视频分割技术登录移动端,提供便利便利实时抠图服务。


在超级英雄电影和科幻大片扎堆的2018,有多少电影已经进入了你们的必看名单呢。丸子酱已经预见了将会住在电影院的自己。
酷炫的特效几乎是现代大片的标配,而绿幕则是这些的特效基础。绿幕运用的技术是色差抠像,通过电脑精确识别像素上的颜色,然后将所有的绿色去掉,这样抠像就完成了,然后就可以加入特效了。

相信大家都看过少年派的奇幻漂流中那只萌萌哒的老虎。

还有龙妈那只“威猛的”巨龙。
说起来很简单,但有一个问题就是,电脑会将所有的绿色去掉,如果有的绿色不想去掉怎么办呢?从电脑技术来说,并没有什么办法,往往是从幕布颜色的方面来改善,比如运用蓝幕布,不够欧美人大多拥有蓝眼睛,这并不是一个什么好的方法,对亚洲人来讲,就没有什么问题。不过,影视作品中蓝色的出现频率极大,比如衣服、汽车、建筑物甚至天空,所以我们常见的都是绿幕。同时绿幕的使用的也存在许多问题。
绿幕作为被大众所熟知的一种视频分割技术,却是离普罗大众最远的技术。与此同时还存在着另外一种视频分割方式或许更适合生活,就是直接将场景中的前景从背景中分离出来,并将两者作为不同的视觉层。不过这项技术传统操作方式是通过手工,即对一帧帧图像进行抠图,这使得时间和成本大幅度的上升了。
为了使该技术能够达到消费级别,让手机用户能够利用摄像头实时创造抠图效果,谷歌提出了一项新的技术——机器学习视频分割技术。
同时将该技术首先应用在了自家Youtube应用刚刚推不到半年的stories(类似于小视频)功能,目前仅限于移动端测试版。允许创作者替换和修改背景,毫不费力地增加视频的产品价值而无需专业设备。

谷歌利用的是机器学习的卷积神经网络来解决语义分割任务。同时为了将该技术应用于手机,研究人员设计了适合手机的训练流程和网络构架来解决了遇见的问题。
首当其冲的肯定是受制于手机的运算能力,方案必须是轻量级的,并且还要保证实时分割速度是当前最先进的照片分割技术的10~30倍,需要达到每秒30帧的分割速度。
为了给机器学习提供高质量的数据,研究人员标注了成千上万的图像。这些图像包含了广泛的前景姿势(简单点说,自拍咯)和背景环境。标注的内容包括诸如头发、眼镜、脖子、皮肤、嘴唇等前景姿势的元素。而背景标签普遍能达到人工标注质量的98%的交叉验证结果。

另外一个重要的问题就是,视频模型应该利用时间冗余(相邻帧看起来相似)并展现时间一致性(相邻结果应该是相似的)。谷歌设计的分割任务是为每个视频的输入帧(三个通道,RGB)计算二进制掩码,将前景从背景分割。在保持时间一致性时,目前方法是用LSTM和GRU,对算力要求太高了。不适用于手机。
因此,研究人员首先将前一帧的计算掩码作为先验知识,并作为第四个通道结合当前的RGB输入帧,以获得时间一致性。这样,就能节省算力,拿到的片子视觉上还满足连贯的要求。
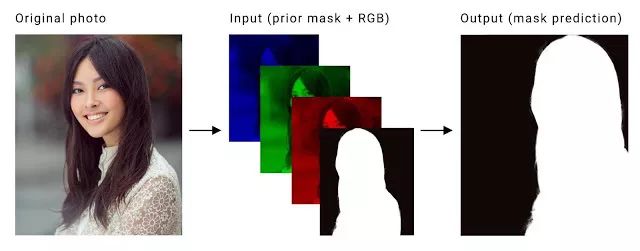
这样,正常情况下的工作就完成了。但在训练之前,我们还要考虑一种情况,如果在视频拍摄过程中突然有其他人闯入怎么办?为了让模型能够强有力地处理这些问题,研究人员用多种方式转换每张照片的标注真值,并将其作为前一帧的掩码:
清空前面的掩码(Mask):训练网络已正确处理第一帧和场景中的新目标,这将模拟出现在相机镜头内的人的场景。
标注真值掩码的仿射变换:根据 Minor 转换训练神经网络以传播和调整前一帧的掩码,而 Major 转换将训练网络以理解不合适的掩码,并丢弃它们。
转换后的图像:对当前帧做羽化处理,优化抠图后的毛边,模仿镜头在快速移动或旋转时候的情境。

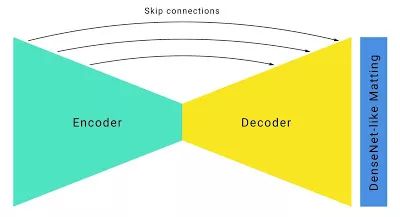
在构建网络构架的时候,通过修正后的输入、输出,研究人员构建了一个标准的沙漏型分割网络构架,并增加了一下改进。
通过使用有较大步幅(strides=4)的大卷积核来检测高分辨率RGB输入帧的目标特征从而节省了算力,所以使用较大的卷积核几乎不会影响计算成本。
通过大幅度缩减采样,结合像U-Net这样的跳过连接来回复上采样中恢复低级特征从而提高了速度。
为了进一步提高速度,谷歌研究人员优化了默认ResNet瓶颈。在论文《Deep Residual Learning for Image Recognition》中,将网络中间信道的256个信道压缩为64个。然而,研究人员注意到在更为激进地压缩到16或32个信道后,质量并没有显著下降。
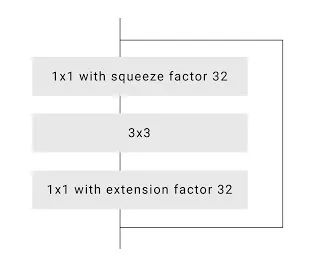
为了细化和提高边缘的准确性,研究人员为神经网络上层加入了一些DenseNet层,其分辨率与Neual Matting相同。
这些修改的最终结果是神经网络在手机上的运行速度非常快,在iPhone 7上实现了100+FPS,在Pixel 2上实现了40+FPS,并具有很高的准确性(在验证数据集上达到了94.8%IOU),在Youtube stories中能提供各种平滑的展示效果。

虽然谷歌这项技术只在Youtube stories上登录。但这并不意味着我们还是只能像以前一样望墙兴叹。
同样研究移动端视频分割技术的公司还有这家NALBI,一家专注于深度学习与研究和计算机视觉技术的嵌入式系统的AI公司。号称拥有世界上最快的嵌入式系统AI计算机视觉技术。同时也致力于将视频分割技术应用于手机。
NALBI其中一个一个视频分割技术——Human segmentation ,可以将人和背景分开。
从他们的演示视频来看,能够很好的将人像和环境分离开来。

脸部的方向对于识别来说也没有大的问题。
但在移动速度过快,比如挥胳膊,识别会有一些延迟。
其实早就进入了我们的生活。常用的B612相机就应用了该技术。

snow上的效果
比如丸子酱找到的以下这三个贴纸(小伙伴找到其他的可以告诉我啊)。



这几个贴纸在照片上的效果还是十分好的。



依旧是丸子酱最喜欢的石原里美
但在视频体验中发现,这些贴纸只能够识别正脸,与演示视频中的不大一样。
除了Human Segmentation之外,NALBI还有Hair Segmentation的技术,可以识别头发,不过丸子酱并没有在B612或者snow(境外版B612)上找到有关这个技术的贴纸。

不过观看演示视频,效果也不错。无论长发如何摆动,识别的效果都很好。
YouTube和B612两家几乎是同时推出这些产品。技术的进步势必会推动相应的产品。在未来,谷歌计划将视频分割技术应用于AR服务当中。而NALIBI除了在B612上给我们带来更多的有趣贴纸,也希望能有其他的惊喜。

阅读推荐
就算你带上墨镜,挂上口罩,发际线后移二十公分。也逃不过的人脸识别







