2.5亿美元资助500个项目,美国国家科学基金会CAREER奖深度解读
本文对 NSF CISE CAREER 2022 年公开资助的一项与联邦学习相关的项目进行了分析,结合 PI 的相关研究背景,了解美国青年研究学者在该方面开展的研究工作。
美国国家科学基金会(National Science Foundation,NSF)是美国独立的联邦机构,由美国国会于 1950 年创建。NSF 的任务是通过对基础科学研究计划的资助,改进科学教育,发展科学信息和增进国际科学合作等办法促进美国科学的发展。NSF 包括以下七个方向:生物科学,计算机与信息科学工程、工程、地球科学、数学和物理科学、社会、行为和经济科学以及教育和人力资源。
教师早期职业发展计划(Faculty Early Career Development Program,CAREER)是 NSF 的一项美国国家科学基金会奖项,目的是为刚刚开始独立工作的教职人员提供足够和稳定的资金资助,使获奖者不仅能够发展成为杰出的研究人员,而且能够成为致力于教学、学习和知识传播的教育工作者。NSF CAREER 类似于中国的国家杰出青年科学基金,主要强调对教职人员早期职业生涯的支持。美国联邦颁发给青年科学家的最高荣誉科学家和工程师总统早期职业奖(Presidential Early Career Award for Scientists and Engineers ,PECASE)就是从 CAREER 获得者中选拔的。
整个 NSF 所有领域每年资助约 500 个项目,资助金额约为 $250,000,000。一个首席研究员(PI)每个年度只能申请一份 CAREER。此外,一名 PI 不得超过三次申报 CAREER,而每个 PI 只能获得一次 CAREER 资助。CAREER 是美国青年教师走入 Tenure-Track 之前一项非常重要的资助,因此,每年 NSF CAREER 公布资助的项目也能反映出相关领域最前沿、最具创新性和探索性的研究方向。本文对 NSF CISE CAREER 2022 年公开资助的一项与联邦学习相关的项目进行了分析,结合 PI 的相关研究背景,了解美国青年研究学者在该方面开展的研究工作。
1、项目介绍

联邦学习(Federated Learning, FL)研究的是在分布式网络中的边缘设备训练机器学习模型的问题。虽然联邦学习在边缘设备中展示出了巨大的应用前景,但其实际部署受到了一些竞争性限制的阻碍。除了联邦学习得到的模型准确度需要进一步提高之外,还包括需要进一步将联邦学习方法扩展到潜在的大规模设备网络中,并且保证可信赖,即解决与用户隐私、公平性和稳健性等问题相关的实用性问题。
在这个 NSF CAREER 项目中,PI 探索了多任务学习(Multi-task Learning,MTL)。MTL 是一种为网络中的每个设备学习单独但相关的模型的技术,可以用于解决联邦学习中相互竞争的限制。该项目的目标是开发适用于实际联邦网络的可扩展的多任务学习方法,并研究联邦多任务学习在准确性、可扩展性和可信度方面的基础属性。该研究将开启新一代的联邦学习系统,能够全面解决现实中联邦网络的限制。
这个项目具体聚焦于两个新的关于联邦学习的研究方向:首先,开发在大规模联邦网络中实现多任务学习的方法。其次,证明提高多任务学习的隐私性、公平性和稳健性,是实现可信联邦学习的关键。
本项目包括三个技术目标。首先,基于多任务学习的标准概念,开发并研究一系列高度可扩展的联盟式多任务学习目标。其次,分析和评估多任务学习的隐私影响,以探讨联邦网络中隐私和效用之间的权衡。最后,探索联邦学习中的公平性(在不同设备间的性能差异方面)和鲁棒性(对数据和模型中毒攻击)之间的矛盾,本项目旨在证明,多任务学习可以从本质上改善并同时实现联邦学习的公平性和稳健性。
Prof Smith 针对联邦多任务学习开展过一系列研究工作。多任务学习旨在同时解决多个学习任务,同时有效利用不同任务的相似性 / 差异性。多任务学习通常用于需要强隐私保证的应用中。例如,MTL 已被用于医疗保健领域,作为在不同人群或多个机构之间学习的一种方式;在金融预测领域,结合来自多个指标或跨组织的知识;在物联网计算领域,作为个性化联邦学习的一种方法。我们在这篇文章中对 Prof Smith 前期的研究成果进行回顾,以帮助理解和预测这个 CAREER 项目的大致研究内容。
2、相关研究情况分析
2.1 Federated Multi-Task Learning

论文地址:https://papers.nips.cc/paper/2017/file/6211080fa89981f66b1a0c9d55c61d0f-Paper.pdf
本文为 Prof Smith 在博士研究生在读期间首篇关于联邦多任务学习的文章,发表在 NeurIPS 2017 中。作者在该文中论证了多任务学习适用于解决分布式设备网络上训练机器学习模型的统计挑战问题,并提出了一种系统感知的优化方法,即 MOCHA,该方法对实际的系统问题具有鲁棒性。本文的方法和理论首次考虑了分布式多任务学习的高通信成本、stragglers 和容错问题。作者在真实世界的联邦数据集上进行了模拟实验,证明了本文方法与联邦环境中的其他方法相比,实现了显著的速度提升。
多任务学习(Multi-Task Learning,MTL)的目标是为多个相关任务同时学习模型。多任务学习的建模方法可以根据它们如何捕捉任务之间的关系大致分为两类:第一类假设任务间的聚类、稀疏或 low-level 结构是事先已知的;第二类则假设任务关系是事先未知的,可以直接从数据中学习。联邦多任务学习考虑的是第二类多任务学习方法,即任务关系事先未知。与学习单一的全局模型相比,这些 MTL 方法可以直接捕捉 Non-IID 和不平衡数据之间的关系,这使得它们特别适合于解决联邦学习的统计挑战。
联邦学习的目的是基于分布在多个节点上的数据学习一个模型。每个节点可能通过不同的分布产生数据,因此很自然地需要对分布式数据进行单独建模,即分别针对每个本地数据集构建一个模型。然而,模型间经常存在相似结构(例如,人们在使用手机时可能会有类似的行为)。因此,通过多任务学习对这些关系进行建模可以提高性能并提升每个节点的有效样本量,进而缓解单节点数据样本量不足的问题。
联邦学习直接在边缘设备上训练统计模型:
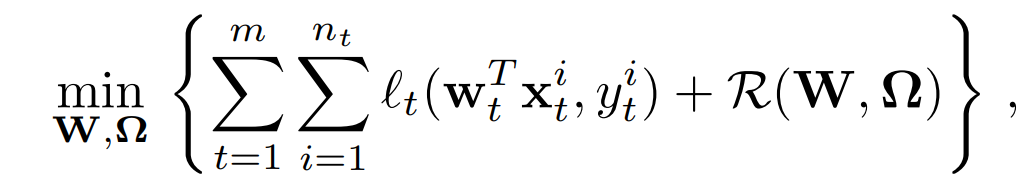
其中,矩阵 W 的第 t 列为第 t 个任务的权重向量;Ω表征不同任务之间的关系,它要么是先验已知的,要么是在同时学习任务模型时估计的。MTL 问题的不同之处在于其对 R 的假设方式:它将Ω作为输入,通过执行任务促使生成一些合适的结构。举例来说,几种流行的 MTL 方法都假定任务是根据它们是否相关而形成聚类(clusters)的。具体的,可以定义为下述双凸问题:
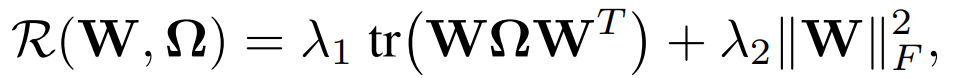
作者提出,可以在每个迭代中固定 W 或Ω,并对另一个进行优化,交替进行,直到达到收敛。本文的思路是开发一个针对 W 步骤的高效优化方法 MOCHA,算法如 Algorithm 1 所示。
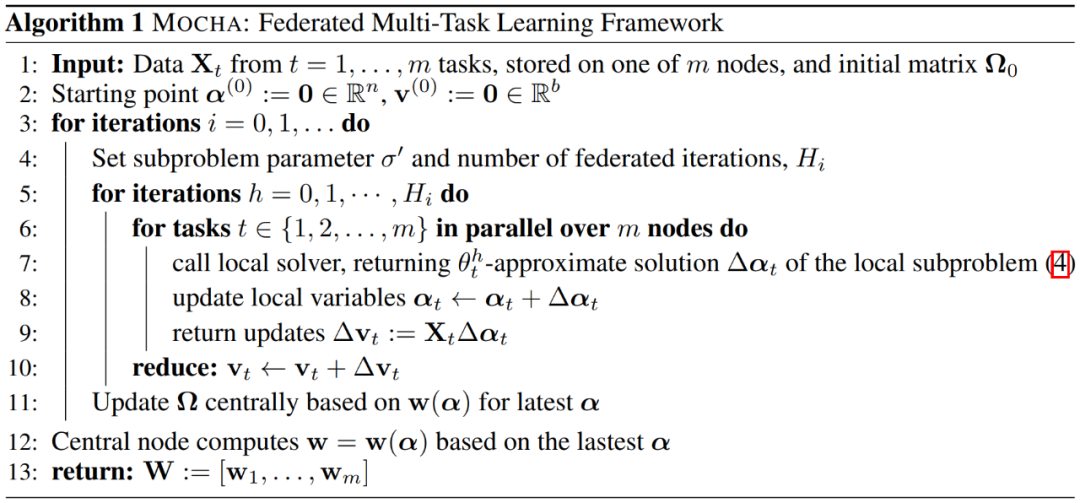
为了在联邦学习环境下更新 W,作者首先扩展了分布式原始对偶优化的工作,以适用于广义的多任务框架(公式 1),具体涉及推导出适当的对偶表述、子问题和问题参数。
对偶问题。考虑公式 (1) 的对偶形式能够更好地将全局问题分解为分布式子问题,以便在各节点上进行联邦计算。固定Ω,公式(1)的对偶问题定义如下:
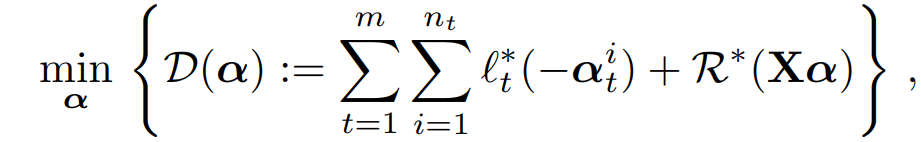
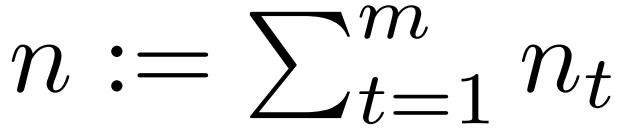

其中,(l_t)* 和 R * 为 l_t 和 R 的共轭对偶函数,(α_t)^i 为数据点 ((x_t)^i,(y_t)^i) 的共轭变量。R * 依赖于Ω。为了从这个全局对偶中推导出分布式子问题,作者对 R 做了如下假设。
假设 1。给定Ω,假设存在一个对称的正定矩阵 M,取决于Ω,对其来说,函数 R 对 M^(-1)是强凸的。这相当于假设 R * 相对于矩阵 M 来说是平滑的。
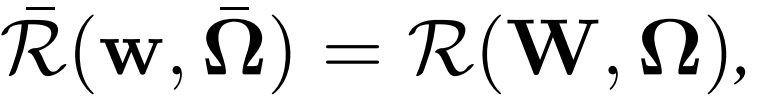
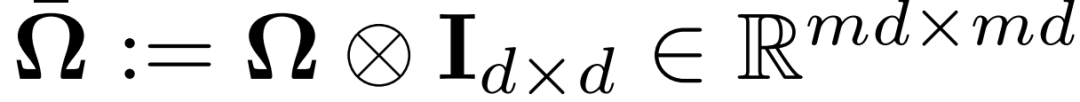
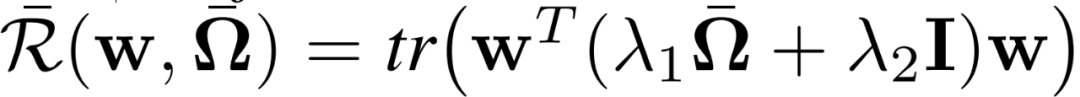
数据本地化的二次元子问题。为了解决跨分布式节点的公式 (1),作者定义了以下的数据本地化子问题,这些子问题是通过对偶问题公式(3) 的二次逼近形成的,以分离各节点的计算。这些子问题为α中对应于单个节点 t 的对偶变量寻找更新Δαt,并且只需要访问本地可用的数据。第 t 个子问题定义如下:
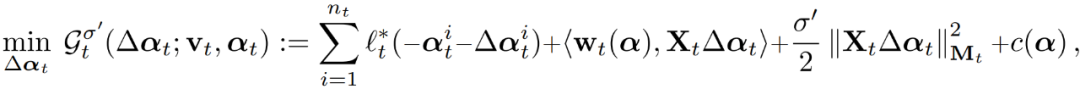
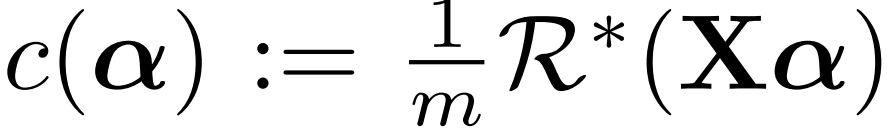
其中,M_t 是对称正定矩阵 M 的第 t 个对角线块。
在 MOCHA 的联邦更新 W 的过程中,中心节点在执行同步更新之前需要获得所有 workers 的响应。在联邦设置中,由于节点的异质性,这种通信协议的执行会带来巨大的 straggler 效应。为了避免 stragglers 问题,MOCHA 为第 t 个节点提供了近似解决其子问题的灵活性,其中,近似的质量是由每个节点的参数(θ_t)^h 控制的。以下因素决定了第 t 个节点对其子问题解决方案的质量:
1. 统计方面的挑战,如 X_t 的大小和子问题的内在困难程度;
2. 系统挑战,如节点的存储、计算和通信能力由于硬件(CPU、内存)、网络连接(3G、4G、5G、WiFi)和电源(电池水平)的原因无法保证;
3. 由中心节点规定的全局挂钟周期,指定接收更新的最后期限。
定义(θ_t)^h 为这些因素的函数,并假设每个节点都有一个控制器,其中的(θ_t)^h 取决于当前的挂钟周期和统计 / 系统设置,(θ_t)^h =0 表征子函数的精确结果,(θ_t)^h =1 表明节点 t 在迭代 h 期间没有取得任何进展(作者称其为放弃节点)。例如,如果一个节点的电池用完了,或者它的网络带宽在迭代 h 期间恶化,从而无法在当前的时钟周期内返回其更新,那么它就会 "放弃"。
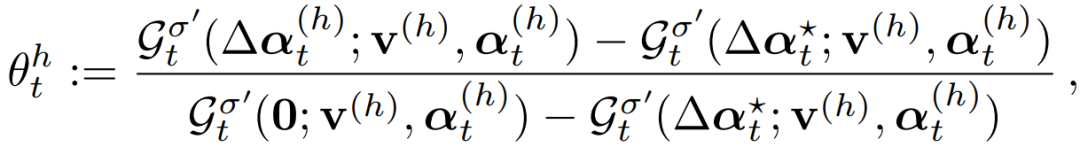
MOCHA 通过让第 t 个节点定义它自己的(θ_t)^h 来解决 stragglers。在每次迭代 h 中,一个节点在一个挂钟周期内执行和发送的本地更新来生成(θ_t)^h 的特定值。MOCHA 在适当的条件下,对一小部分节点的周期性掉线和不执行本地更新的问题具有额外的鲁棒性。
2.2 Fair Resource Allocation in Federated Learning

论文地址:https://arxiv.org/pdf/1905.10497.pdf
本文为 Prof V.Smith 关于联邦学习的公平性问题的研究成果,发表在 ICLR 2020 中。本文提出了一个新的优化目标:q-Fair Federated Learning(q-FFL),其灵感来自于无线网络中的公平资源分配,鼓励在联邦网络中的设备间进行更公平、更统一的资源准确性分配。q-FFL 最小化一个以 q 为参数的总的重新加权损失,从而确保具有较高损失的设备被赋予较高的相对权重。这一目标鼓励在联邦环境中对公平性进行设备级别的定义,通过衡量不同设备之间的性能统一程度来概括标准的准确性评价。
首先,将联邦学习的全局目标函数写作:
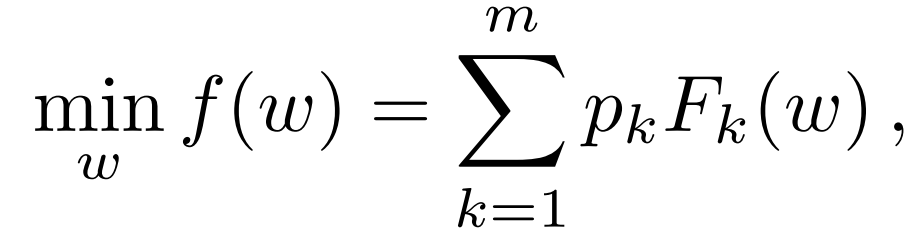
经典的联邦学习在每一轮以概率 p_k 对设备的子集进行抽样,然后在每个设备上运行一个优化器,如随机梯度下降(SGD),进行可变数量的局部迭代来解决公式(1)。经典方法的运行方式很简单,就是让每个选定的设备在本地运行 E epochs 个 SGD,然后对生成的本地模型进行平均化处理。但是,以这种方式解决公式(1)会隐含地引入不同设备之间的高度可变性能。例如,学到的模型可能会偏向于数据数量较多的设备,或者(如果对设备加权平均)偏向于经常出现的设备。
定义 1(性能分布的公平性)。对于训练好的模型 w 和~ w,如果模型 w 在 m 个设备上的表现比模型~ w 在 m 个设备上的表现更均匀,则认为模型 w 能够为联邦学习目标公式(1)提供更公平的解决方案。在这项工作中,作者引入性能分布方差作为均匀性的度量标准,目的是在保持相同(或相似)的平均准确的同时,确保更多的公平 / 统一性。
备注 2(与其他公平性定义的联系)。定义 1 针对的是设备级的公平性,它比经典的属性级公平性具有更细的粒度。在某些情况下,设备可以自然地被归类为具有特定属性的群体,我们的定义可以被看作是准确度的一个 relax 版本,因为我们优化了设备之间相似但不一定相同的性能。
本文具体的做法是:对目标重新加权给性能差的设备分配更高的权重,这样网络中的准确度分布就会更加均匀。对于给定的局部非负成本函数 F_k 和参数 q>0,将 q-FFL 的目标定义为:
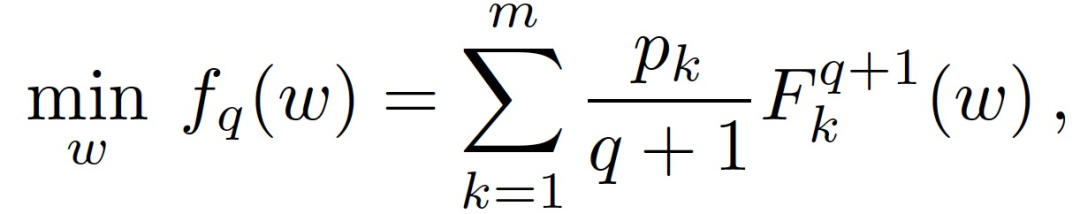
其中,q 是一个参数,用来调整我们希望施加的公平性程度。q=0 并不会实现超越经典联邦学习目标公式(1)的公平性。较大的 q 意味着我们强调具有较高局部经验损失的设备,F-k(w),从而令训练准确度分布更加均匀,并有可能按照定义 1 的要求实现公平性。设置 fq(w)时,如果 q 足够大,就会降低经典的最小公平性,因为性能最差(损失最大)的设备将主导目标。
在开发公平的联邦学习方法时,不仅要考虑目标是什么,还要考虑如何在大规模分布式网络中有效地解决这样的目标。作者在文中提供了解决 q-FFL 的方法。作者先给出了一个较简单的方法 q-FedSGD 来说明主要技术,然后通过考虑局部更新方案,给出了一个更有效的方法,即 q-FedAvg。
q-FedSGD 是联邦 mini-batch SGD(FedSGD)方法的扩展。q-FedSGD 使用动态步长,而不是 FedSGD 的正常固定步长。在 q-FedSGD 的每一步中,在当前迭代中计算每个选定设备 k 上的▽ F_k 和 F_k,并将其传输给中央节点。使用这些信息来计算步长(权重),以考虑每个设备的更新。Algorithm 1 中给出了算法细节。当 q=0 时,q-FedSGD 被简化为 FedSGD。要在不同的 q 值下运行 q-FedSGD,只需要通过调整 q=0 时的步长来估计得到一次 L,然后就可以在所有 q>0 的值下重新使用它。

在联邦环境中,使用本地随机求解器(如 FedAvg)的通信效率方案已被证明可以显著提高收敛速度。然而,当 q>0 时,由于 q+1 指数,(F_k)^(q+1)项并不是所有局部样本的损失的经验平均值,因此无法像 FedAvg 中那样使用局部 SGD。
为了解决这个问题,作者提出了一种更复杂的动态加权平均方案。权重(步长)是由 (F_k)^(q+1) 梯度的局部 Lipschitz 常数的上界推断出来的,与 q-FedSGD 类似。为了将 FedAvg 的局部更新技术扩展到 q-FFL 目标公式(2),作者提出了一个启发式方法,在 q-FedSGD 步骤中,用在设备 k 上局部运行 SGD 得到的局部更新来取代梯度▽ F_k。当 q=0 时,q-FedAvg 还原为 FedAvg。

2.3 Ditto: Fair and Robust Federated Learning Through Personalization

论文地址:https://arxiv.org/pdf/2012.04221.pdf
本文发表在 ICML 2021 中,讨论的是联邦学习中的公平性和稳健性问题。公平性和稳健性是联邦学习的两个重要问题。在这项工作中,作者发现,对数据和模型中毒攻击的稳定性和公平性(以不同设备的性能统一性来衡量)是统计学上异质网络中相互竞争的约束条件。为了解决这些限制,作者提出了一种简单、可扩展的个性化联邦学习框架 Ditto,以同时提高联邦学习的准确性、公平性和稳健性。作者认为:个性化的联邦学习方法,通过为每个设备学习不同的模型来模拟和适应联邦环境中的异质性,适用于解决联邦学习的公平性和稳健性问题。Ditto 可以被看作是标准全局联邦学习的一个轻量级的个性化插件。它适用于凸和非凸的目标,并继承了与传统联邦学习类似的隐私和效率特性。
联邦学习中的稳健性。大量研究聚焦于模型训练时的攻击问题(包括数据中毒和模型中毒)。在联邦学习中,已经针对一系列强大的攻击方法展开了研究,包括缩放恶意模型更新(scaling malicious model updates)、协作攻击(collaborative attacking) 、防御意识攻击(defense-aware attacks)以及添加边缘案例的对抗性训练样本。本文重点研究与拜占庭稳健性有关的常见攻击。
定义 1(稳健性)。本文重点关注拜占庭式的稳健性,在这种情况下,恶意设备可以向服务器发送任意的更新以破坏训练。为了衡量稳健性,评估良性设备上的平均测试性能,也就是说,如果在用攻击进行训练后,模型 w1 的平均测试性能高于 w2,我们就认为模型 w1 比 w2 对特定的攻击更稳健。
联邦学习的公平性。由于联邦网络中数据的异质性,一个模型的性能有可能在不同的设备上有很大的差异。这一问题也被称为表征差异,是联邦学习的一个主要挑战,因为它有可能导致设备的不均衡结果。
定义 2(公平性)。如果 w1 在整个网络中的测试性能分布比 w2 更均匀,我们就说一个模型 w1 比 w2 更公平。在存在恶意对手的情况下,我们只在良性设备上测量公平性。
个性化的联邦学习。鉴于联邦网络中数据的可变性,个性化是用来提高准确性的一种有效方法。作者认为本文的节 2.1 中的《Federated Multi-Task Learning》也是个性化联邦学习方法。不过,作者在这篇文章中的工作与上述方法不同,通过一个全局规则化的 MTL 框架同时学习局部和全局模型,适用于非凸目标。
经典联邦学习的目标函数可以表征如下:
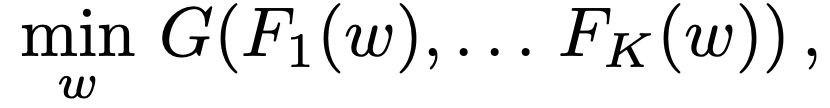
在该式中 F_k(w)为设备 k 的局部目标函数,G 表征聚合局部目标函数的函数。
为了解决设备异质性的问题,本文考虑两种方法:经典的全局目标(公式(1))和局部目标 F_k(v_k)(其目的是只用设备 k 的数据来学习一个模型)。为了将这些任务联系起来,作者引入一个正则化项,鼓励个性化的模型接近最优的全局模型。由此产生的每个设备 k 的 bi-level 优化问题由以下公式给出:
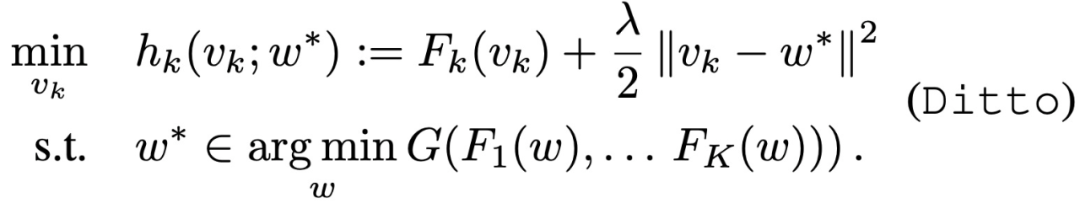
这里的超参数λ控制着局部和全局模型之间的插值。当λ设置为 0 时,Ditto 简化为训练局部模型;当λ变大时,Ditto 恢复为全局模型目标。
公平性 / 稳健性优势。除了通过个性化提高准确性,作者认为 Ditto 还可以改进公平性和稳健性。为了推理这个问题,作者考虑了一个简单的情况,即不同设备的数据是同质的。在没有恶意对手的情况下,学习一个单一的全局模型是最佳的归纳方法。然而,在有恶意对手的情况下,全局学习可能会引入 corruption,而学习局部模型可能由于样本量有限而不能很好地概括。适当的λ值提供了对这两种极端情况的权衡:λ越小,个性化模型 v_k 就会越偏离(被破坏的)全局模型 w,有可能以牺牲泛化为代价提供稳健性。在异质情况下,存在一个λ来同时保证稳健性和公平性。
其他的个性化方案。Ditto 通过减少对全局模型的依赖,个性化可以减少不同设备代表性的差异(即不公平),并有可能提高稳健性。Ditto 类似于经典的平均正则化 MTL,但它对全局模型而不是平均个性化模型进行正则化处理。
其他正则化算子。为了鼓励个性化模型 v_k 接近最优全局模型 w*,除了 L2-norm 还可以考虑其它一些正则化算子,例如,使用基于 Bregman divergence 的正则化算子或使用 Fisher 信息矩阵重塑 L2 ball。在 logistic 损失下,Bregman divergence 可以退化为 KL 散度,其二阶泰勒扩展将生成一个使用 Fisher 信息矩阵重塑的 L2 ball。作者指出,与简单的 L2 正则化目标相比,在本文讨论的应用场景中,引入近似的经验 Fisher 信息或对称的 KL 散度并不会提高性能,反而增加了计算开销。
为了解决 Ditto,作者提出 Algorithm 1 中的方法求解全局模型 w * 和个性化模型 {v_k}_k。优化工作分两个阶段进行:(i) 在整个网络中计算全局模型的更新。(ii) 求解个性化模型 v_k 以适配每个本地设备。优化 w * 的过程与联邦设置中的任意目标 G( · ) 的优化完全相同。如果我们使用迭代求解器,那么在每一轮通信中,每个被选中的设备都可以近似解决 G( · )的局部子问题(Line 5)。为了个性化处理,设备 k 在每一轮都准确地解决了全局—规则化的局部目标(Line 6)。本文的求解器可以很好地扩展到大型网络,因为与现有的 G( · )的求解器相比,它不会引入额外的通信或隐私开销。

我们注意到,解决 Ditto 目标的另一个方法是,首先获得 w*,然后对每个设备 k,对局部目标进行微调。这两种方法在强凸情况下会得出相同的解决方案。在非凸的情况下,我们观察到联合优化可能有额外的好处。从经验上看,作者发现,与从 w * 开始的微调相比,更新方案倾向于引导优化轨迹走向更好的解决方案,特别是当 w * 受到对抗性攻击破坏时。直观地说,在训练时间的攻击下,全局模型可能从一个随机的模型开始,持续优化,并随着训练的进行逐渐被破坏。在这些情况下,早期全局信息的输入(即在全局模型收敛到 w * 之前)在强攻击下可能是有帮助的。我们注意到,联合优化的 Ditto 要求设备保持本地状态(即个性化模型),并将这些本地状态带到下一轮通信中,它们会在下一轮通信中选中。用微调解决 Ditto 不需要设备是处于可用状态的,同时失去了上面讨论的交替更新的好处。
Ditto 的模块化。从 Ditto 的目标和 Algorithm 1 中,我们看到 Ditto 的一个关键优势是它的模块化特性,也就是说,我们可以很容易地使用为全局目标开发的现有技术和个性化附加的 h_k(v_k; w* )。这有几个好处:
优化。可以在算法 1 中插入 FedAvg 以外的其他方法来更新全局模型,并继承收敛的好处。
隐私。Ditto 通过网络与典型的联邦学习求解器就全局目标进行相同的信息交互,从而保留了全局目标和其各自的求解器存在的任何隐私或交流优势。这与其他大多数个性化方法不同,在这些方法中,全局模型的更新取决于本地参数,这可能会引起隐私问题。
稳健性。除了个性化固有的稳健性优势外,稳健的全局方法可与 Ditto 一起使用,以进一步提高性能。
2.4 Private Multi-Task Learning: Formulation and Applications to Federated Learning

论文地址:https://arxiv.org/abs/2108.12978
机器学习中的许多问题都依赖于多任务学习(MTL),其中的目标是同时解决多个相关的机器学习任务。多任务学习对于医疗、金融和物联网计算等领域的隐私敏感应用尤为重要,在这些领域中,共享来自多个不同来源的敏感数据以实现学习的目标。在这项工作中,作者通过联合差分隐私(JDP)明确了 MTL 的客户级隐私概念,这是一种用于机制设计和分布式优化的差分隐私。然后,作者提出了一种平均规则化 MTL 的算法,这是一种常用于个性化联合学习的目标。
本文开发并从理论上分析了具有正式隐私保证的 MTL 方法。在联邦学习应用的激励下,旨在提供客户端级别的隐私,其中每个任务对应一个客户端 / 用户 / 数据仓,目标是保护每个任务数据中的敏感信息。具体的,本文专注于确保差分隐私(differential privacy,DP),要求算法的输出对任何实体的数据变化不敏感。
对于多任务学习来说,每个客户端都会生成一个单独的模型,直接使用客户端级别的 DP 将要求所有任务的整个预测模型集对任何单一任务的私有数据的变化不敏感。但是,这一要求对大多数应用来说过于严格,因为它意味着任务 k 的预测模型必须对任务 k 的训练数据没有什么依赖性,从而影响了模型的实用性。为了解决这个问题,作者引入了 DP 的一个变体,即联合差异隐私(joint differential privacy,JDP),它要求对于每个任务 k,除 k 之外的所有其他任务的输出预测模型集对 k 的私有数据不敏感。
因此,即使所有其他客户端 / 任务串谋,共享他们的私有数据和输出模型,也能保护客户端在任务 k 中的私有数据。与标准 DP 相比,JDP 允许任务 k 的预测模型取决于 k 的私有数据,有助于保留每个任务的效用。利用 JDP,本文为 MTL 开发了新的学习算法,具有严格的隐私和效用保证。具体来说,提出了私有平均规则化 MTL(Private Mean-Regularized MTL),这是一个简单的框架,用于学习多个任务,同时确保客户端级别的隐私。
多任务学习的目的是通过联合解决和利用多个任务之间的关系来提高泛化能力。多任务关系学习的经典设置考虑了 m 个不同的任务,它们有各自的任务特定数据,通过以下目标共同学习:
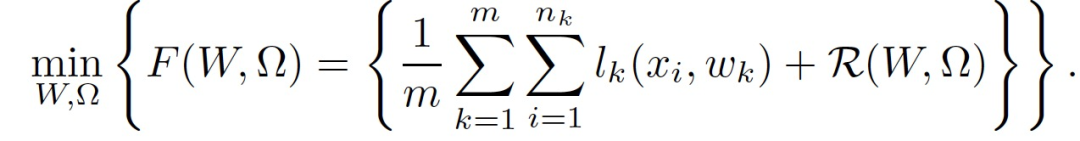
w_k 为任务 k 的模型,{x_1, ..., x_nk}为第 k 个任务的局部数据,l_k 表征经验损失,W 和Ω用于表征每个任务对的关系,例如,可以是:
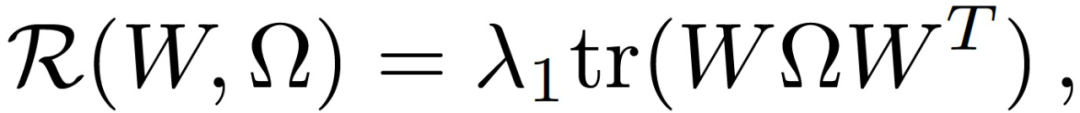
其中,Ω可以看做是共轭矩阵,用于学习 / 编码正向、负向或无关的任务关系。本文主要关注的是均值规则化的多任务学习目标。公式(1)写作:
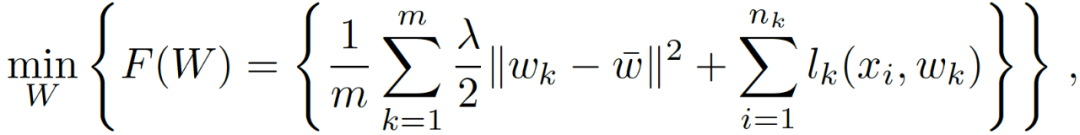
其中,w - 表征任务特定模型的均值,w - 在所有任务中共享,每个 w_k 为任务学习者 k 本地保存。在优化过程中,每个任务学习者 k 都要解决下面的问题:
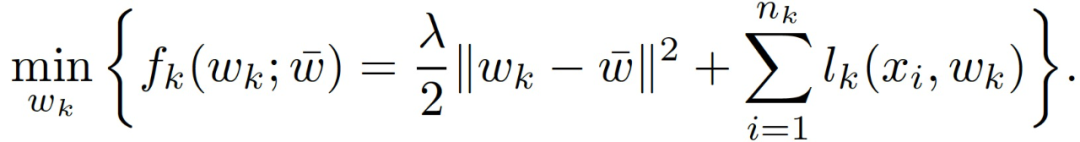
应用于联邦学习。联邦学习的目标是以保护隐私的方式在一组客户端上学习,最初的方法是在整个数据中学习一个单一的全局模型。然而,由于每个客户端的数据分布可能不同,MTL 已成为一种流行的替代方案,它使每个客户端都能够协作并学习一个单独的、个性化的自身模型。具体来说,在均值规则化 MTL 的情况下,每个客户端都会解出式(3)并利用 w_k 作为其最终的个性化模型。与全局模型的微调不同,MTL 本身通过解决目标公式(1)为每个客户端学习一个单独的模型,以提高泛化性能,这并不等同于全局模型的简单微调。尽管均值规则化多任务学习很普遍,而且最近经常用于联邦学习的场景中,但是作者表示,尚无通过解决目标公式 (2) 以正式确定客户端级差异隐私的工作。
为了考虑 MTL 的隐私,作者首先介绍了差分隐私(DP)的定义,然后讨论了如何将其扩展至联合差分隐私(JDP)。在多任务学习中,m 任务学习者拥有一个私有数据库 D_i。分别定义 D={D_1,...,D_m}和 D’={D’_1,...,D’_m},如果两个集合 D,D’ 仅在索引 i 上不同,则称其为相邻集合。
定义 1(MTL 的差分隐私(DP))。如果对于每一对仅在任意索引 i 中不同的相邻集合,以及对于每一组输出的子集满足下式,则认为随机算法 M 具有差异性的隐私性:
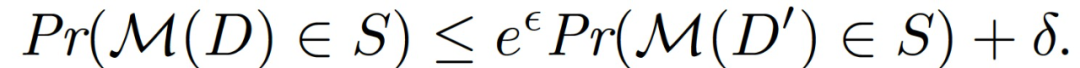
在 MTL 的背景下,一个算法为每个任务输出一个模型。本文关注客户端级别的差异隐私,其目的是保护一个任务的数据不泄露给任何其他任务。由于 MTL 的输出是一个模型的集合,传统的客户端级 DP 要求 MTL 算法产生的所有模型对任何一个客户端 / 任务的私有数据集发生的变化都不敏感。
为什么我们不能应用传统的客户级 DP?考虑到上述定义,DP 有一个严格的限制:任何任务学习者的模型也必须对其自身数据的变化不敏感,有效地使每个模型失去作用。作者将 MTL 与 vanilla 客户端级 DP 进行了比较,此外,用客户端级 DP 训练的全局模型和本文提出的使用 JDP 的 MTL 方法进行了比较,MTL 明显比其他方法差 --- 在随机猜测的情况下,MTL 只得到了微小的改善。
联合差分隐私。为了克服传统 DP 的这一局限性,作者建议采用联合差分隐私(JDP),以实现 MTL 算法的客户端级隐私保证。直观地说,JDP 要求对于每个任务 k,除 k 以外的所有其他任务的输出模型集对 k 的私有数据不敏感。作者给出了一个正式的定义:
定义 2(联合差分隐私(JDP))。如果对于每一个 i,对于每一对仅在索引 i 上有差异的相邻数据集,以及对于每一组输出的子集 S,满足下式,则随机算法 M 是联合差分隐私:
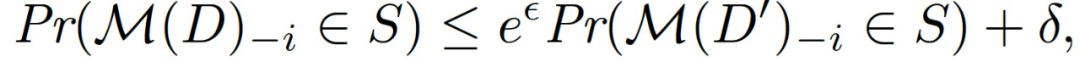
其中 M(D)-i 表示移除了第 i 个条目的向量 M(D)。
JDP 允许任务 k 的预测模型取决于 k 的私有数据,同时仍然提供强有力的保证:即使所有其他任务的客户端串谋,分享他们的信息,他们仍然无法了解任务 k 中的私有数据。作者还表示,我们可以自然地将联合微分隐私与标准微分隐私联系起来。如果我们从一个差异化的私有进程的输出中,为每个任务学习者在本地运行一些算法,而不与全局学习者或其他任务学习者交流,这整个过程可以被证明是联合差异化的私有,具体被表述为 Billboard Lemma,在下面的 Lemma 1 中提出。
Lemma 1(Billboard Lemma)。假设 M 是 (ε, δ)- 差异性私有的。考虑任意一组函数:f_i : D_i x W → W’。组合{f_i(Π_iD, M(D))} 是(ε, δ)- 联合差分私有的,其中Π_i:D→D_i 表示将 D 投射到 Di。
有了 Billboard Lemma,我们能够通过首先用所有任务的数据训练一个差异化的私有模型,然后用其本地数据对每个任务进行微调,从而获得 JDP。
备注(隐私表述的通用性)。最后,请注意,本文的隐私表述本身并不限于多任务关系学习框架。对于任何形式的多任务学习来说,每个任务的具体模型都是通过训练全局组件和局部组件的组合获得的,我们可以通过使用不同的私有全局组件为 MTL 训练过程提供 JDP 保证。
作者在算法 1 中总结了私有多任务学习的解决方法。本文方法以 FedAvg 为基础,FedAvg 是一种广泛用于联邦学习的高效通信方法。FedAvg 交替执行两个步骤:(i) 在一个通信回合中选择的每个任务学习者通过运行随机梯度下降 E 迭代来解决自己的局部目标,并将更新的模型发送给全局学习者;(ii) 全局学习者汇总局部更新并广播汇总后的平均值。FedAvg 已被证明在联邦设置中相对于 mini-batch 的 FedSGD 等基线方法,能够减少收敛所需的总通信回合数。本文的 private MTL 算法与 FedAvg 的不同之处在于。(i) 所有的任务学习者不是学习一个单一的全局模型,而是为每个任务协作学习单独的、个性化的模型;(ii) 每个任务学习者用均值规则化项解决局部目标;(iii) 去除单个模型的更新,向汇总的模型更新中添加随机高斯噪声,以确保客户端的隐私。

为了汇总每个任务的更新,假设我们可以访问一个受信任的全局学习者,也就是说,某个全局实体观察 / 收集每个任务的单个模型更新是安全的。这是联邦学习中的一个标准假设,为了收集客户端的更新,假设可以访问一个受信任的服务器。然而,即使有了这个假设,任何一个任务学习者都有可能从全局模型中推断出其他任务的信息,因为它是所有任务具体模型的线性组合,并在所有客户端之间共享。
作者介绍了几种方法克服这种隐私风险,从而实现(ε, δ)- 差异化隐私。在本文中,在全局聚合过程中使用了高斯机制,作为一种简单而有效的方法,在算法 1 的第 8 行中以红色标出。在这种情况下,每个客户端都会收到一个有噪聚合全局模型,使得任何任务都很难将私有信息泄露给其他人。为了应用高斯机制,需要约束每个局部模型更新的 l2 敏感性,如算法 1 第 8 行中的标记为蓝色的部分所示。因此,在每一轮通信中,全局学习者接收来自每个客户端的模型更新,并在聚合之前将模型更新剪切到 B。
最后,作者探讨了算法 1 所提供的隐私保证。在本文的优化方案中,对于每个任务 k,在每轮通信结束时,会收到一个共享的全局模型。之后,任务的具体模型通过优化局部目标进行更新。将该局部任务学习过程定义为 h_k:D_k x w→W。假设 W 是封闭的,定义通信回合 t 的机制为:
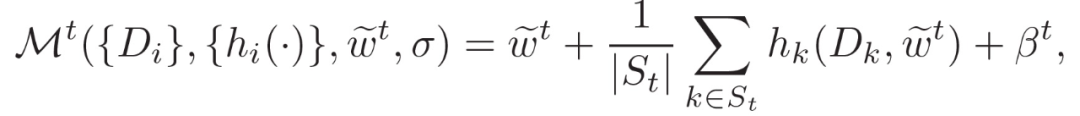
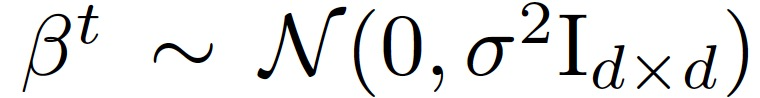
M^t 表征的是给定 w~^t 作为固定模型的采样高斯机制,而不是 j<t 的 M_j 组成的输出。为了分析算法 1 在 T 个通信回合中的隐私保证,将 M^1 与 M^T 的组合递归定义为:
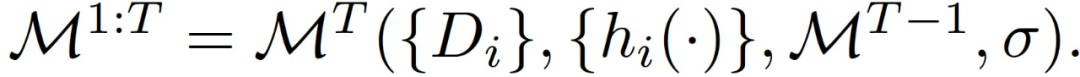
定理 1. 假设所有 t 的 | S_t|=q,通信回合总数为 T。存在常数 c_1 和 c_2 满足,对于任意ε<c_1 (q^2/m^2)T,M^(1:T)对于任意δ>0 是(ε, δ)- 差异化隐私的,需要选择:
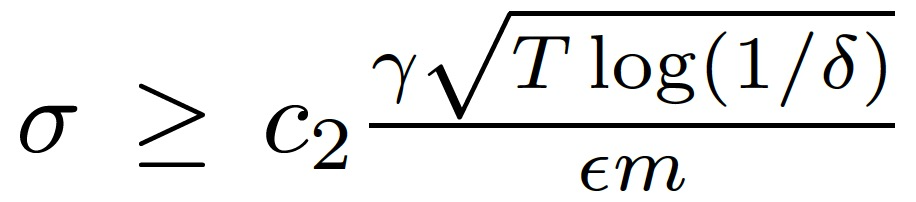
而做如下设定则有 q=m 时 M^(1:T)是(ε, δ)- 差异化隐私的:
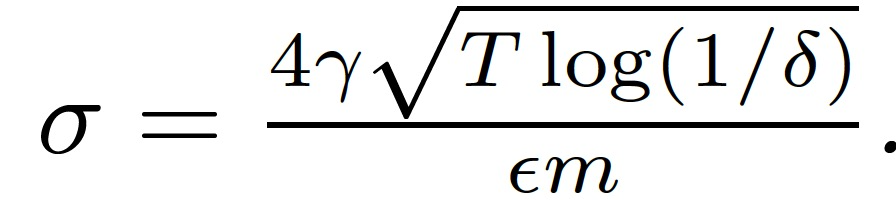
定理 1 提供了对所学模型的可证明的隐私保证。当所有的任务都参与每一轮通信时,即 q=m,算法 1 中的全局聚合步骤就简化为在平均模型更新上应用无抽样的高斯机制而不是抽样的高斯机制。
接下来作者证明,输出 m 个独立模型的算法 1 满足联合差分隐私。给定 w~^t,对于任意 t,定义每个任务学习者 k 优化其局部目标的过程 h’_k : Dk x W → W。h’_k 不被限制为 h_k,可以代表任何局部目标的优化过程。为了证明算法 1 满足 JDP,需应用 Billboard Lemma。全局学习者在每一轮通信中广播的平均模型是一个不同的私有学习过程的输出。然后,任务学习者在各自的私有数据上单独训练他们的特定任务模型,以获得个性化的模型。
定理 2. 存在常数 c_1 和 c_2 满足,对于任意 0<ε<c_1 (q^2/m^2)The δ>0,算法 1 的输出 h’_k(D_k,M^(1:T))对于任意任务来说是(ε, δ)- 差异化隐私的,需要满足:
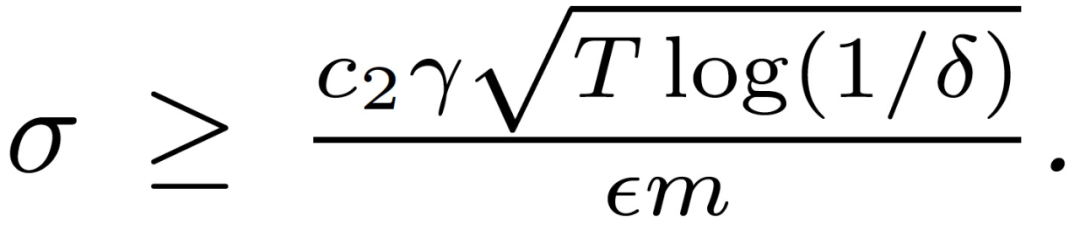
从定理 2 来看,对于任何固定的δ,参与学习过程的任务越多,为了保持隐私参数ε不变,我们需要的σ就越小。换句话说,为了保持特定任务数据的私密性,需要更少的噪声。
备注(定理 2 的通用性)。定理 2 所提供的隐私保证并不限于均值规则化 MTL。对于任何形式的具有固定关系矩阵的多任务关系学习,只要我们固定模型更新的 l2 敏感性和应用于向所有任务学习者广播的统计数据的高斯机制的噪声规模,这个聚合步骤所产生的隐私保证是固定的,无论正在优化的局部目标如何。例如,作为均值规则化 MTL 的拓展,考虑将任务学习者划分为固定的群组,并在每个群组内优化均值规则化 MTL 目标的情况。在这种情况下,定理 2 直接适用于在每个集群上运行的算法。
在这项工作中,作者定义了多任务学习的客户端级差异隐私的概念,并提出了一种简单的私有平均规则化 MTL 的方法。本文方法从理论上确保了隐私和效用。但是从经验上看,作者表明,私有 MTL 比在常见的联邦学习基准上训练一个私有的全局模型更有优势。在未来的工作中,作者计划在本文结果的基础上探索更普遍形式的 MTL 的隐私,例如,目标函数公式 (1) 中具有任意Ω的目标函数系列。此外,也会针对客户端级别的隐私与 MTL 设置中的算法公平性的关系展开研究。
2.5 Motley: Benchmarking Heterogeneity and Personalization in Federated Learning

论文地址:https://arxiv.org/pdf/2206.09262.pdf
个性化联邦学习(Personalized FL)考虑了异质网络中每个客户端特有的学习模型,由此生成的针对客户端的模型可以提高联邦网络的准确性、公平性和稳健性等指标。现在面临的主要难点包括:(1)哪些个性化技术在不同的环境中是最有效的;(2)个性化对于现实的联邦应用到底有多重要。为了更好地回答这些问题,本文提出了 Motley,一个个性化联邦学习的基准。Motley 包括一套来自不同问题领域的 cross-device 和 cross-silo 的联邦数据集,以及用于更好地理解个性化可能产生的影响的全面评估指标 。作者通过比较一些有代表性的个性化联邦学习方法,构建基准基线。Motley 旨在提供一种可重复的方法,以推动个性化和异质性感知的联邦学习,以及迁移学习、元学习和多任务学习等相关领域的发展。
首先,作者讨论了跨设备(cross-device)FL 与跨主机(cross-silo)FL。跨设备应用通常涉及在大量(如数百至数百万)移动或物联网设备上的学习。考虑到网络规模以及这些设备的不可靠性,设备通常只参与一次(如果存在的话)训练。这一特点促使人们开发出无状态的跨设备 FL 方法:即在一轮又一轮的训练中不维护每一个客户端的模型或变量状态,而且每一个客户端没有唯一的标识符。相比之下,cross-silo 的 FL 应用通常考虑在医院或学校等少数几个组织中学习,在这些组织中,客户端几乎总是在每一轮训练中都是可用的。这些特性使孤岛更容易被访问和识别,并允许使用更为复杂的有状态方法。这些差异可能会改变异质性在跨设备与 cross-silo FL 中的表现,以及最适合捕捉这种异质性的方法。因此,作者在基准中包括了跨设备和 cross-silo FL 数据集的样本,并考虑了每种情况下特有的方法和评估方案。
Motley 包括四种简单的、与模型无关的算法用于学习个性化的模型。前三种算法是无状态的,适合于跨设备的 FL 设置。
Local Training 是指每个客户端使用自己的数据训练一个本地模型,而不与其它客户端合作。虽然它不是一种 FL 算法,但作者把它包括在 Motley 中,因为它为 FL 算法提供了一个很好的基线,而且当客户端有足够的本地数据时,它可能具有竞争力。
FedAvg+Fine-tuning 是一种简单的方法,用于无状态的、与模型无关的个性化 FL。首先通过 FedAvg 训练一个全局模型;然后,每个客户端在其本地数据上对全局模型进行微调,并使用微调后的模型进行推理。它与元学习有着天然的联系,而且在现实世界的设备中应用效果良好。在 Motley 中,作者探索了两种变体形式:对整个模型进行微调或只对最后一层进行微调(后者可被视为硬参数共享 MTL 的一种形式)。
HypCluster(也是 IFCA)是一种无状态方法,它联合对客户端进行聚类,并为每个聚类学习一个模型。HypCluster 和 IFCA 的工作原理如下:在每一轮训练中,服务器将所有的模型(每个集群一个)发送给参与的客户端;每个客户端收到模型后,选择与模型相关的、在其本地数据上损失最小的集群。然后,它计算出所选模型的更新,并将更新和集群身份发送给服务器。服务器以与 FedAvg 相同的方式汇总每个集群的模型更新。在 Motley 中,作者探索了两种初始化策略:随机和与 FedAvg 的 warm start。
多任务学习(MTL)是一类用于通过学习任务关系(显性或隐性)为一组任务提供个性化模型的方法。每个 "任务" 对应于 FL 设置中的一个客户端。MTL 方法通常要求客户端是有状态的,因此,更适合于 cross-silo 的设置。Motley 考虑了两种 MTL 算法:1)MOCHA(节 2.1),第一个提出在凸环境中个性化联邦模型的工作;2)Ditto(节 2.3),将个性化模型规整为凸和非凸问题的最佳全局模型。
表 1 给出了本文选择的数据集,以反映现实世界的 FL 应用。所有的数据集都有每个用户的自然分区和独特的局部统计(图 1)。Motley 为所有数据提供了数据预处理管道,并包括一个关键的、预处理跨设备与 cross-silo 数据之间的区别(如下所述)。
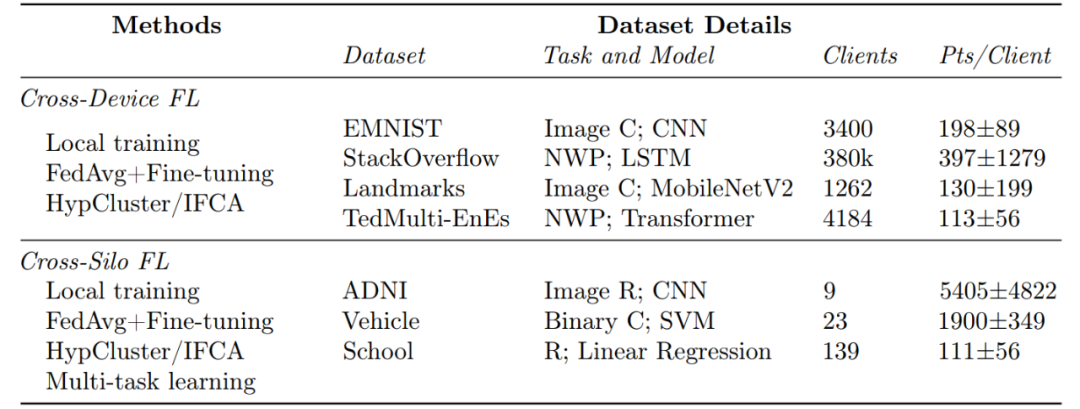
表 1. Motley 有三个组成部分。(1) 四种有代表性的个性化 FL 算法的模块化实现;(2) 各类任务(C:分类;R:回归;NWP:下一个词的预测)和数据集,以涵盖跨设备和 cross-silo FL 设置;(3)通过广泛的超参数调整的基线结果以及从这些结果中得到的启发。最右边一栏是每个客户端的平均例数 ± 标准偏差。

图 1:左边:所选择的联邦数据集(表 1)具有异质性的局部分布。右图。为了最好地反映现实世界中的 FL 应用,对跨设备和 cross-silo 数据集进行预处理。跨设备数据集的预处理方式不同:在跨设备中,把客户端分成训练 / 验证 / 测试;在 cross-silo 的场景中,把每个客户端的本地数据集分成训练 / 验证 / 测试集。
预处理跨设备的数据集。在跨设备环境下评估个性化算法需要两个步骤。首先,将客户端随机分成三个不相干的集合:训练、验证(用于超参数调整)和测试(用于最终评估)。这种分割反映了实际的跨设备 FL 设置:考虑到人口规模(例如,数百万的移动设备),参与训练的设备通常与参与推理的设备不同。其次,将每个验证和测试客户端的本地样本分成两个同等大小的集合:一个个性化集合和一个评估集合。具体来说,个性化集合用于训练本地模型,微调 FedAvg 训练的模型,或选择最佳 HypCluster 模型。在 StackOverflow 上,在拆分前按时间对本地样本进行排序。
预处理 cross-silo 数据集。与跨设备 FL 不同,在预处理 cross-silo FL 的设置中,silo 的总数很少,而且相同的 silo 通常参与训练和推理。为了评估这种设置,作者把每个 silo 的本地样本分成三组:训练组、验证组和测试组。
与前四篇文章不同,Motley 主要是提供了一个可重复的、端到端的实验管道,包括数据预处理、算法、评估指标和调整的超参数。这篇文章的工作提出了未来工作的几个方向,如:
“最佳”方法(或同一方法的 "最佳" 超参数)的概念可以根据评价指标或设置而改变。因此,一个关键的方向是为个性化的 FL 开发系统的评价方案(即,仅有平均准确度是不够的)。
现有的文献往往忽略或混淆了在真实世界环境中部署个性化 FL 算法的实际复杂性。设计新的实用的个性化 FL 方法,考虑到这些因素,是 FL 发展的一个重要方向。
开发训练和解释聚类方法(如 HypCluster)的技术,不存在 mode collapse,是使这些方法在实践中更加有效的必要步骤。
使客户端的个性化模型适应当前的局部分布和泛化到未来的分布之间存在权衡,值得进一步地探讨。
鉴于在跨客户端 FL 中观察到的每个客户端超参数调整的好处,在 cross-silo FL 中开发类似的、可扩展的超参数调整方法可能是有效的。
作者希望 Motley 能够激发针对其他评价指标基准的研究,如隐私、其他公平性概念和稳健性,以及其他数据集和应用。
3、文章小结
根据已公布的项目摘要,NSF CAREER 这个项目的主要任务包括开发可扩展的联盟式多任务学习目标函数、讨论联邦学习环境中隐私和效用间权衡以及公平性和鲁棒性的权衡这三个方面,目标是满足实际环境中联邦学习的应用需求,克服现有的问题。
我们在这篇文章中回顾了 Prof V.Smith 在之前工作中提到的多任务学习、资源分配以及公平性和鲁棒性的研究成果,还包括一个能够提供客户端级别隐私保护的 MTL 方法,理论上保证了联邦学习的隐私和效用,以及一套基准方法 Motley。可以看出,Prof V.Smith 在这个方向已经有了一定的研究基础。我们期待随着项目的不断深入,能够更多的考虑实际部署过程中遇到的竞争性问题,推动相关方法的实际应用。
作者简介
Jiying,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。

