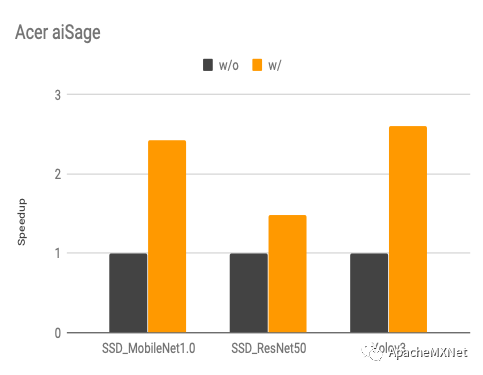卷积神经网络在移动端集成显卡上的加速
本文谈的是在移动端加速卷积神经网络。虽然AWS是个云服务公司,我们同样重视edge上的计算。现代终端设备一般都跟云端服务器相连,但只要可能,我们都希望计算可以在本地终端解决,这样做的好处是多方面的:既可以减小网络带宽的压力,又可以避免网络传输产生的时延,还可以让用户的数据更安全。现代终端设备一般用一个片上系统 (SoC)做计算,上面部署了通用的CPU和集成显卡。对于日益增多的卷积神经网络推理计算来说,在移动端的CPU(多数ARM,少数x86)上虽然优化实现相对简单(参见我们对CPU的优化),但此处它并非最佳选择,因为:1)移动端CPU算力一般弱于集成显卡(相差在2-6倍之间);2)更重要的是,已经有很多程序运行在CPU上,如果将模型推理也放在上面会导致CPU耗能过大或者CPU节流,造成耗电过快同时性能不稳定。所以在移动端进行模型计算,集成显卡是更好的选择。
说起来很有道理,但用起来就不一样了。实际中我们发现移动设备上的集成显卡利用率很低,大家并不怎么用它来跑卷积神经网络推理。原因其实很简单:难用。在AWS,我们面对很多移动端机器,里面用到集成显卡多数来自Intel, ARM和Nvidia,编程模型一般是OpenCL和CUDA。虽然对于某些特定模型和算子,硬件厂商提供了高性能库(Intel的OpenVINO, ARM的ACL, Nvidia的CuDNN),但它们覆盖度有限,用起来不灵活,造成即使对单一硬件做多模型的优化,工程代价也很大,遑论我们面对的硬件类种类繁多。总之,要用传统方法在集成显卡上实现一个通用高效的模型推理并不容易。
好在现在我们有了深度学习编译器。Apache TVM从一开始的设计目标就是做好模型和硬件的中间件,把不同模型编译到不同硬件上执行,中间尽量统一管理,这跟我们对集成显卡的需求是完全一致的。于是,我们的解法是扩展Apache TVM对集成显卡的支持,用同一套IR来统一描述神经网络并根据硬件类型lower到不同的硬件平台上去。这样我们可以尽量复用优化,并且利用TVM已有的优化方案(比如此文提到的算子优化、图优化和协同优化)来实现在集成显卡上的高效模型推理。最后,我们还在TVM上对几个在集成显卡上经常被用到的计算机视觉特定算子进行了精调。我们在三款主流厂商的集成显卡上进行了验证,包括AWS DeepLens (Intel Graphics), Acer aiSage/Rockchip RK-3399 (ARM Mali)和Nvidia Jetson Nano (Nvidia GPU with Maxell architecture)。这个项目的结果发表在了并行计算会议ICPP 2019:A Unified Optimization Approach for CNN Model Inference on Integrated GPUs。相关代码都已经merge到Apache TVM里了。时至今日这个项目也还没有做完,我们依然在根据实际需要不断扩展对不同模型和硬件的支持。
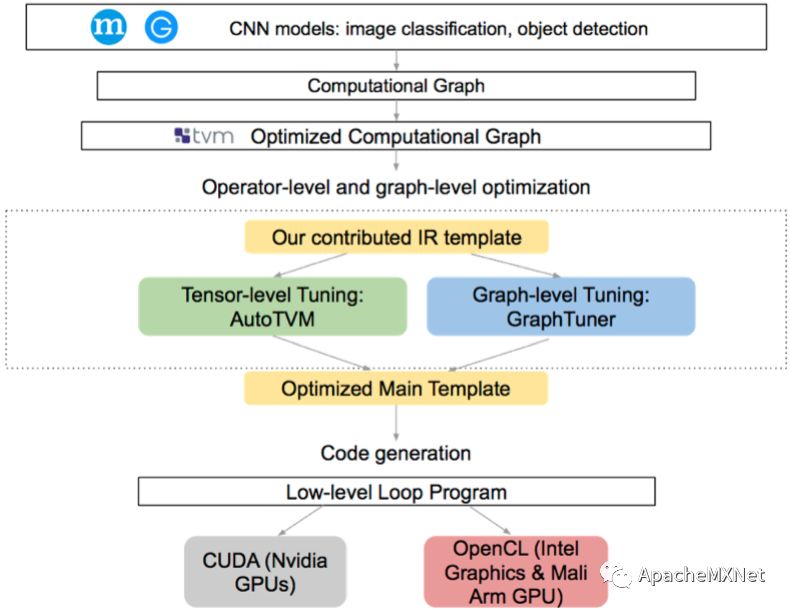
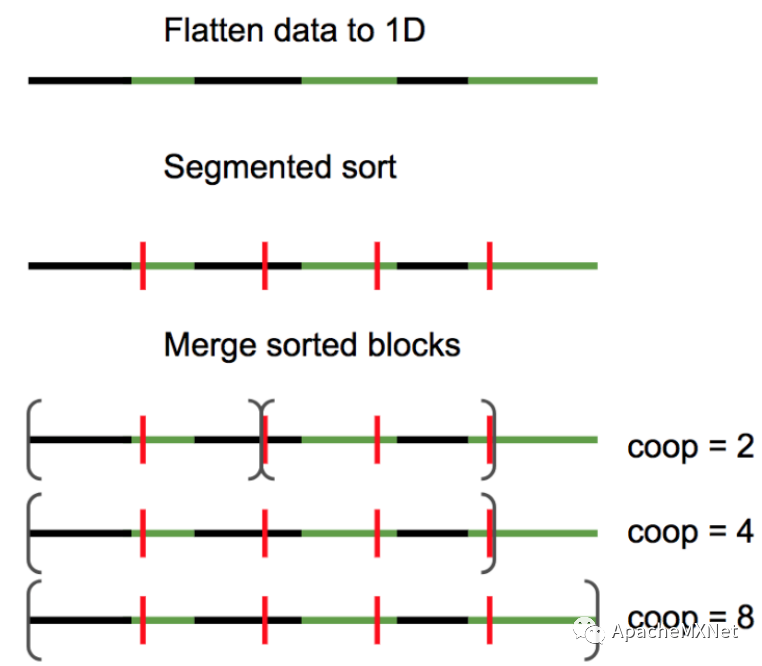
具体地说,为了让TVM高效快速支持集成显卡上卷机神经网络的推断计算,我们在TVM已有框架下加入了下图彩色部分所示的部分,包括IR,对算子和计算图的优化,以及对CUDA/OpenCL后端的优化。
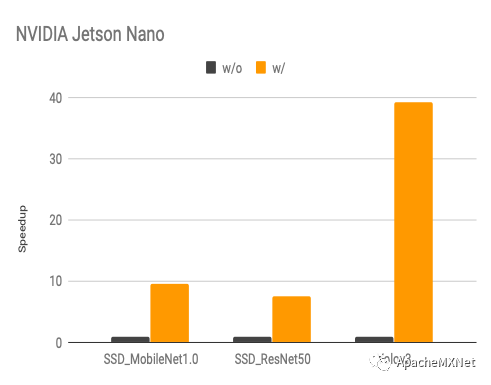
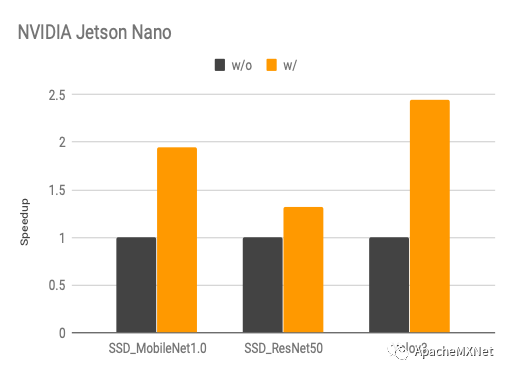
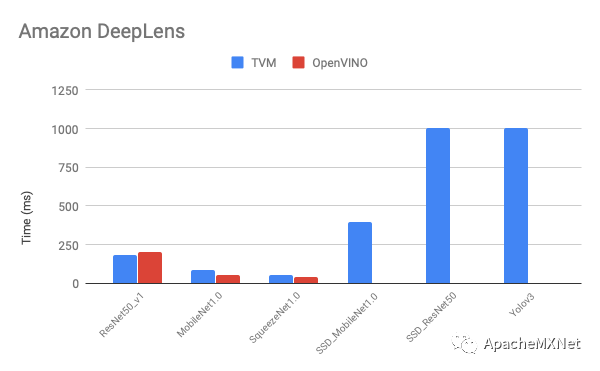
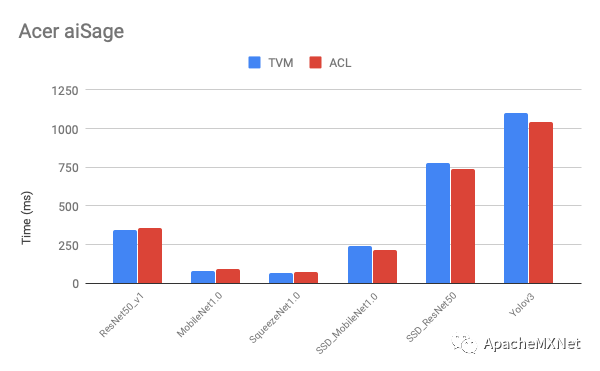
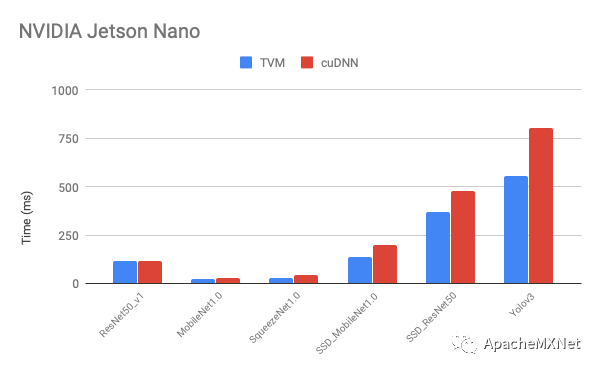
以下是我们在不同移动端显卡上优化后的性能和原厂提供软件的比较(latency, 数字越低越好)。从图中看出我们的性能在大部分模型上比原厂快,而且模型覆盖率更高,比如在我们做实验的时候Intel OpenVINO还不支持在DeepLens上跑目标检测网络。
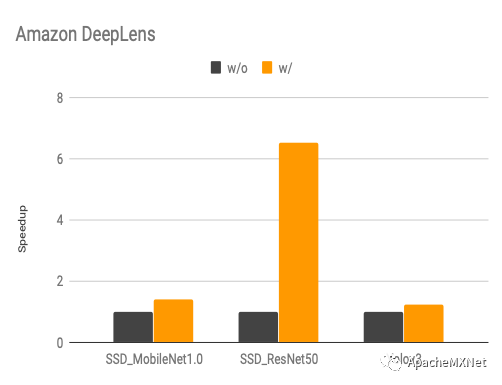
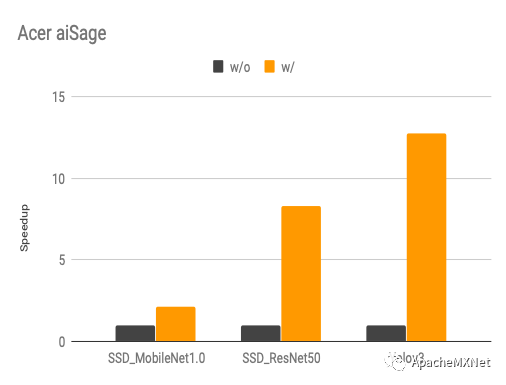
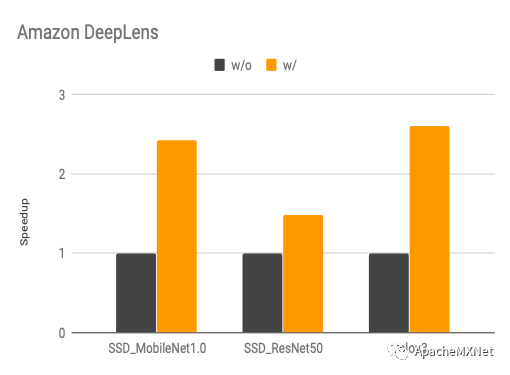
下图是我们使用算子搜索和计算图搜索前后的性能变化(speedup, 数字越高越好),具体优化算法概念上跟我们在CPU上的优化是一样的,不过算子搜索模板因为硬件架构的不同而有所改变。