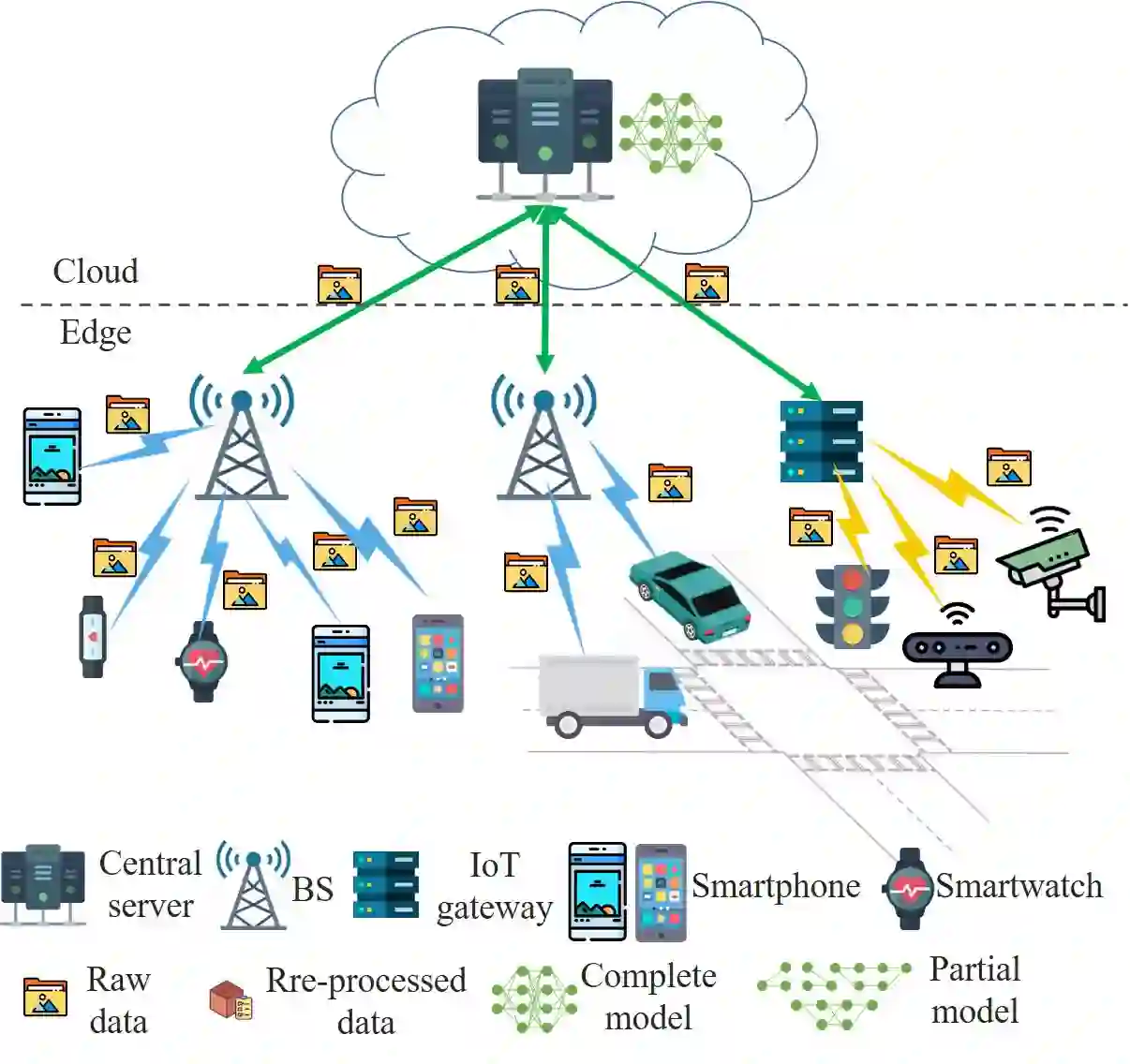
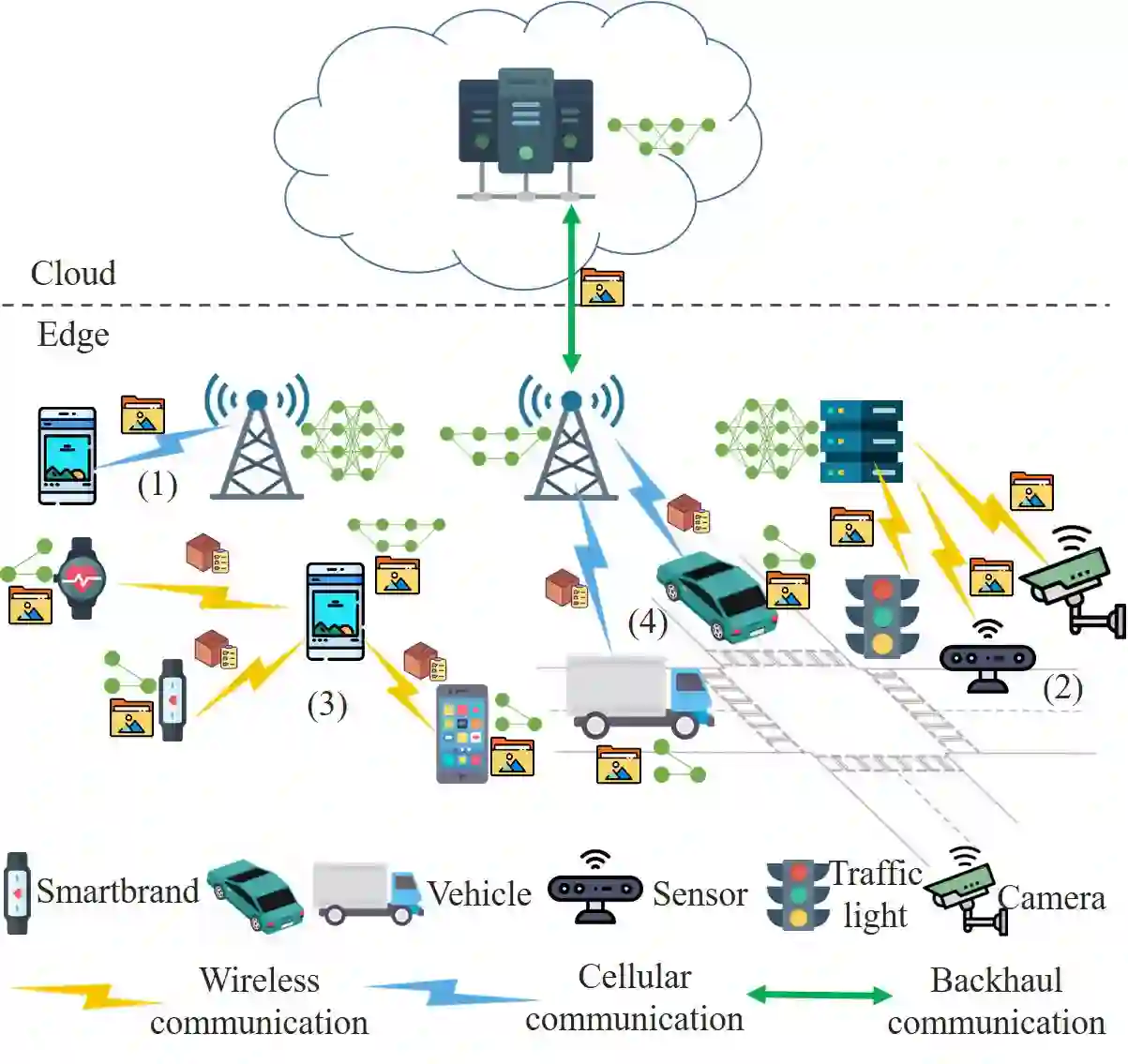
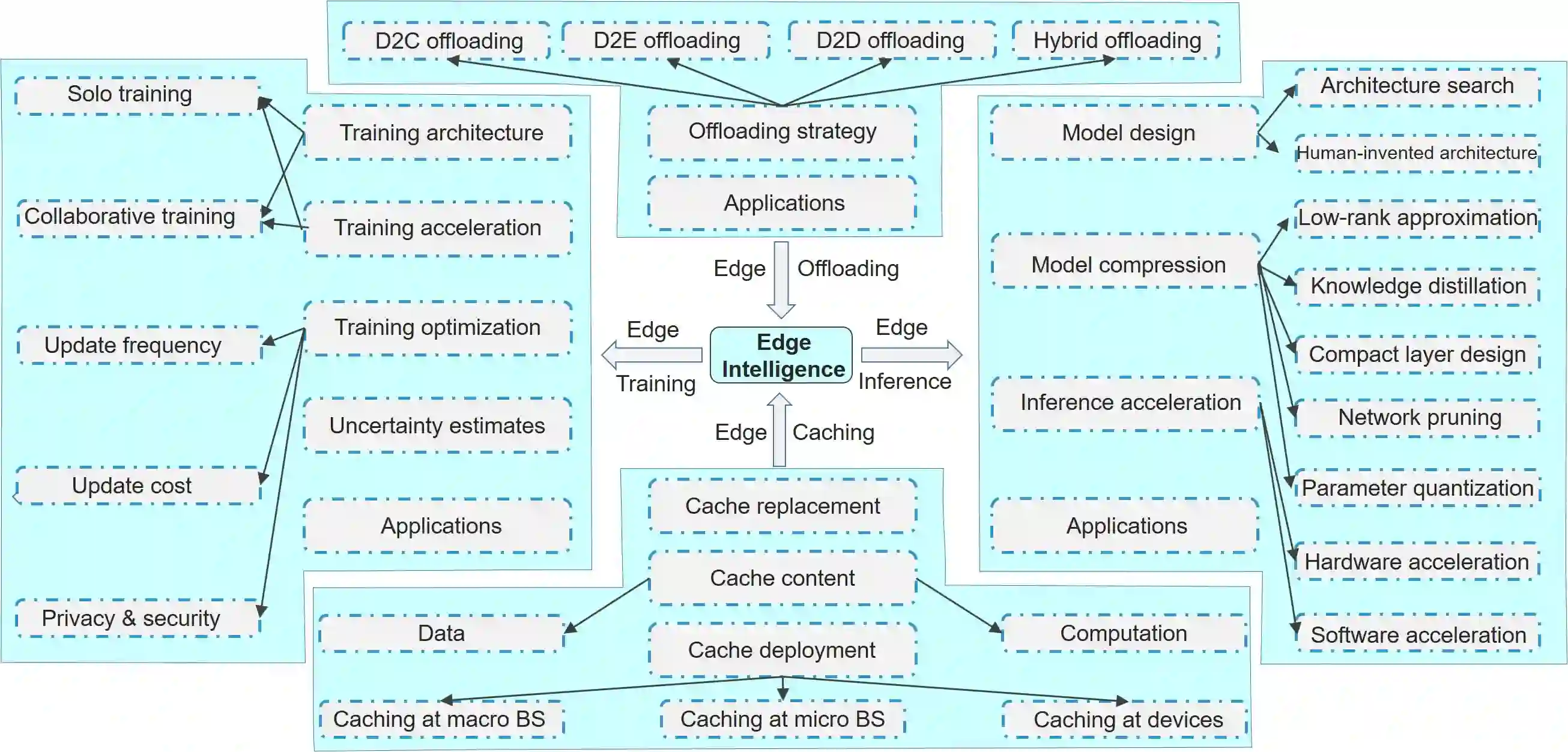
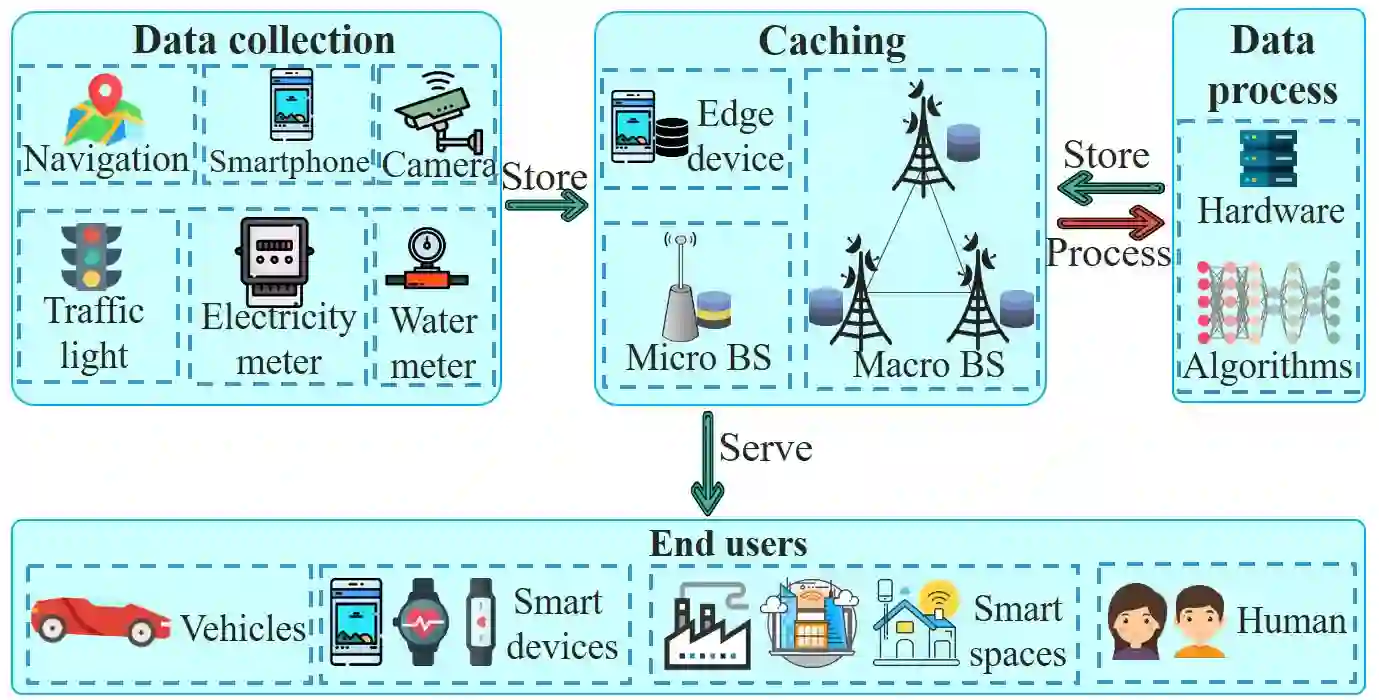
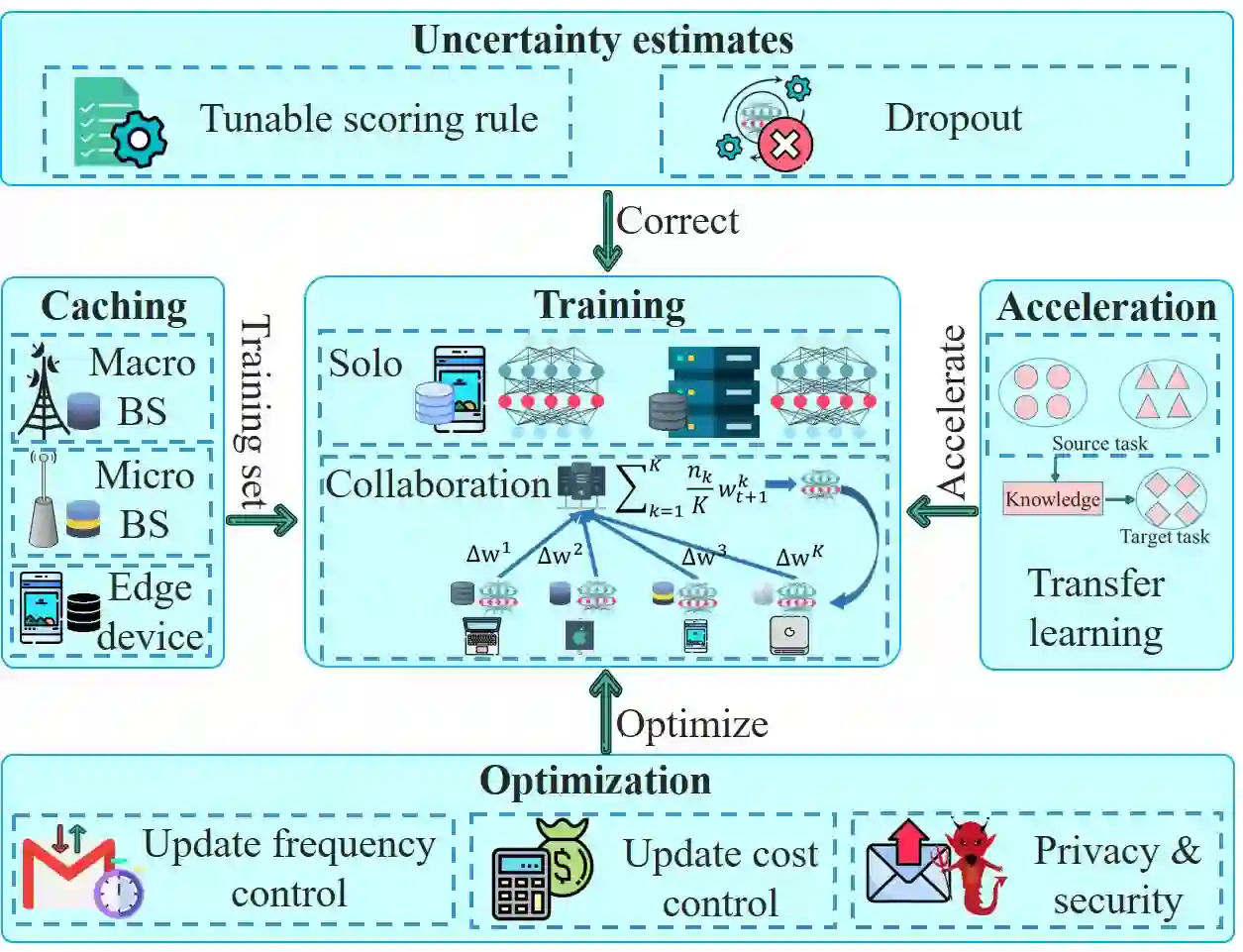
Edge intelligence refers to a set of connected systems and devices for data collection, caching, processing, and analysis in locations close to where data is captured based on artificial intelligence. The aim of edge intelligence is to enhance the quality and speed of data processing and protect the privacy and security of the data. Although recently emerged, spanning the period from 2011 to now, this field of research has shown explosive growth over the past five years. In this paper, we present a thorough and comprehensive survey on the literature surrounding edge intelligence. We first identify four fundamental components of edge intelligence, namely edge caching, edge training, edge inference, and edge offloading, based on theoretical and practical results pertaining to proposed and deployed systems. We then aim for a systematic classification of the state of the solutions by examining research results and observations for each of the four components and present a taxonomy that includes practical problems, adopted techniques, and application goals. For each category, we elaborate, compare and analyse the literature from the perspectives of adopted techniques, objectives, performance, advantages and drawbacks, etc. This survey article provides a comprehensive introduction to edge intelligence and its application areas. In addition, we summarise the development of the emerging research field and the current state-of-the-art and discuss the important open issues and possible theoretical and technical solutions.
翻译:边缘情报的目的是提高数据处理的质量和速度,保护数据的隐私和安全。虽然最近出现了,但从2011年到现在,这一研究领域显示了过去五年来爆炸性的增长。我们在本文件中对边缘情报周围的文献进行了彻底和全面的调查。我们首先根据与拟议和部署的系统有关的理论和实践结果,确定了边缘情报的四个基本组成部分,即边缘追踪、边缘训练、边缘推断和边缘倾斜。然后,我们通过审查四个组成部分的研究结果和观察,对解决办法的现状进行系统分类,提出包括实际问题、采用的技术和应用目标在内的分类。我们从采用的技术、目标、业绩、优势和缺点等方面的角度,详细、比较和分析文献。本调查文章对边缘情报及其拟议和部署系统的应用领域作了全面介绍。此外,我们总结了当前和当前技术领域可能发生的研究领域和技术问题。