来自商汤、西安交通大学等机构的研究者提出了一种通用感知架构 Uni-Perceiver ,该方法可以更好地将预训练中学到的知识迁移到下游任务中。
人脑可以整合不同模态的信息,并同时处理各项任务来感知世界。相比之下,当前机器学习研究者多是为不同的任务开发不同的模型和算法,并在特定于任务的数据上进行训练。然而,这种特定于任务的方法会大大增加为新任务开发模型的边际成本,无法满足快速增长的应用场景的需求。
本文的研究者们希望提出一种通用感知架构,通过在多模态大规模数据上进行预训练得到良好的表征,并对不同下游任务使用同一套预训练参数;在应用于下游任务时,模型无需额外数据,或仅需少量的数据即可达到良好的效果。研究者们的核心想法是将不同模态的数据编码到统一的表示空间中,并将不同任务统一为相同的形式。这种统一的设计鼓励了不同模态和任务在表示学习中的协作,并且可以更好地将预训练中学到的知识迁移到下游任务中。由于任务形式的统一,该模型甚至可以对预训练阶段没有见过的新任务进行 zero-shot 推理。
基于此想法,
来自商汤、西安交通大学等机构的研究者们提出了 Uni-Perceiver
。
![]()
论文地址:https://arxiv.org/pdf/2112.01522.pdf
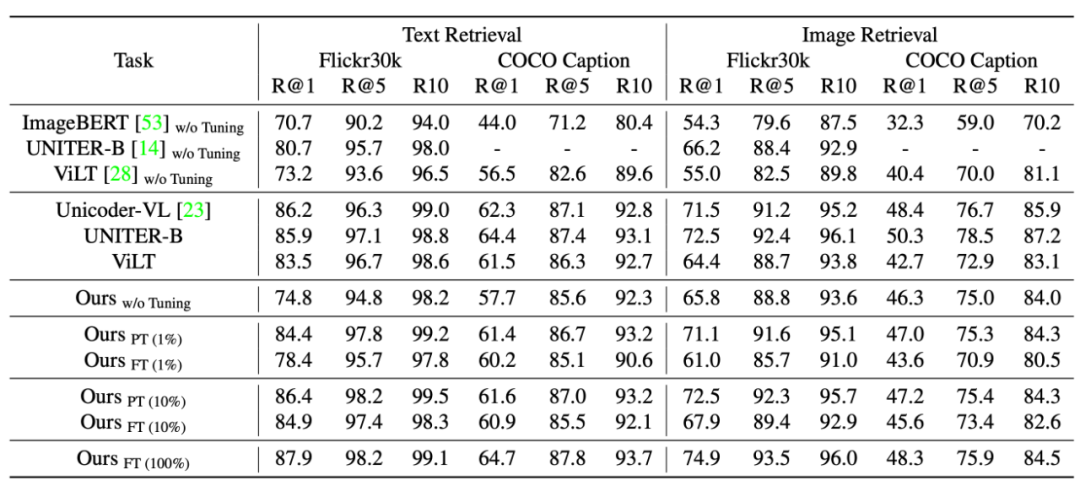
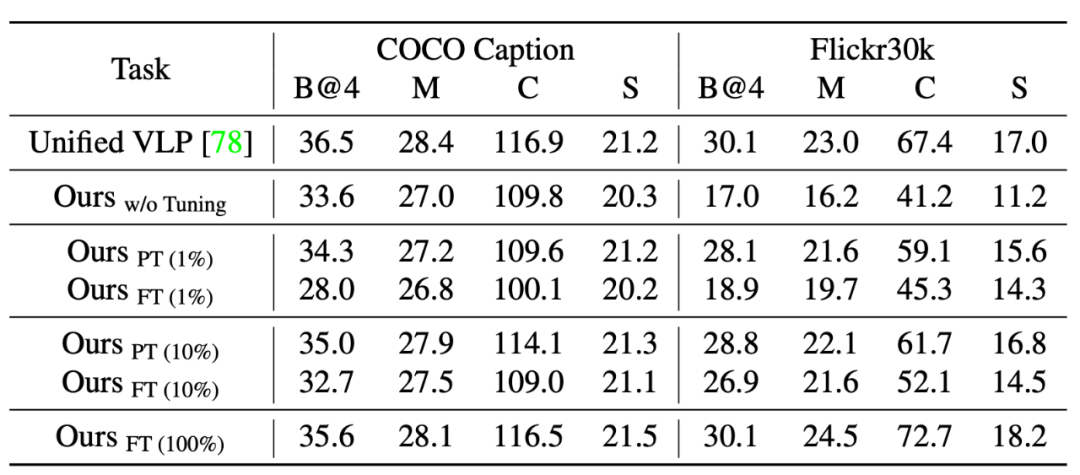
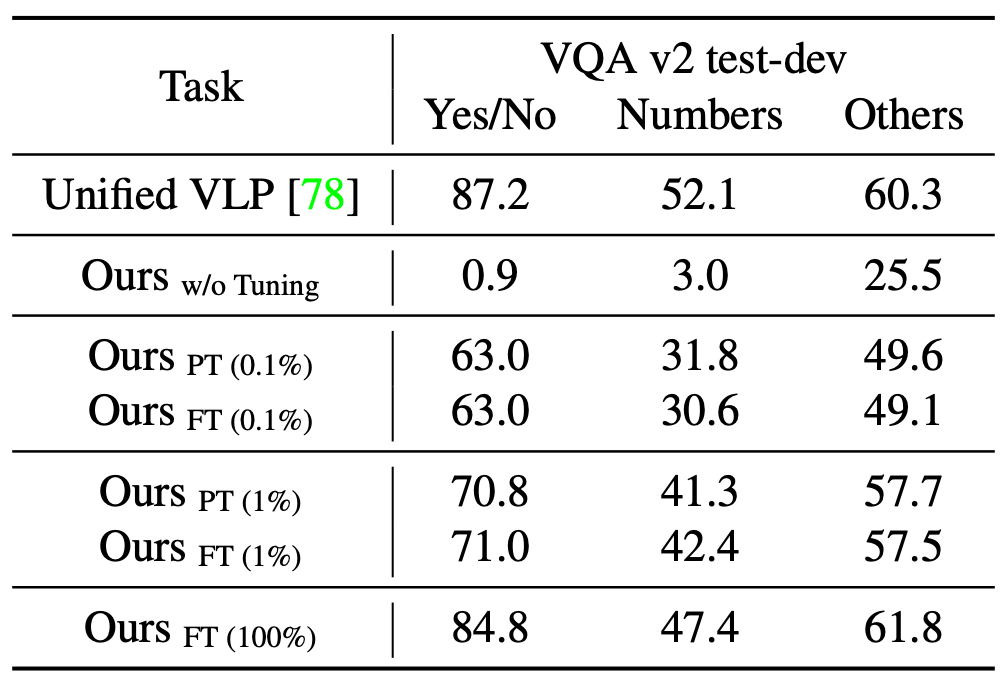
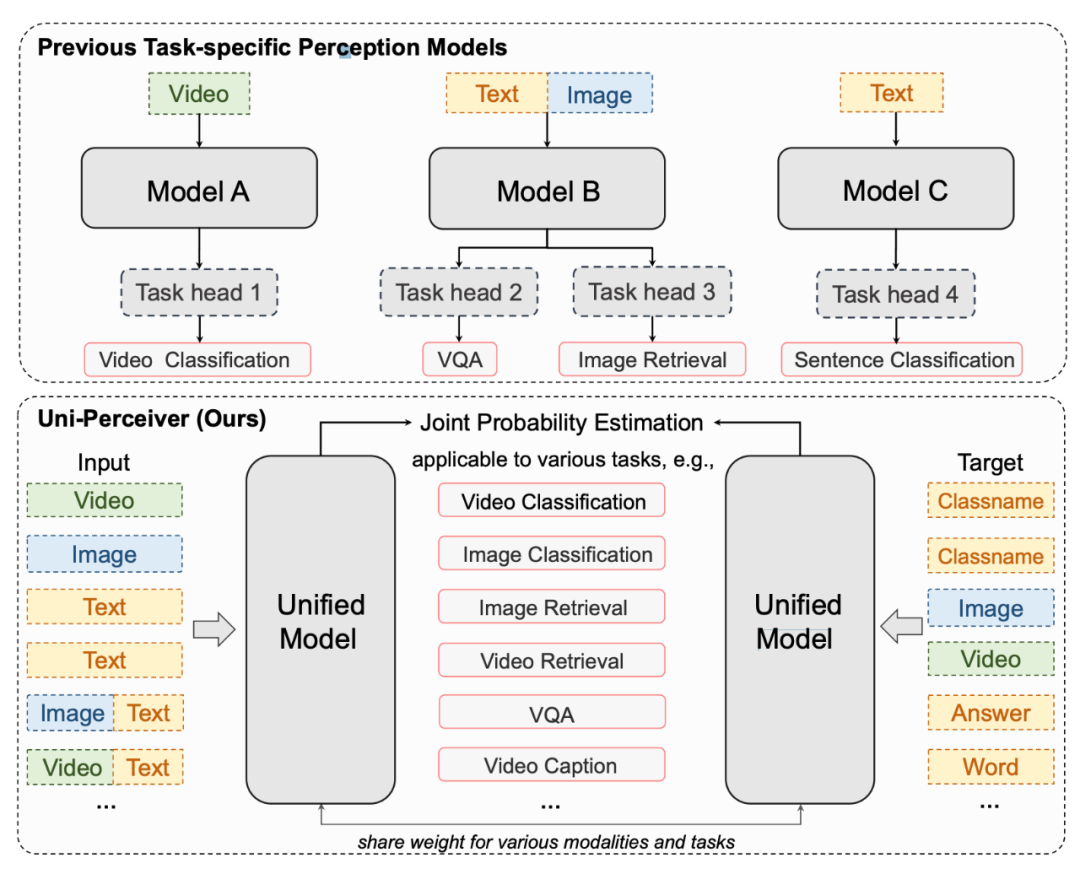
图 1 对比了 Uni-Perceiver 和现有的为特定任务设计和训练的模型。Uni-Perceiver 以统一的模型处理各种模态和任务,在各种单模态任务以及多模态任务上进行了预训练。在下游任务上,由于对不同任务使用了统一的建模,模型显示了没有见过的新任务的 zero-shot 推理能力,不经任何额外训练也能达到合理的性能。此外,通过使用 1% 的下游任务数据进行 prompt tuning,模型性能可以提升到接近 SOTA 的水平。使用 100% 的目标数据对预训练模型进行微调时,Uni-Perceiver 在几乎所有任务上都达到了与 SOTA 方法相当或更好的结果。
![]()
图 1 现有的特定于任务的感知模型和 Uni-Perceiver 的比较
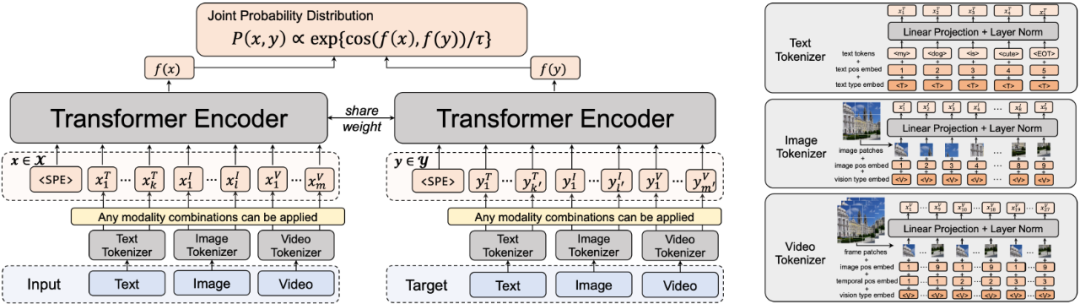
Uni-Perceiver 的统一模型架构如图 2 所示。模型首先将文本、图像、视频不同模态的数据使用对应的 tokenizer 转换为具有同一特征维度的 token 序列,并将不同模态的信息拼接起来,使用一个统一的 Transformer 编码器提取特征。
对于不同的感知任务,Uni-Perceiver 使用相同的模型和共享的一套参数进行建模。相比于传统 backbone + prediction head 的范式,Uni-Perceiver 不包括对每个任务单独设计的 head,而是将不同的任务建模为统一的形式。具体而言,对于每个任务,可以定义其输入集合
![]() 和候选目标集合
和候选目标集合
![]() 。对于给定的输入
。对于给定的输入
![]() ,任务被定义为寻找x在候选目标集合
,任务被定义为寻找x在候选目标集合
![]() 中最相似的目标
中最相似的目标
![]() ,即
,即
![]()
其中,p ( x , y ) 表示输入和候选目标的联合概率分布。Uni-Perceiver 使用特征的余弦相似度建模联合概率分布,即
![]()
其中,
![]() 表示 Transformer 编码器,
表示 Transformer 编码器,
![]() 表示一个可学习的温度系数。
Uni-Perceiver 适用于任意由图像 / 视频 / 文本组成输入和候选目标集合的任务。例如,分类任务中的目标集合
表示一个可学习的温度系数。
Uni-Perceiver 适用于任意由图像 / 视频 / 文本组成输入和候选目标集合的任务。例如,分类任务中的目标集合
![]() 可以是一组类别名(如 dog)、一组类别描述(如 a kind of fish living in deep sea),甚至可以是一组手写的类别编号的图像。
除此之外,作者在文中提到,这篇论文专注于文本、图像和视频模态,但 Uni-Perceiver 也可拓展到更多模态上。
可以是一组类别名(如 dog)、一组类别描述(如 a kind of fish living in deep sea),甚至可以是一组手写的类别编号的图像。
除此之外,作者在文中提到,这篇论文专注于文本、图像和视频模态,但 Uni-Perceiver 也可拓展到更多模态上。
![]()
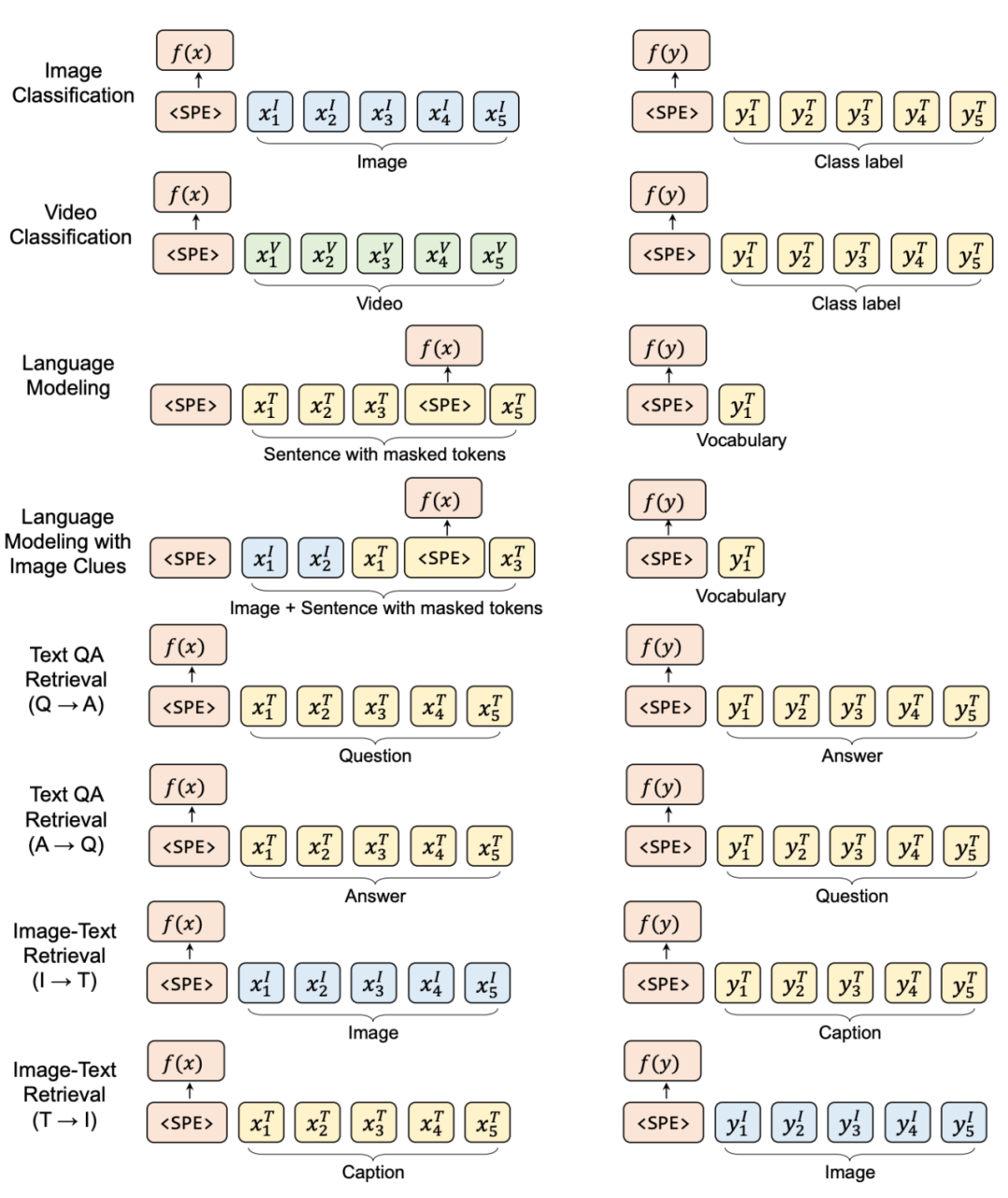
为了学习多模态的通用 representation,Uni-Perceiver 使用一系列单模态或跨模态任务进行了预训练。值得一提的是,在图像和视频分类任务中,作者将类别名称视作文本内容,这为连接起图像、视频和文本多个模态的 representation 提供了一定的监督。
图 3 展示了不同预训练任务的 input 和 target 的序列格式。图中,上标I、V、T
分别代表来自图像、视频和文本模态的 token
。
![]()
3. 应用于下游任务:Zero-shot, Prompt Tuning 和 Fine-tuning
相比于额外增加 prediction head 并 finetune 的方式,Uni-Perceiver 可将预训练模型更高效地迁移到下游任务上。本文中,作者考虑三种不同场景:零样本(Zero-shot),少样本(Few-shot)和全量数据,并对三种情况分别介绍。
在新任务上的 Zero-shot 推理:Uni-Perceiver 可以对预训练阶段没有见过的全新任务进行零样本推理,在不经过任何额外训练和调整的情况下取得合理的效果。
Prompt Tuning:在下游任务数据量有限的场景下,通过 Prompt Tuning,Uni-Perceiver 可以在仅调整小部分模型参数的情况下取得接近全数据 SOTA 的结果。
Fine-tuning:当下游任务数据量足够时,Uni-Perceiver 的预训练模型可以通过 fine-tuning 取得超过 SOTA 或与 SOTA 不相上下的结果。
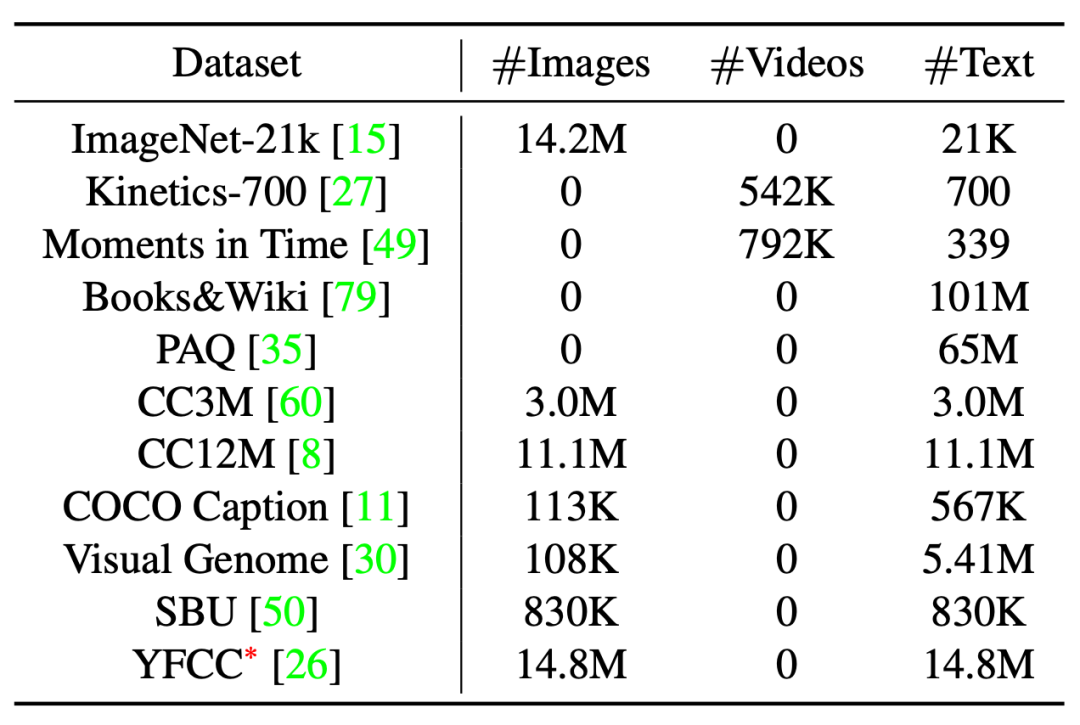
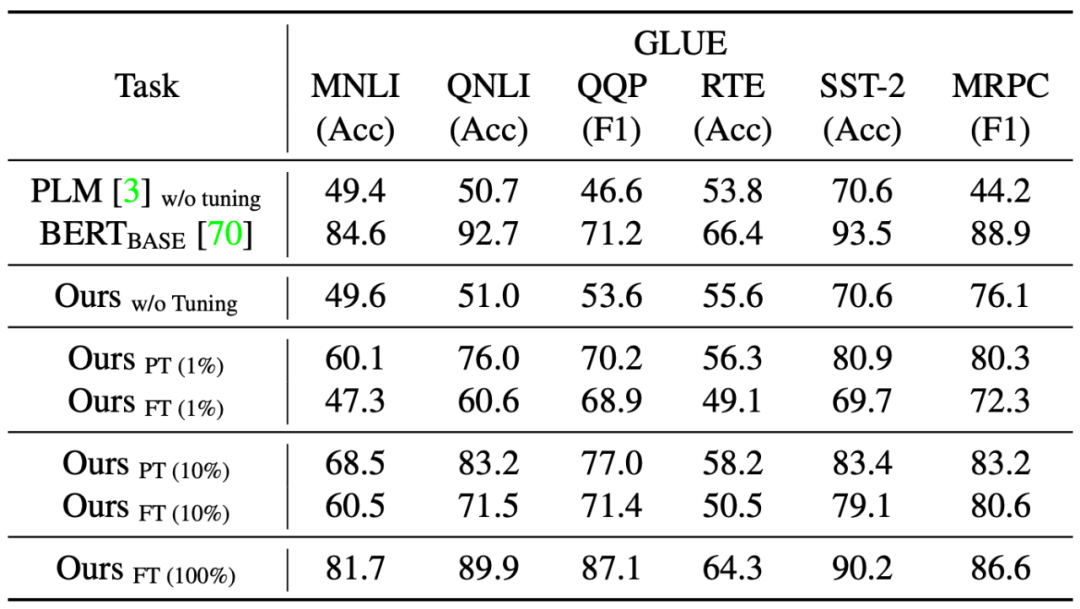
Uni-Perceiver 在表 1 所示的大规模单模态和多模态数据集上进行了训练。实验中,作者使用与 BERT-base 相同配置的 Transformer 编码器。在每次迭代中,每个 GPU 独立采样任务和数据集,并在梯度反向传播之后同步不同 GPU 之间的梯度。该模型在 128 个 Tesla V100 GPU 上以分布式方式进行了 50 万次迭代的预训练。
![]()
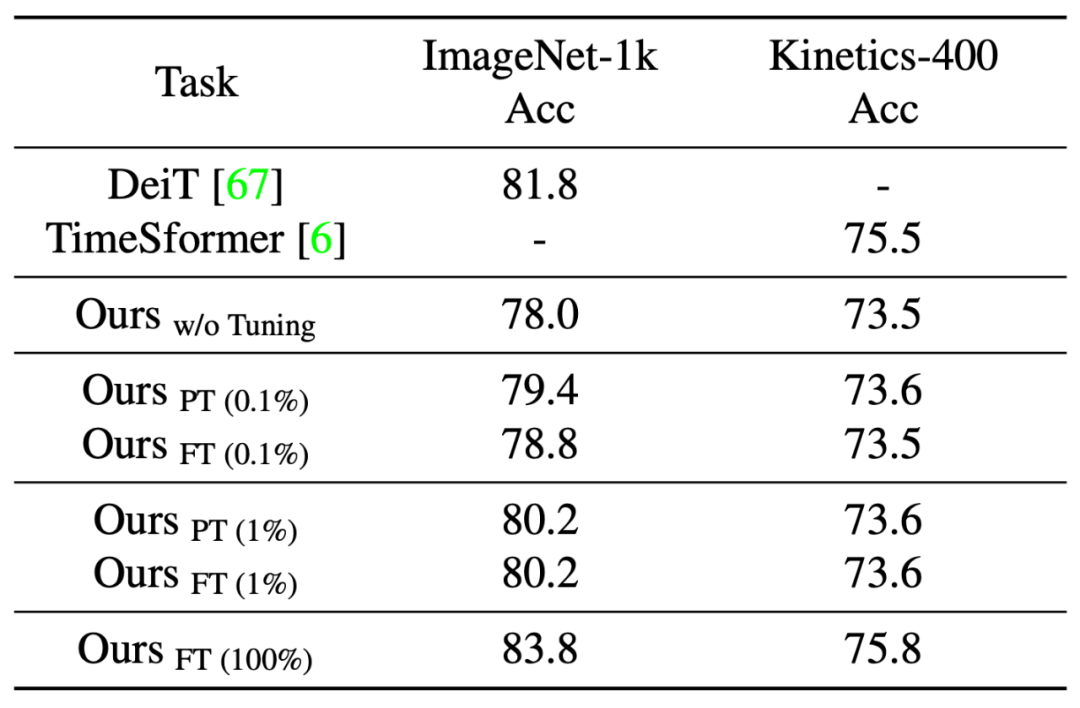
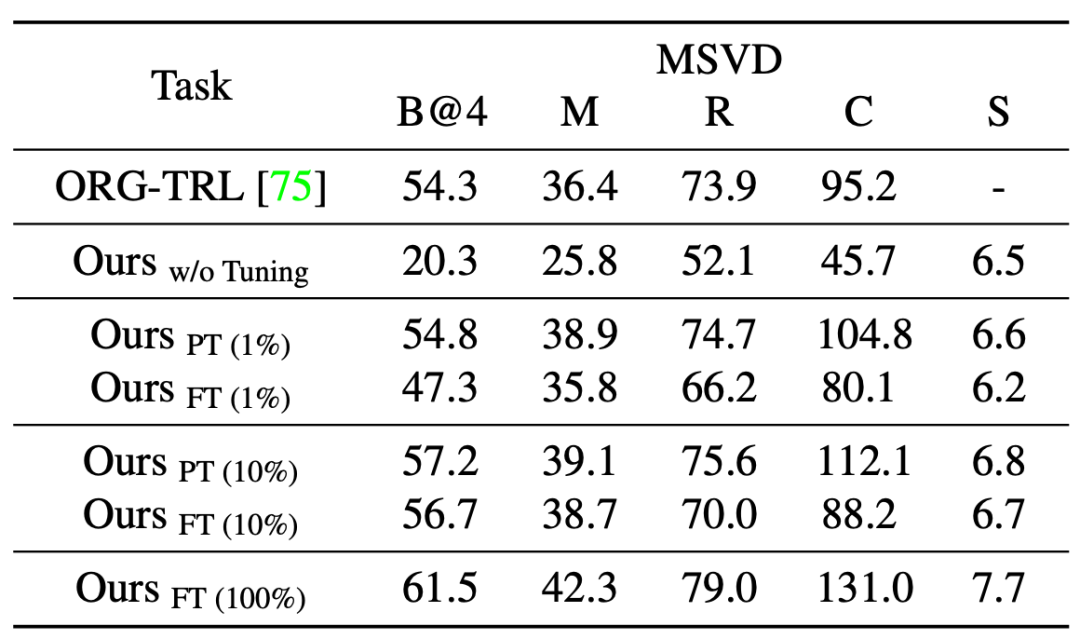
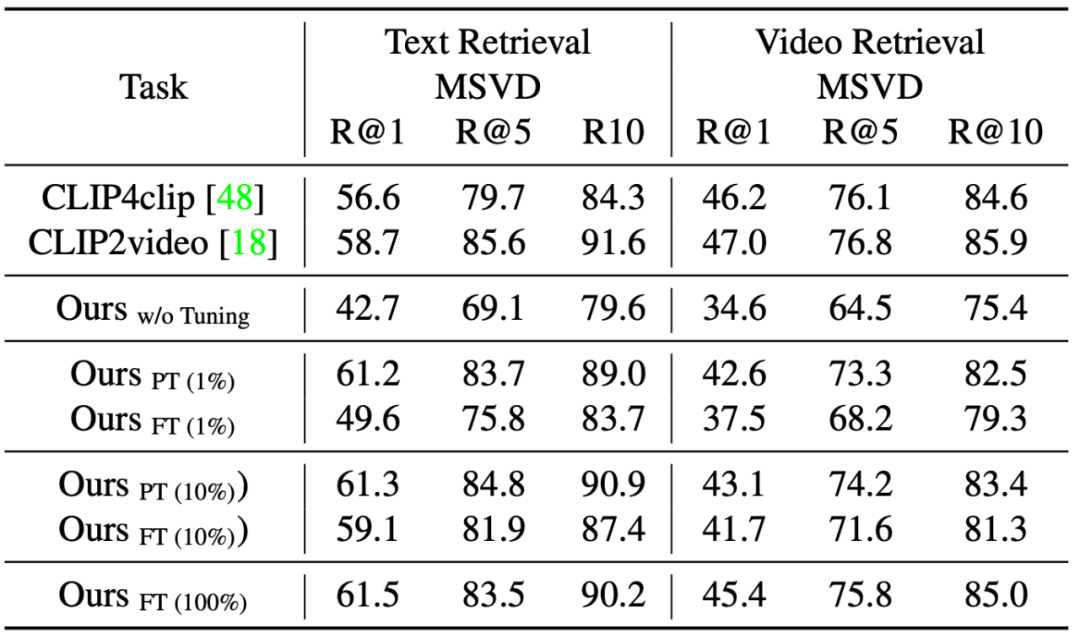
研究者接下来在多项任务上对预训练模型进行了评估,包括预训练中出现过的任务(Image Classification, Image-Text Retrieval, Image Caption)以及与预训练不同的任务(Video Caption, Video-Text Retrieval, VQA)。表 2 – 表 8 展示了这些结果。实验表明,和具有相似模型尺寸的 task-specific SOTA 方法相比:
在不经任何调整的情况下,Uni-Perceiver 即可以达到合理的精度。值得注意的是,对于预训练中不存在的任务,由于 task-specific head 的限制,现有的其他工作无法执行这种类型的 zero-shot 推理。
通过 1% 的数据对少量模型参数进行 Prompt Tuning,Uni-Perceiver 即可以接近 SOTA 的效果。
进一步全数据 Fine-tune 可以使模型在某些任务上超过 SOTA 结果,并在其他任务上取得与 SOTA 相媲美的精度。
![]()
表 2 Image Classification 性能
![]()
表 3 Image-Text Retrieval 性能
![]()
![]()
表 5 新任务 - Video Caption 性能
![]()
表 6 新任务 - Video-Text Retrieval 性能
![]()
![]()
基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。
DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;
完成对车辆车牌的检测和识别,并对行人以及车辆的品牌,颜色,种类进行检测。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

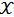 和候选目标集合
和候选目标集合
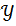 。对于给定的输入
。对于给定的输入
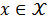 ,任务被定义为寻找x在候选目标集合
,任务被定义为寻找x在候选目标集合
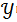 中最相似的目标
中最相似的目标
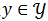 ,即
,即
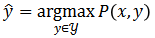
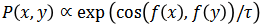
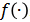 表示 Transformer 编码器,
表示 Transformer 编码器,
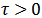 表示一个可学习的温度系数。
表示一个可学习的温度系数。
 可以是一组类别名(如 dog)、一组类别描述(如 a kind of fish living in deep sea),甚至可以是一组手写的类别编号的图像。
除此之外,作者在文中提到,这篇论文专注于文本、图像和视频模态,但 Uni-Perceiver 也可拓展到更多模态上。
可以是一组类别名(如 dog)、一组类别描述(如 a kind of fish living in deep sea),甚至可以是一组手写的类别编号的图像。
除此之外,作者在文中提到,这篇论文专注于文本、图像和视频模态,但 Uni-Perceiver 也可拓展到更多模态上。