AAAI 2019 | 自动机器学习计算量大!这种多保真度优化技术是走向应用的关键
作者:Yi-Qi Hu, Yang Yu, Wei-Wei Tu, Qiang Yang, Yuqiang Chen , Wenyuan Dai
来源:AAAI 2019,机器之心

自动机器学习能够大幅度降低机器学习门槛,使非机器学习甚至非计算机领域能够快速使用机器学习算法,因而越来越受到关注。目前求解自动机器学习问题的常规方法是将机器学习过程形式化为一个黑盒优化任务,优化的目标是学习过程在学习任务上的某一评价指标。
由于自动机器学习的优化目标具有不连续、不可导等数学性质,所以一些搜索和非梯度优化算法被用来求解该问题。此类算法通过采样和对采样的评价进行搜索,往往需要大量对采样的评价才能获得比较好的结果。然而,在自动机器学习任务中评价往往通过 k 折交叉验证获得,在大数据集的机器学习任务上,获得一个评价的时间代价巨大。这也影响了优化算法在自动机器学习问题上的效果。所以一些减少评价代价的方法被提出来,其中多保真度优化就是其中的一种。
多保真优化的设定是有多种不同保真度的评价方式。低保真度评价上,获得评价结果代价小,但是评价结果不准确;在高保真度评价上,评价结果准确,但是获得评价的代价很大。自动机器学习天然吻合这样的优化设定,通过随机选取部分数据集作为评价中训练数据集的方式可以构建不同保真度的评价。但是 PAC 理论可知,在部分数据集上的评价结果存在一定的偏差,本工作提出了一种利用修正后低保证度评价来代替高保真度评价,用于优化中,大大减少了评价的代价,提高了优化效果。
本工作利用有限的高保真度评价样本学习一个预测器,用于预测高低保真度评价之间的残差,在优化中使用低保真度评价和残差预测值之和代替高保真度评价。关键难点在于高保真度评价有限,用于训练预测器的样本极少,本工作提出了一种系列化迁移扩展的方式,预训练数个基预测器,然后线性组合基预测器的方式得到最终的残差预测器。通过这种方式解决了训练样本较少的问题。
多保真度技术是大规模自动机器学习优化问题走向实用的关键技术,大幅度降低评价代价为优化算法提供了更多探索的机会,使得优化算法能够发挥最大效能求解自动机器学习问题。
论文:Multi-Fidelity Automatic Hyper-Parameter Tuning via Transfer Series Expansion

论文地址:http://lamda.nju.edu.cn/huyq/papers/mfopt-19.pdf
论文提出的方法
我们提出一种通用的多保真度优化框架,此框架通过简单的变换即可应用于任意非梯度优化(derivative-free optimization)方法中。该框架的主要思路是:基于一些高保真度的观察结果,学习残差预测器以纠正优化过程中低保真度评价的偏差。由于高保真度评价有限,因此训练准确的预测器非常困难。为了解决该问题,我们提出了系列化迁移扩展(Transfer Series Expansion,TSE)方法,TSE 通过迁移多个基预测器的方式来训练最终的残差预测器。Ψ 指最终的预测器,ψ = {ψ_1, ψ_2, . . . , ψ_k} 指一系列基预测器。通过线性组合的方式将 ψ 扩展为 Ψ。
多保真度优化框架
我们设计了一个适用于任意非梯度优化方法的通用多保真度框架,主要研究最小化问题。非梯度优化的关键步骤是如何生成新样本 x。现在令 SampleO 表示非梯度优化方法中生成采样的步骤,其中 O 为非梯度优化方法。大多数非梯度优化方法都属于基于模型(model-based)的方法,采样步骤包括在(X, f)的建模过程和基于模型的采样过程,不同的模型有不同的采样步骤。
在多保真度优化中,它会引入低保真度评价 f_L 以减少总的评价成本。该框架还会学习一个预测器 Ψ 以估计高保真度和低保真度评价之间的残差。随后在修正后的评价(f_L+Ψ)上执行优化,这样我们在修正后评价的优化结果,在真实的高保真度评价上仍有很好的表现。

系列化迁移扩展 (TSE)
在 Algorithm 2 中,用于训练 Ψ 的数据集实例数量很少,因为 f_H 的评价成本高。TSE 可以在训练数据集规模很小的情况下使 Ψ 收敛。

实验
我们基于分类优化方法,利用 TSE 实现了多保真度框架,并将其命名为 TSESRACOS。在实验部分,我们使用 TSESRACOS 在一些真实数据集上对 LightGBM 调参。
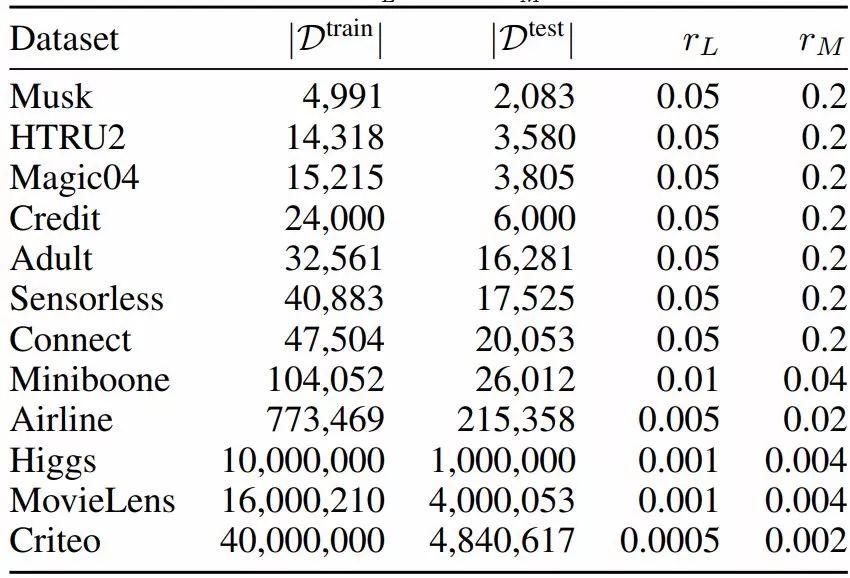
表 1:数据集信息。|D| 表示数据集 D 中的样本数。验证数据集是通过对 D^train 中的样本以 10% 的采样律进行随机采样获得。r_L 和 r_M 是 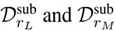
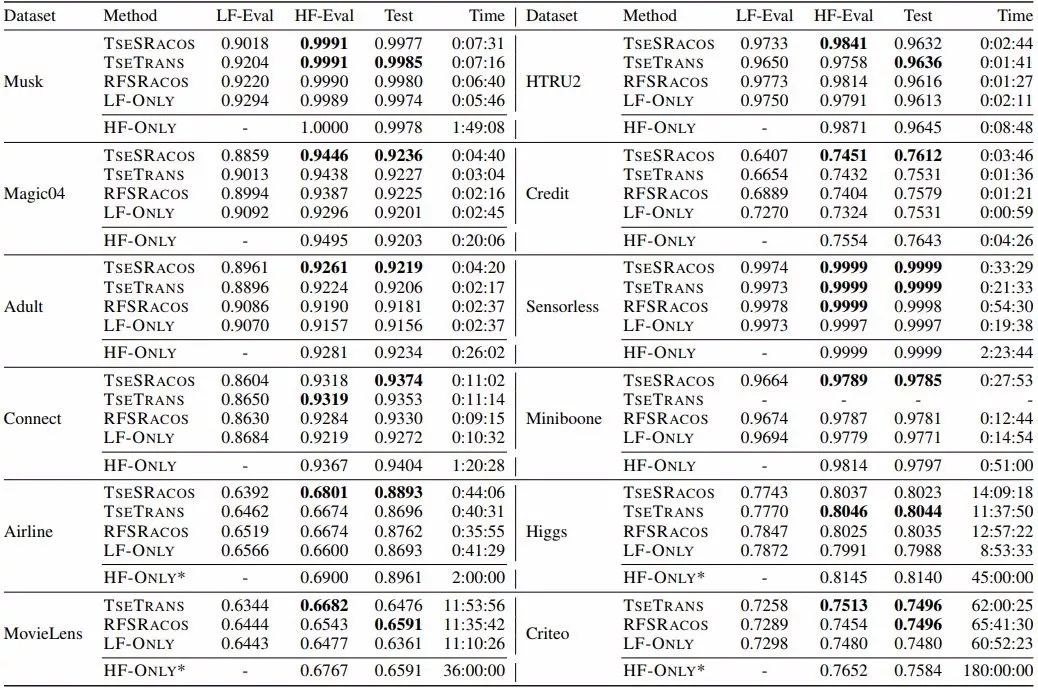
表 2:多个对比方法的 AUC 性能和整体时间(wall-clock time)对比。LF-Eval 和 HF-Eval 表示最优解的低保真度和高保真度评价值、Test 表示最优解的泛化性能、加粗数字表示最好的 AUC 分数。TSETRANS 方法将 Miniboone 数据集上的基预测器迁移到其他数据集。因此 TSETRANS 在 Miniboone 上的结果为空。HF-ONLY^∗ 表示 HF-ONLY 在大型数据集上的超参优化在消耗一定的时间后提前停止。
图 1:总体时间 AUC 曲线图。实线表示高保真度值曲线,虚线表示低保真度值曲线,带圆点的线表示优化的目标函数曲线。同样颜色的实线和虚线是在同样样本上的高保真度和低保真度评价值。X 轴展示的时间为 LF-ONLY 所消耗的时间。
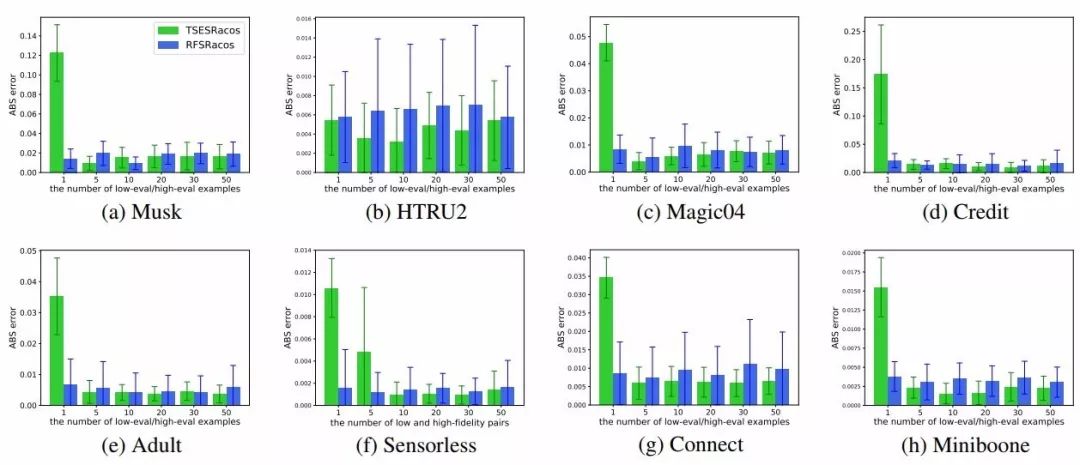
图 2:在每一个预测器训练中,平均回归预测器误差 |f_L+Ψ−f_H| 的直方图。仅对比 TSESRACOS(绿色)和 RFSRACOS(蓝色)的预测误差。X 轴表示残差预测器训练数据集中的样本个数。
广告 & 商务合作请加微信:kellyhyw
投稿请发送至:mary.hu@aisdk.com




