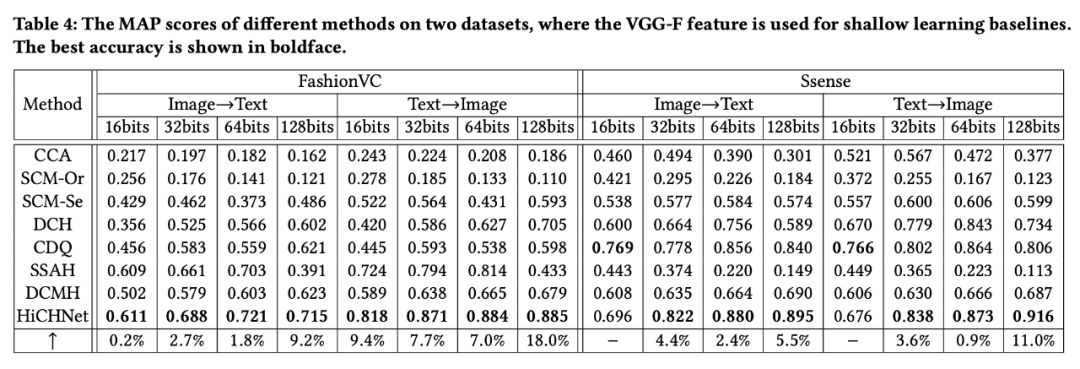
从上面两个表格可以看出,在两个数据集上,对于两种检索任务,作者所提出的模型的检索性能优于基准方法,证明了使用层次标签监督跨模态哈希训练时的优越性。
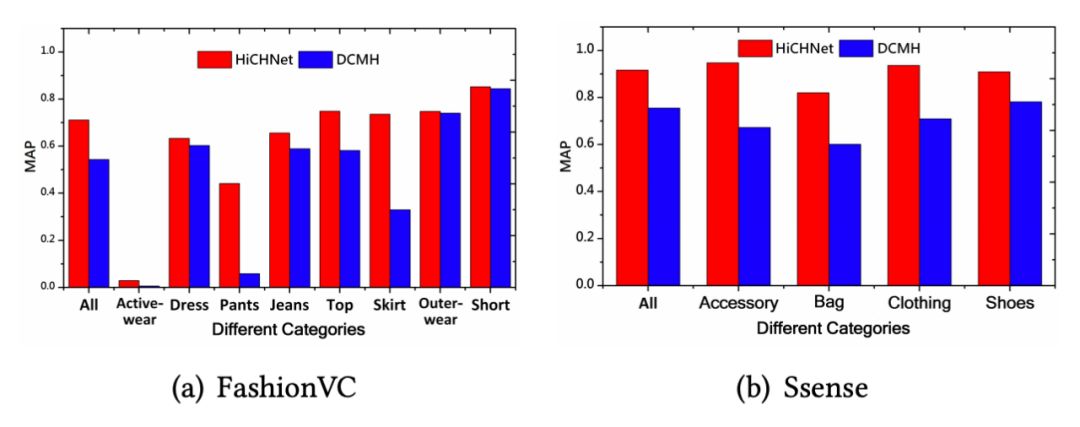
2. 为了对实验有更加深刻地理解,作者比较了 HiCHNet 与基准方法 DCMH 在两个数据集上,针对不同粒度类别的文本检索图片性能,结果如下图所示:
3. 为了观察模型的两个主要部分在模型训练过程中发挥的重要性,作者对平衡参数 γ 进行了探究。将参数 γ 的值取 0.1 作为步长,从 0.1 变化到 1,观察模型性能在数据集 Ssense 上的变化,结果如下图 (a) 所示。
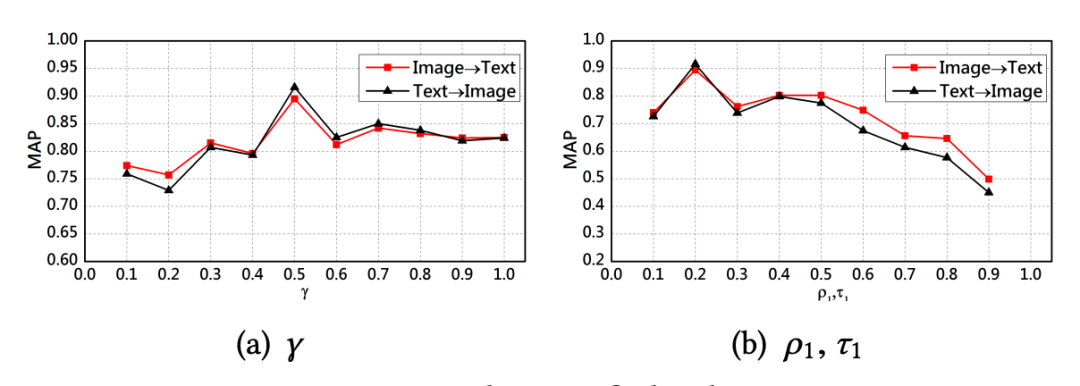
此外,作者将目标函数的两部分中的层次置信度统一起来,取 0.1 作为步长,将 ρ1 和 τ1 的值从 0.1 同时变化到 0.9,观察模型性能在数据集 Ssense 上的变化,结果如下图 (b) 所示。从图中可以发现,当 γ 值为 0.5,ρ1 和 τ1 的值为 0.2时,模型取得最优性能。
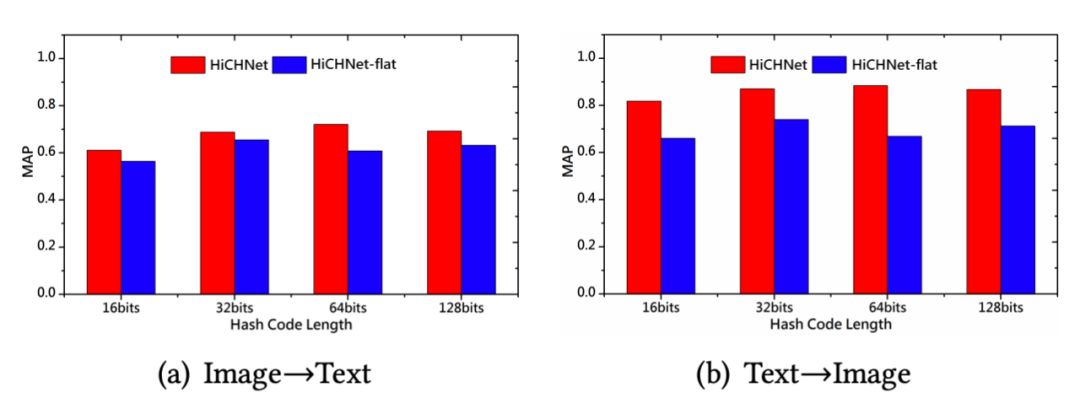
4. 为了更好地证明层次标签的有效性,作者对所提出的模型进行了简单的变形,即不再考虑层次,只保留最细粒度的类别对应的判别性学习和正则化跨模态哈希,命名为 HiCHNet-flat。并在数据集 FashionVC 上比较模型 HiCHNet 和 HiCHNet-flat 的性能,结果如下图所示。从图中可以清楚地看出,无论哈希码长度设置为多少,HiCHNet 的性能始终优于 HiCHNet-flat,这再一次验证了考虑标签层次结构的必要性。
5. 上述实验结果很清楚地表明了作者所提模型的优越性,为了得到更直观的检索结果,作者以文本作为查询输入,检索图片数据库。考虑到实验的全面性,作者采用了两种实验设置:1)在整个图片集中检索,和 2)随机抽取 10 张涉及不同类别的图片,其中包含 1 个正例图片和 9 个负例图片。
与基准方法 DCMH 作对比,列举返回 Top-10 的排序结果,上述两种设置的实验结果分别如下图所示。从第一个图中可以看出,作者提出的模型不仅返回的不相似图片(红色框标出)较少,而且不相似的图片被排在相对较后的位置。
此外,从第二个图中可以看出,本文提出的 HiCHNet 返回的图片列表与查询文本更相关。同时,可以发现与查询文本共享相同类别的层数越多的图片的排名越靠前。例如,尽管类别“Sandals”“Sneakers”、“Boots”与类别“Loafers”属于不同的细粒度类别,但由于它们拥有相同的粗粒度类别“Shoes”,因此,属于类别“Sandals”“Sneakers”、“Boots”的图片被排在类别“Eyewear”、“Backpack”、“Dress”和“Jeans”之前。


总结
针对跨模态哈希方法的研究,作者创新性地利用了数据类别标签的层次性,提出了一种端到端的有监督层次跨模态哈希。通过分层监督,更好地在汉明空间中保留了数据在原始空间中的语义相似性关系。在跨模态哈希领域,这是一篇非常值得学习的文章。
参考文献
[1] Dongqing Zhang and Wu-Jun Li. Large-Scale Supervised Multimodal Hashing with Semantic Correlation Maximization. In Proceedings of the Twenty Eighth AAAI Conference on Artificial Intelligence. 2177–2183. 2014.
[2] Yue Cao, Mingsheng Long, Jianmin Wang, and Shichen Liu. Collective Deep Quantization for Efficient Cross-Modal Retrieval. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence. 3974–3980. 2017.
[3] Xing Xu, Fumin Shen, Yang Yang, Heng Tao Shen, and Xuelong Li. Learning Discriminative Binary Codes for Large-scale Cross-modal Retrieval. IEEE Transactions on Image Processing 26, 5, 2494–2507. 2017.
[4] Chao Li, Cheng Deng, Ning Li, Wei Liu, Xinbo Gao, and Dacheng Tao. Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval. In IEEE Conference on Computer Vision and Pattern Recognition. 4242–4251. 2018.
[5] Qing-Yuan Jiang and Wu-Jun Li. 2016. Deep Cross-Modal Hashing. Computing Research Repository abs/1602.02255. 2016.
[6] Yunchao Gong and Svetlana Lazebnik. Iterative quantization: A procrustean approach to learning binary codes. In The 24th IEEE Conference on Computer Vision and Pattern Recognition. 817–824. 2011.
[7] Jingkuan Song, Yang Yang, Yi Yang, Zi Huang, and Heng Tao Shen. Intermedia Hashing for Large-scale Retrieval from Heterogeneous Data sources. In Proceedings of the ACM SIGMOD International Conference on Management of Data. 785–796. 2013.
[8] Jile Zhou, Guiguang Ding, and Yuchen Guo. Latent Semantic Sparse Hashing for Cross-modal Similarity Search. In The 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. 415–424. 2014.
[9] Zhou Yu, Fei Wu, Yi Yang, Qi Tian, Jiebo Luo, and Yueting Zhuang. Discriminative Coupled Dictionary Hashing for Fast Cross-media Retrieval. In The 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. 395–404. 2014.
[10] Zijia Lin, Guiguang Ding, Jungong Han, and Jianmin Wang. Cross-View Retrieval via Probability-Based Semantics-Preserving Hashing. IEEE Transactions on Cybernetics 47, 12, 4342–4355. 2017.
关于作者

孙畅畅,山东大学计算机科学与技术专业在读硕士研究生。2018 年取得山东大学计算机科学与技术专业学士学位。目前研究方向主要集中在信息检索领域,主攻跨模态哈希技术的研究。2019 年,在国际顶级学术会议 SIGIR 上发表一篇长文。

宋雪萌,博士,山东大学计算机科学与技术学院助理教授。2016 年 10 月取得新加坡国立大学计算机科学系博士学位。此前,于 2012 年 7 月取得中国科学技术大学,电子工程与信息科学系学士学位。研究方向主要集中在信息检索和社会网络分析等领域。在国际权威期刊和国际顶级学术会议,包括 ACM SIGIR, IJCAI, AAAI, ACM MM, ACM Transactions on Information Systems 等发表相关论文 20 余篇。此外,参与编写著作《Learning from Multiple Social Networks》与《Multimodal Learning towards Micro-Video Understanding》。担任ACM TOIS, IEEE TIP, IEEE TMM, ICMR 和 SIGIR 等国际期刊和会议的审稿人。

冯福利,新加坡国立大学计算机科学系在读博士。2015 年获得北京航空航天大学计算机科学与工程学院的学士学位。他的研究兴趣包括信息检索,数据挖掘和多媒体处理,并在 SIGIR,WWW 和 MM 等多个顶级会议上发表了超过 10 篇相关论文。此外,他在贝叶斯个性化排名上的工作获得了 WWW 2018 最佳海报奖。他还曾担任 SIGIR,ACL,KDD,IJCAI,AAAI,WSDM 等几届顶级会议的 PC 成员和审稿人。

赵鑫,中国人民大学计算机副教授,博士生导师。研究领域为社交数据挖掘和自然语言处理,共发表国内外论文 70 余篇。所发表的学术论文取得了一定的关注度,据 Google Scholar 统计,已发表论文共计被引用 2800 余次。入选第二届 CCF 青年人才发展计划。担任多个国际顶级期刊和学术会议评审以及组织工作。

聂礼强博士现任山东大学计算机科学与技术学院教授、博士生导师、山东省人工智能研究院院长。其于2009 年和2013 年分别从西安交通大学和新加坡国立大学获得学士和博士学位。之后,在新加坡国立大学从事科研工作三年半。2016 年入选“齐鲁青年学者”计划和第十三批国家“青年千人”计划。主持国家自然科学基金面上项目、重点项目、科技部重点研发课题、山东省杰出青年基金。主要研究兴趣为多媒体检索技术,近五年在国际CCF A类会议或ACM/IEEE汇刊发表论文百余篇、专著3部,Google Scholar引用5300余次,申请海内外专利30余项。担任ICIMCS 2017 程序委员会主席和Information Science 编委;担任CCF A类会议ACM MM 2018/2019领域主席;多次获得国际荣誉,如SIGMM emerging leaders in 2018、SIGIR 2019 best paper honorable mention等。
主办单位



点击以下标题查看更多往期内容:
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文

