苹果发布新模型GAUDI:只用文字就能生成无限制3D模型!
![]()
新智元报道

新智元报道
【新智元导读】最近苹果发布了一个新模型GAUDI,能直接从文字生成3D模型,NeRF的相机位置还不受限制!
2020年开始大火的神经辐射场(NeRF)技术,仅需几张2D图片,就能合成出高质量的3D模型场景。

有人畅想,NeRF可能是实现元宇宙的一项重要技术基础,各个大厂纷纷上马项目进行研究,比如英伟达的AI研究人员展示过从照片中创建3D物体,谷歌也依靠NeRF来实现沉浸式视图或渲染3D人物。

NeRF可以从2D图像中生成3D场景,OpenAI的DALL-E 2可以从文字里生成出2D图像,那二者一结合,岂不是可以直接从文本生成3D模型?

谷歌在2021年末提出过Dream Fields,尝试结合NeRF生成3D视图与OpenAI的CLIP模型的能力,直接从文本中生成物体的3D模型。
不过谷歌的Dream Fields主要用于生成单个对象,将生成式AI扩展到完全不受约束的3D场景仍然是一个尚未解决的问题。
造成这种情况的其中一个原因可能是摄像机位置的限制:虽然对于单个对象,每个可能的合理摄像机位置都可以映射到一个dome,但在3D场景中,这些摄像机位置受到对象和墙壁等障碍物的限制。如果在场景生成期间不考虑这些,则生成的3D场景的可用性就会大大降低。
最近苹果披露了他们最新的用于生成沉浸式3D场景的神经网络架构GAUDI,可以根据文字提示创建3D场景。

论文链接:https://arxiv.org/pdf/2207.13751.pdf
GAUDI是一个能够捕捉复杂而真实的三维场景分布的生成模型,可以从移动的摄像机中进行沉浸式渲染,采用了一种可扩展但强大的方法来解决这个具有挑战性的问题。
研究人员首先优化一个隐表征,将辐射场和摄像机的位置分开,然后将其用于学习生成模型,从而能够以无条件和有条件的方式生成三维场景。
GAUDI在多个数据集的无条件生成设置中取得了sota的性能,并允许在给定条件变量(如稀疏的图像观测或描述场景的文本)的情况下有条件地生成三维场景。
模型的名字来自西班牙著名建筑大师Antoni Gaudi,以其复杂、新颖、独树一帜、个人色彩强烈的建筑作品知名,他被誉为「上帝的建筑师」。他有一句名言:创造会通过人类的媒介不断地传承下去!

从文本到3D
从文本到3D
为了解决摄像机位置受限的问题,GAUDI模型把摄像机的姿势当做是穿过场景的轨迹,从而明确了模型的设计方向。
GAUDI将每个轨迹(即来自三维场景的姿势图像序列)映射到一个隐表示中,以完全分离的方式编码辐射场(例如三维场景)和相机路径。
GAUDI模型引入了三个解码器网络。
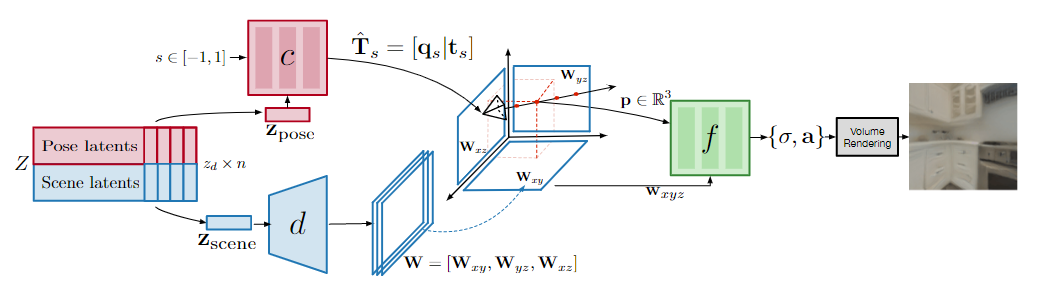
1、相机姿态解码器(camera pose decoder)网络主要负责在轨迹中的某个归一化时序位置预测可能的相机位置。为了确保输出是3D场景架构的有效位置,输出为一个3D向量,代表方向的归一化quaternion朝向和三维平移矢量。
2、场景解码器(scene decoder)网络通过一种3D画布的形式预测辐射场网络的条件变量。该网络将一个代表场景的潜编码作为输入,输出为一个轴对齐的三平面(tri-plane)表示。
3、辐射场解码器(radiance field decoder)网络的任务是使用体积渲染方程重建图像,对每个像素的值进行预测,其中三维点表示为特定深度的射线方向(与像素位置对应)。
然后设计一个去噪重建目标对三个网络进行联合优化。
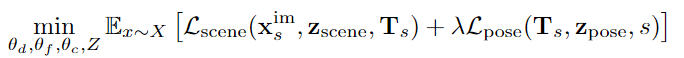
训练过程中,每个轨迹潜表征都会通过重建目标进行优化,从而可以将其扩展到成千上万的轨迹。将每个轨迹的潜表征解释为自由参数后,也使得处理每个轨迹的大量可变视图变得更简单,而不需要一个复杂的编码器架构来汇集大量的视图。
在为观察到的轨迹的经验分布优化了潜表征后,可以在潜表征的集合上学习生成模型。

在无条件的情况下,模型可以完全从模型学到的先验分布中采样辐射场,允许它通过在潜像空间内插值来合成场景。
在有条件的情况下,模型在训练时可用的条件变量(如图像、文本提示等)可以用来生成与这些变量一致的辐射场。
在实验阶段,研究人员使用四个数据集对GAUDI的能力进行测试:
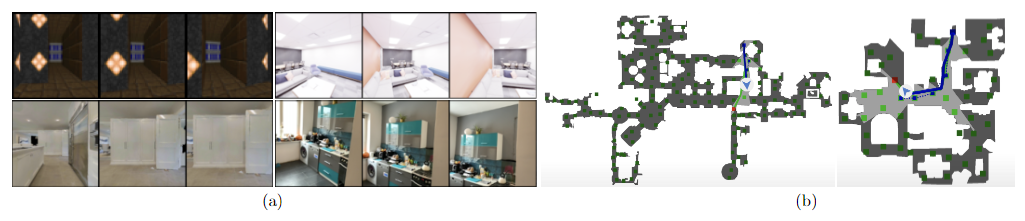
1、 Vizdoom是一个具有简单纹理和几何形状的合成模拟环境,就场景和轨迹的数量以及纹理而言,它是最简单的数据集。
2、Replica是一个由18个真实场景组成的数据集,其中的轨迹是通过Habitat渲染的。
3、VLN-CE是一个最初为连续环境中的视觉和语言导航设计的数据集,由3D数据集中一个agent在3D场景中两点之间导航的3600条轨迹组成,通过Habitat渲染观察结果。这个数据集还包含了agent所采取的轨迹的文本描述。
4、ARKitScenes是一个室内空间扫描的数据集。这个数据集包含了大约1600个不同的室内空间的5000多份扫描数据。与之前的数据集相比,ARKitScenes提供了原始的RGB和深度扫描以及使用ARKit SLAM估计的相机姿势,而其他数据集是通过在模拟中的渲染获得的。此外,其他的数据集的轨迹是点对点的,就像导航一样,而ARKitScenes的相机轨迹类似于对整个室内空间的自然扫描。
在重建性能的量化评估上可以发现,GAUDI模型中描述的优化问题能够找到能够以令人满意的方式重建经验分布中的轨迹的潜编码。

在不同数据集的随机轨迹结果中,可以看到GAUDI可以重建学习视图并能够匹敌现有方法的质量。

在以文本作为条件的情况下,研究人员使用VLN-CE中提供的导航文本描述来训练GAUDI模型。这些文本描述包含了关于场景以及导航路径的抽象信息,例如「走出卧室」,「进入客厅」,「通过摆动的门离开房间,然后进入卧室」等。采用预训练的RoBERTa-base作为文本编码器,并使用其中间表示来调节扩散模型。

这也是首个摊销(amortized)的方式从文本生成有条件的三维场景的模型,也就是说不需要费时费力来优化、蒸馏CLIP模型。
甚至还可以把「图像」当做条件进行生成。
在每次训练迭代中,研究人员随机抽取轨迹中的图像并将其作为条件变量。采用预训练的ResNet-18作为图像编码器。在推理过程中,产生的条件GAUDI模型能够对给定图像从随机视角观察的辐射场进行采样。

不过GAUDI当前生成的视频质量仍然很低,并且充满了伪影。但凭借其AI系统,苹果正在为可以渲染3D对象和场景的生成式AI系统奠定另一个基础,一个未来可能的应用方向是为苹果的XR头显生成数字位置。


