Meta AI新作!用Transformer搞定图像、视频和单视图3D数据三大分类任务!Omnivore:性能还不输独立模型
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
丰色 发自 凹非寺
来源:量子位(QbitAI)
最近,Meta AI推出了这样一个“杂食者” (Omnivore)模型,可以对不同视觉模态的数据进行分类,包括图像、视频和3D数据。

论文地址:
https://arxiv.org/abs/2201.08377
代码已开源:
https://github.com/facebookresearch/omnivore
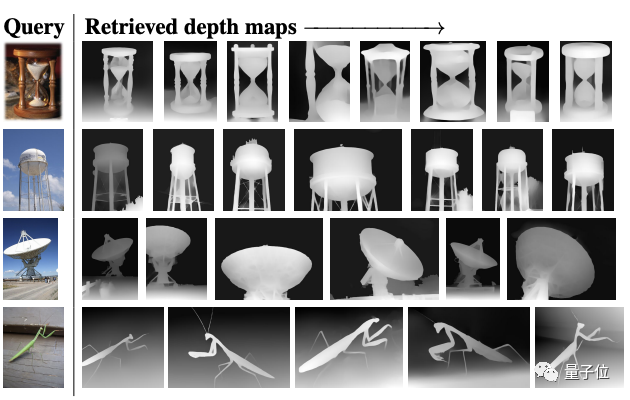
比如面对最左边的图像,它可以从深度图、单视觉3D图和视频数据集中搜集出与之最匹配的结果。
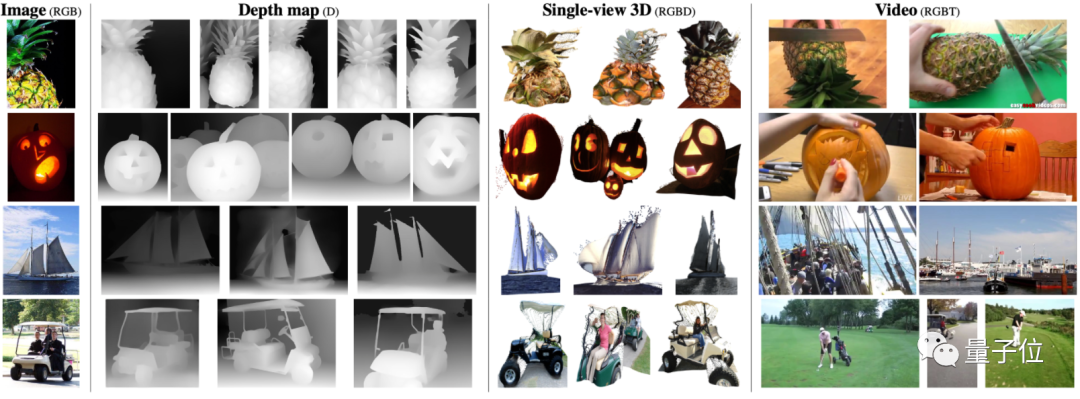
这在之前,都要分用不同的模型来实现;现在一个模型就搞定了。
而且Omnivore易于训练,使用现成的标准数据集,就能让其性能达到与对应单模型相当甚至更高的水平。
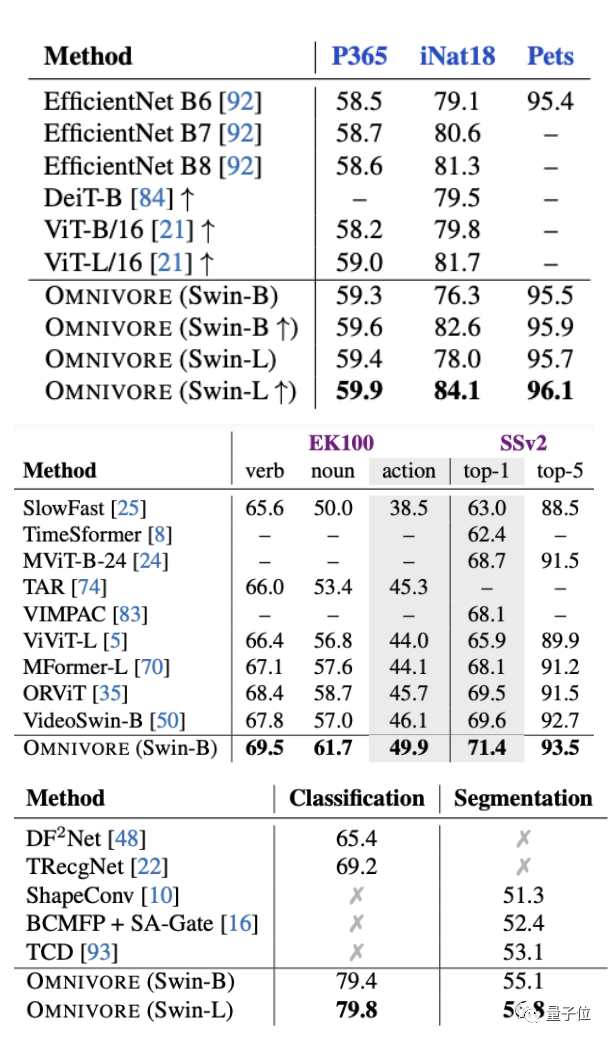
实验结果显示,Omnivore在图像分类数据集ImageNet上能达到86.0%的精度,在用于动作识别的Kinetics数据集上能达84.1%,在用于单视图3D场景分类的SUN RGB-D也获得了67.1%。
另外,Omnivore在实现一切跨模态识别时,都无需访问模态之间的对应关系。
不同视觉模态都能通吃的“杂食者”
Omnivore基于Transformer体系结构,具备该架构特有的灵活性,并针对不同模态的分类任务进行联合训练。
模型架构如下:
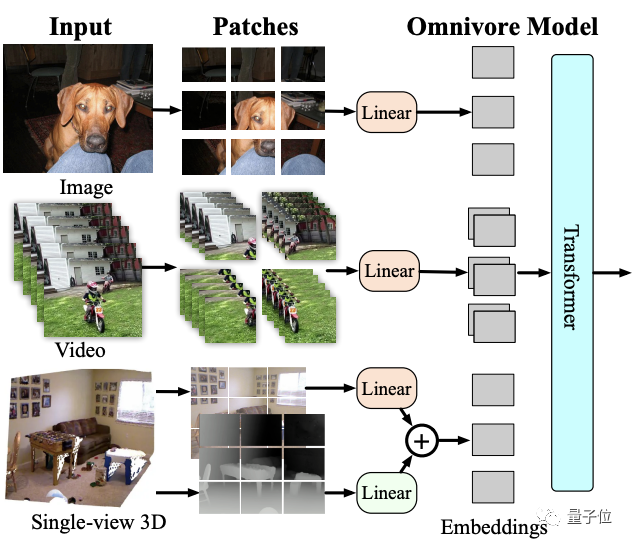
Omnivore会将输入的图像、视频和单视图3D图像转换为embedding,并馈送到Transformer中。
虽然它可以使用任何vision transformer架构来处理patch embedding,但鉴于Swin transformer在图像和视频任务上的强大性能,这里就使用该架构作为基础模型。
具体来说,Omnivore将图像转为patch,视频转为时空tube(spatio-temporal tube),单视图3D图像转为RGB patch和深度patch。
然后使用线性层将patches映射到到embedding中。其中对RGB patch使用同一线性层,对深度patch使用单独的。
总的来说,就是通过embedding将所有视觉模式转换为通用格式,然后使用一系列时空注意力(attention)操作来构建不同视觉模式的统一表示。
研究人员在ImageNet-1K数据集、Kinetics-400数据集和SUN RGB-D数据集上联合训练出各种Omnivore模型。
这种方法类似于多任务学习和跨模态对齐,但有2点重要区别:
1、不假设输入观测值对齐(即不假设图像、视频和3D数据之间的对应关系);
2、也不假设这些数据集共享相同的标签空间(label space)。
性能超SOTA
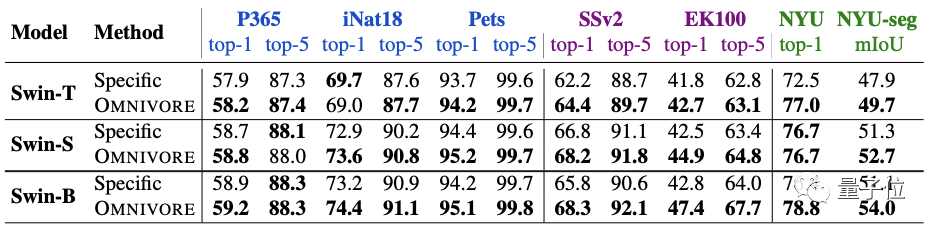
实验方面,首先将Omnivore与各视觉模态对应的特定模型(下表中指Specific)进行比较。
一共有三种不同的模型尺寸:T、S和B。
预训练模型在七个下游任务上都进行了微调。
图像特定模型在IN1K上预训练。视频特定模型和单视图3D特定模型均使用预训练图像特定模型的inflation进行初始化,并分别在K400和SUN RGB-D上进行微调。
结果发现,Omnivore在几乎所有的下游任务上的性能都相当于或优于各特定模型。
其中尺寸最大的Swin-B实现了全部任务上的SOTA。
将Omnivore与具有相同模型架构和参数数量的特定模型比较也是相同的结果。
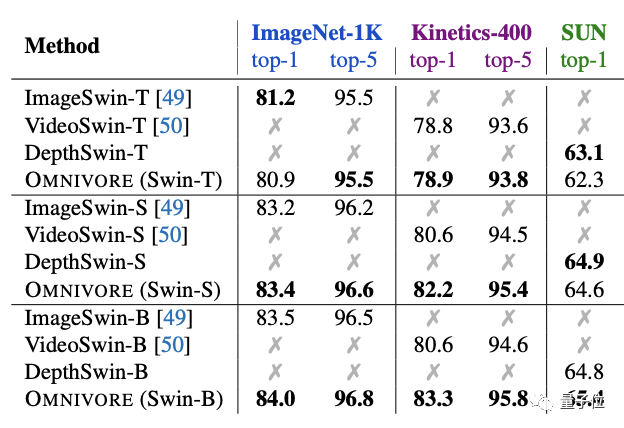
其中Omnivore在IN1K、K400和SUN数据集上从头开始联合训练,而特定模态的模型针对每个数据集专门训练:
ImageSwin模型从零开始训练,VideoSwin和DepthSwin模型则从ImageSwin模型上进行微调。
接下来将Omnivore与图像、视频和3D数据分类任务上的SOTA模型进行比较。
结果仍然不错,Omnivore在所有预训练任务中都表现出了优于SOTA模型的性能(下图从上至下分别为图像、视频和3D数据)。
此外,在ImageNet-1K数据集上检索给定RGB图像的深度图也发现,尽管Omnivore没有接受过关于1K深度图的训练,但它也能够给出语义相似的正确答案。
最后,作者表示,尽管这个“杂食者”比传统的特定模式模型有了很多进步,但它有一些局限性。
比如目前它仅适用于单视图3D图像,不适用于其他3D表示,如体素图(voxels)、点云图等。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号




