NIPS 2018四大最佳论文出炉!陈天奇等获奖,7场重磅演讲预告

新智元报道
新智元报道
来源:NeurIPS 2018;Microsoft Reaserch
编辑:肖琴、三石、文强
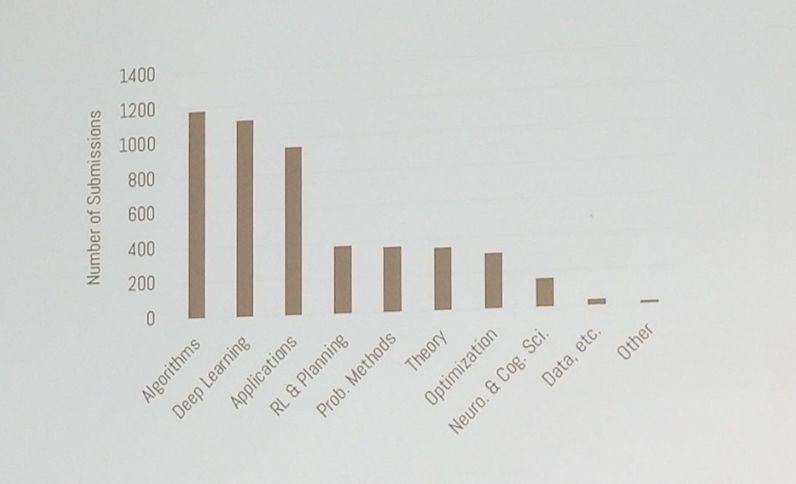
【新智元导读】NeurIPS 2018最佳论文公布,4篇最佳论文中有一篇一作是陈天琦。本届大会参会人数超过了8000人次,录取率为21%,三个最热门投稿领域依次为算法、深度学习和应用。
NeurIPS 2018终于开始,主会场排满了6500人的座位,旁边还有能容纳1500人的房间。
直播链接:https://www.facebook.com/nipsfoundation/
今年的大会主席是谷歌大脑的Samy Bengio,他也是“深度学习三巨头”之一Yoshua Bengio的弟弟。程序主席是微软研究院的Hanna Wallach,同样担任联席程序主席的还有谷歌大脑的Hugo Larochelle、奥斯汀大学及Facebook AI的Kristen Grauman,以及米兰大学的Nicolò Cesa-Bianchi。幸与不幸,这届NIPS——“NeurIPS”,中国或者华人学者并无出任大会组织或管理层。
全新的NeurIPS大会Logo
但是,中国公司依然活跃在大会赞助商名单里,无论怎么说,毕竟是人工智能领域一年一度最负盛誉的学术会议之一。
根据大会主席在Opening Remarks透露,本届会议参会(注册)人数直逼9000人大关,投稿超过5000篇,论文录取率为21%,最热门的投稿领域是算法,其次是深度学习,再次是应用。
本届大会有一天的Expo Day,9场Tutorial,39个Workshop(从118个提交方案中选出),8场竞赛(提交了21个),20个Demo(提交了76个),还有专为女性、拉丁人、黑人和LGBT人群设立的分会场。
还是先来看最佳论文奖。今年的最佳论文一共有4篇。值得庆贺的是,陈天琦等人的Neural Ordinary Differential Equations也在其中。
Neural Ordinary Differential Equations
Tian Qi Chen · Yulia Rubanova · Jesse Bettencourt · David Duvenaud
链接:https://arxiv.org/abs/1806.07366

摘要:我们提出一种新的深度神经网络模型。我们使用神经网络参数化隐藏状态的导数,而不是指定一个离散的隐藏层序列。利用黑盒微分方程求解器计算网络的输出。这些连续深度模型具有恒定的存储成本,可以根据每个输入调整其评估策略,并且可以显式地以数值精度换取速度。我们在连续深度残差网络和连续时间潜在变量模型中证明了这些性质。我们还构建了continuous normalizing flows,这是一个可以通过最大似然进行训练、而无需对数据维度进行分区或排序的生成模型。对于训练,我们展示了如何在不访问任何ODE求解器内部操作的情况下,可扩展地反向传播。这允许在更大的模型中对ODE进行端到端训练。
Non-delusional Q-learning and Value-iteration
Tyler Lu · Dale Schuurmans · Craig Boutilier
链接:https://papers.nips.cc/paper/8200-non-delusional-q-learning-and-value-iteration.pdf

摘要:在Q-learning和其它形式的动态规划中,我们确定了一个基本的误差来源。当近似体系结构限制了可表达的贪婪策略类时,就会产生偏差。由于标准Q-updates对可表达的策略类做出了全局不协调的动作选择,因此可能导致不一致甚至冲突的Q值估计,从而导致病态行为,如过高/过低估计、不稳定甚至分歧。
为了解决这个问题,我们引入了新的策略一致性概念,并定义了一个本地备份流程,该流程通过使用信息集来确保全局一致性,这些信息集记录了与备份后的Q值一致的策略约束。我们证明使用此备份的基于模型和无模型的算法都可消除妄想(delusional)偏差,从而产生第一种已知算法,可在一般条件下保证最佳结果。此外,这些算法仅需要多项式的一些信息集即可。最后,我们建议尝试减少妄想偏差的Value-iteration和 Q-learning的其它实用启发式方法。
Optimal Algorithms for Non-Smooth Distributed Optimization in Networks
Kevin Scaman · Francis Bach · Sebastien Bubeck · Laurent Massoulié · Yin Tat Lee
链接:https://arxiv.org/abs/1806.00291

摘要:在这行工作中,我们利用计算单元网络,研究了非光滑凸函数的分布优化问题。我们在两个正则性假设下研究这个问题:(1)全局目标函数的Lipschitz连续性,(2)局部单个函数的Lipschitz连续性。在局部正则性假设下,我们提出第一个最优一阶分散算法——多步原对偶算法(MSPD),并给出了相应的最优收敛速度。值得注意是,对于非光滑函数,虽然误差的主导项在
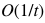
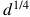
Nearly Tight Sample Complexity Bounds for Learning Mixtures of Gaussians via Sample Compression Schemes
Hassan Ashtiani · Shai Ben-David · Nick Harvey · Christopher Liaw · Abbas Mehrabian · Yaniv Plan
链接:https://papers.nips.cc/paper/7601-nearly-tight-sample-complexity-bounds-for-learning-mixtures-of-gaussians-via-sample-compression-schemes.pdf

摘要:我们证明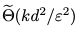
The Tradeoffs of Large-Scale Learning
Leon Bottou, Olivier Bousquet

获得经典论文奖的这篇论文发表于2007年,作者是普林斯顿NEC实验室的Leon Bottou和Google的Olivier Bousquet。
Léon Bottou 因在机器学习和数据压缩方面的工作而著名,他提出了 Stochastic gradient descent 这个最基本的机器学习算法,这个算法本身就是一种近似最优化算法,他也是 DjVu 图像压缩技术的发明者之一。Olivier Bousquet 任职于 Google,从事机器学习的相关研究。
这篇论文主要提出了一种理论框架,来衡量机器学习中近似最优化方法的效果。分析结论发现,对于小规模数据和大规模数据,近似最优化算法的 tradeoff 是不相同的。
论文摘要
这篇论文的贡献是开发了一个理论框架,该框架考虑了近似优化对学习算法的影响。分析表明,对于小规模和大规模的学习问题,有明显的权衡。小规模学习问题受制于近似-估计的权衡,大规模学习问题需要在质量上作出不同的权衡,涉及底层优化算法的计算复杂性。例如,一个普通的优化算法——随机梯度下降,已经被证明在大规模学习问题上表现得很好。
看完今年的NeurIPS论文数据,接下来自然想知道历年来的数据。正好,微软学术(Microsoft Academic)对12年的NeurIPS做了分析。
NeurIPS论文产出
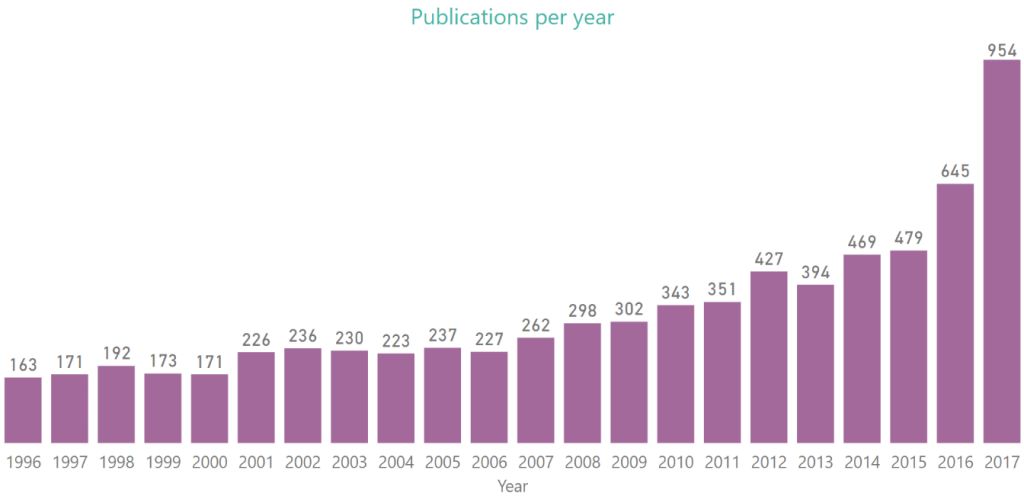
下表显示了会议从1996年开始,每年论文的数量:
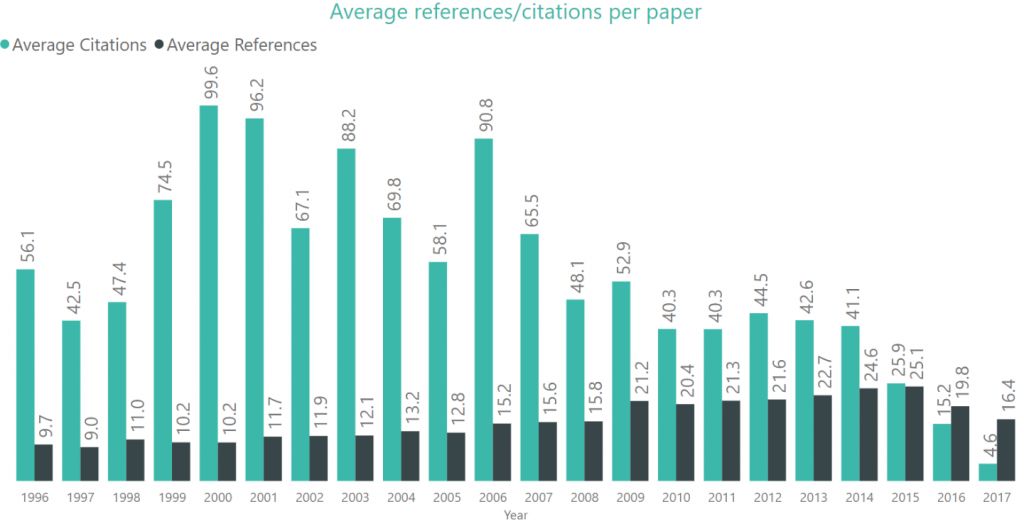
在下图中,黑色条形代表了每年论文的平均参考文献数量,从数据中可以看出,参考文献数量呈增长趋势;绿色条形代表了每年论文被引用的平均次数:
Memory of references
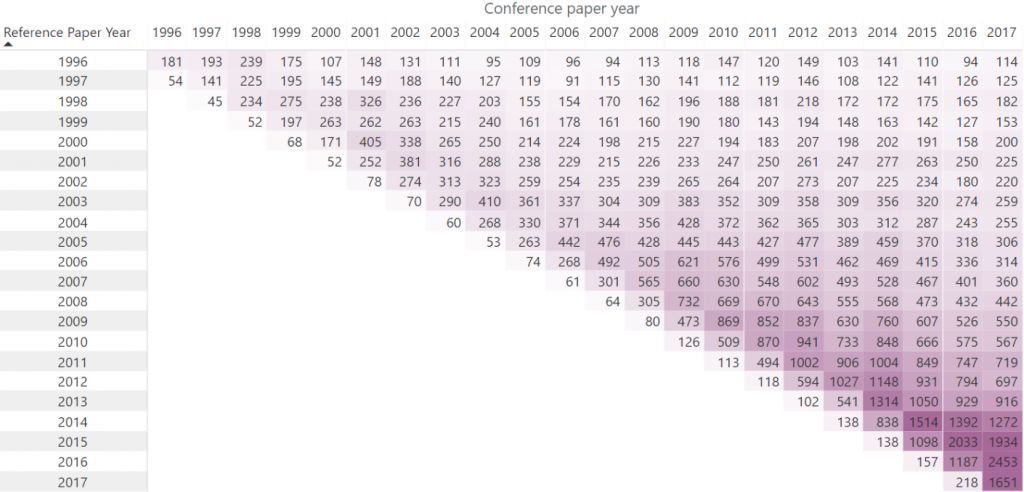
例如,在下表中,2016年,NeurIPS论文共引用了2015年发表的2033篇论文;2014年发表论文1392篇,以此类推。
Outgoing Conferences
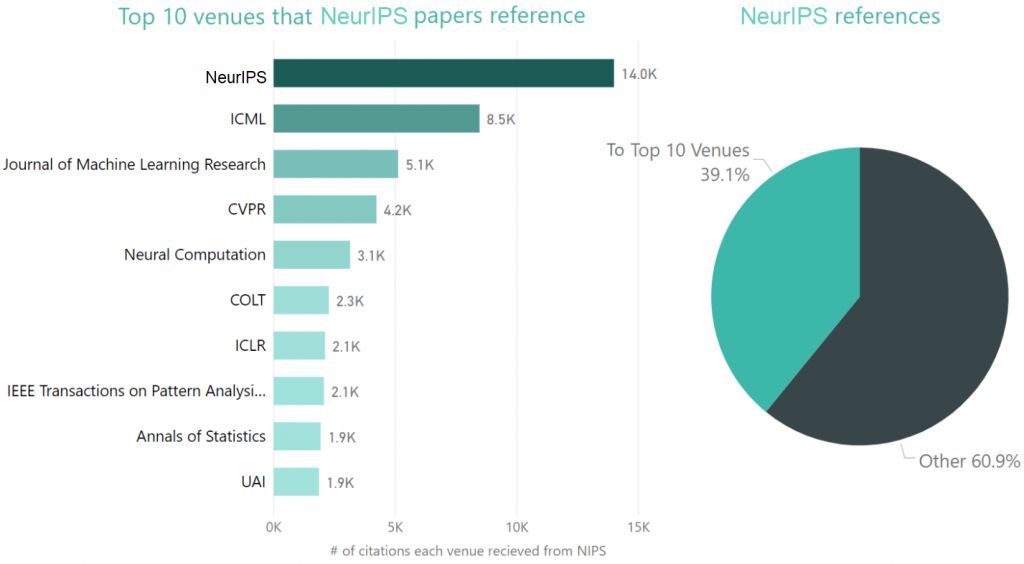
下表显示了NeurIPS论文被引用的十大“场所”。NeurIPS、ICML、Journal of Machine Learning Research和CVPR名列前四。下面的饼状图显示,在NeurIPS的论文中,最常被引用的10个“场所”几乎占了全部被引用文献的40%。
Incoming Citations
下表显示了按地点划分的引用分布情况。
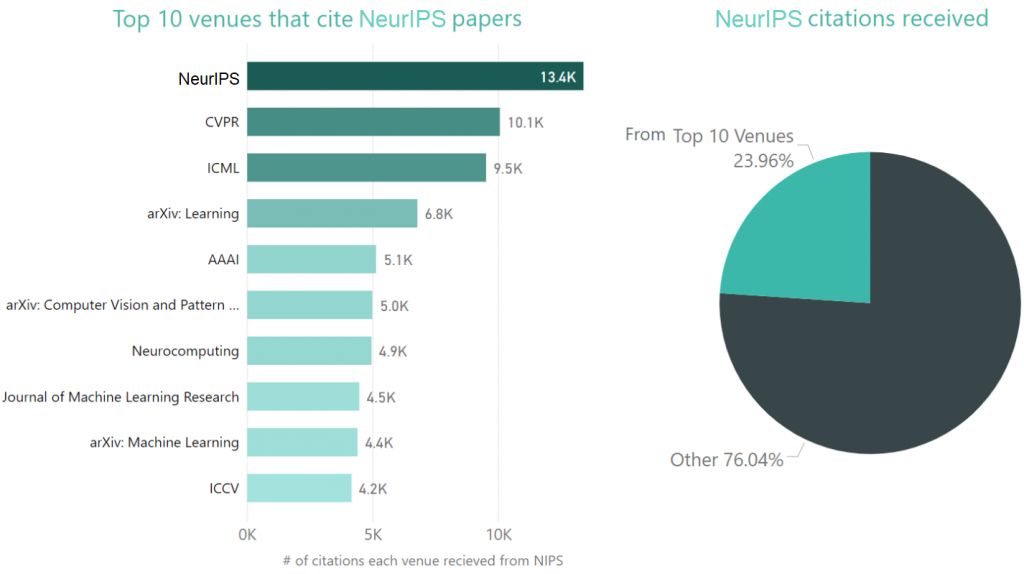
下面的饼状图显示,引用NeurIPS论文最多的前10个场所占全部引用量的24%。下面的条形图显示了引用NeurIPS论文最多的十大“场所”。同样,NeurIPS位于顶部,其次是CVPR和ICML。
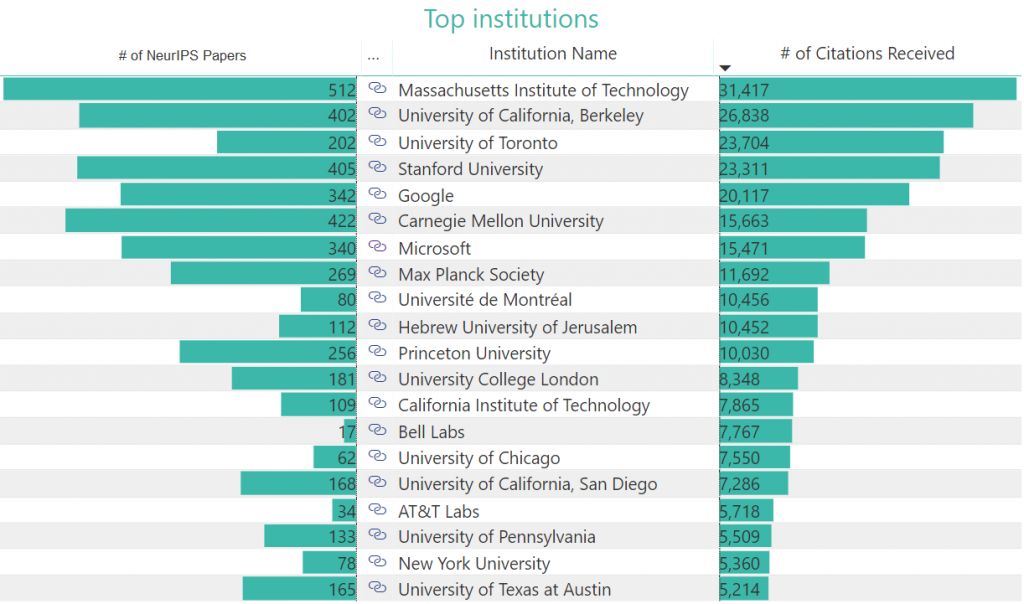
学术机构排名
下面的气泡图通过NeurIPS论文中的引用计数,来可视化NeurIPS的顶级学术机构排名。

作者排名
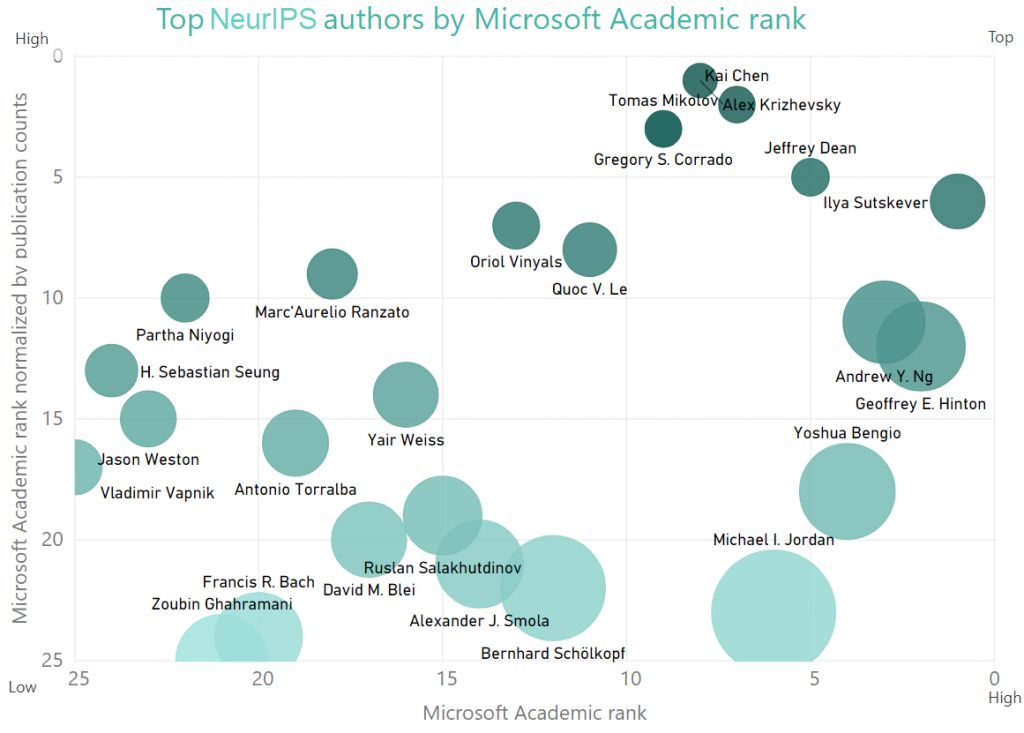
接下来的三个图表显示了不同标准下的作者排名。
气泡图显示了按引用计数排序的NeurIPS作者,气泡颜色饱和度相对于发表计数。


下面的气泡图将作者排名进行了可视化。
作者排名是根据Microsoft Academic的一个公式计算出来的。X轴代表作者的级别。作者的排名越高,他们就越靠右。Y轴按发表次数对排名进行了标准化,够发现那些可能没有发表过大量文章但却有影响力的作者。作者离顶端越近,其标准化排名就越高。当然,图表区域的右上角代表了“最高等级”。
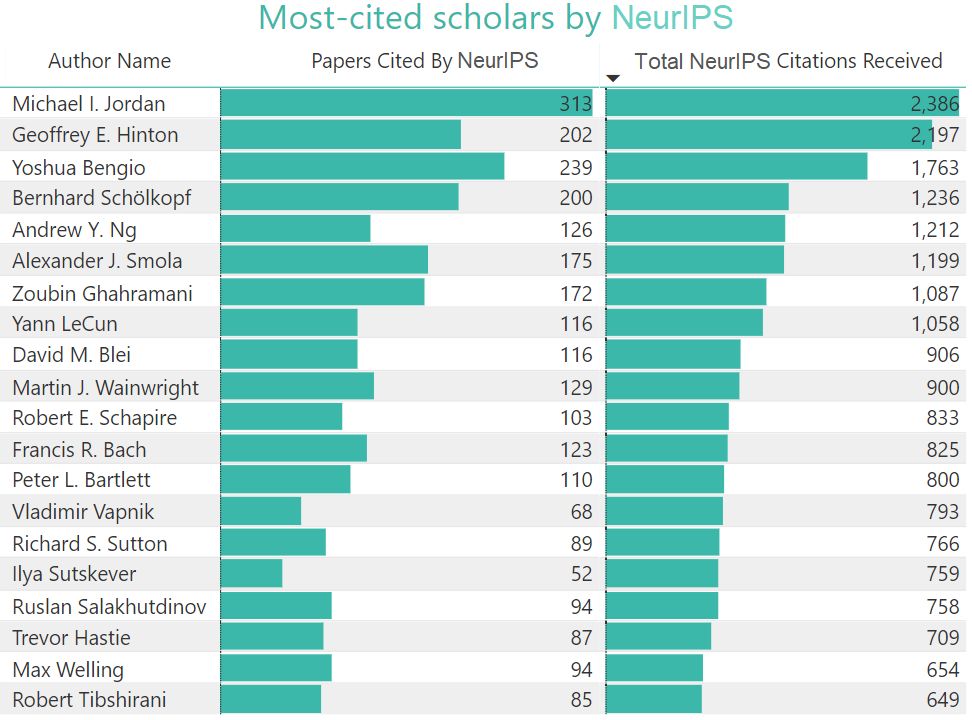
NeurIPS论文引用最多的学者
下表对被引用最多的学者进行了排名。
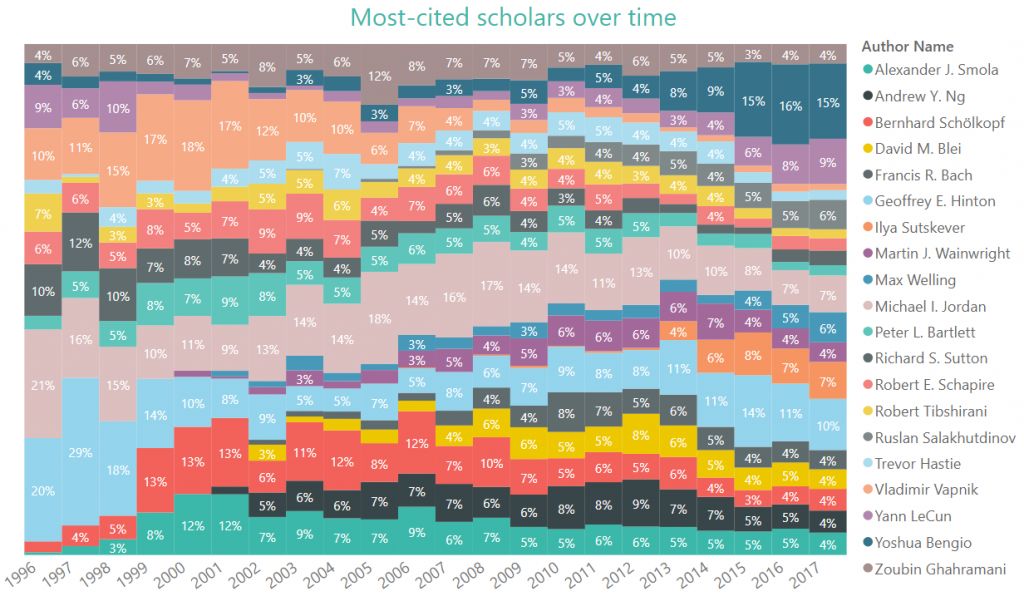
在NeurIPS被引用最多的学者中,谁将是后起之秀?
下面100%堆叠的条形图显示了前20位学者每年的NeurIPS被引用的情况。
受邀报告在一定程度上反映了大会组织者对会议主题及重点的判断。从以下7场报告中不难看出,在追求技术进步的同时关注可靠性,强调研究的程序正义,例如对开发鲁棒的AI以及AI Safety相关问题,是如今学界关注的焦点。
1、技术创新中多样性和包容性的必要性(The Necessity of Diversity and Inclusivity In Tech)
演讲人:Laura Gomez (Founder, Atipica)

Laura Gomez
2、机器学习遇到公共政策:期望什么和如何应对(Machine Learning Meets Public Policy: What to Expect and How to Cope)
演讲人:Edward Felton,普林斯顿大学

Edward Felton
AI和机器学习已经对世界产生了巨大的影响。政策制定者已经注意到这点,开始制定法律法规,并开始讨论社会应当如何管理这些技术的发展。本演讲将概述决策者如何应对新技术和AI/ML的发展过程,以及为什么建设性地参与政策过程将为该领域、政府和社会带来更好的结果。
3、身体在想什么:神经系统外的生物电计算,原始认知和合成形态学
(What Bodies Think About: Bioelectric Computation Outside the Nervous System, Primitive Cognition, and Synthetic Morphology)
演讲人:Michael Levin,塔夫茨大学

Michael Levin
大脑的计算能力并非独一无二。细菌、植物和单细胞生物都表现出学习能力和可塑性;神经系统加速了信息处理的优化,这些信息处理在生命之树中无处不在,在神经元进化之前就已经存在了。在这次演讲中,我将介绍发展生物电学(developmental bioelectricity)的基础知识,并展示新的概念和方法的进步如何使重写模式记忆成为可能,指导形态形成而无需基因组编辑。实际上,这些策略允许重新编程实现多细胞模式目标状态的生物电软件。我将展示再生医学和认知神经可塑性的应用实例,并说明未来对合成生物工程、机器人和机器学习的影响。
4、可重复、可重用和可靠的强化学习(Reproducible, Reusable, and Robust Reinforcement Learning)
演讲人:Joelle Pineau,麦吉尔大学

Joelle Pineau
近年来,我们在深度强化学习方面取得了显著的成绩。然而,最先进的深度RL方法的复现结果很少是直接的。当环境或奖励具有很强的随机性时,一些方法的高度差异会使学习变得特别困难。此外,在特定领域或实验过程中,即使是很小的扰动,结果也可能是脆弱的。在这次演讲中,我将回顾在deep RL中实验技术和报告过程中出现的挑战。我还将描述一些最近的结果和指导方针,旨在使未来的结果更具可重复性、可重用性和可靠性。
5、人类-AI信任现象的调查(Investigations into the Human-AI Trust Phenomenon)
演讲人:Ayanna Howard,佐治亚理工学院

Ayanna Howard
随着智能系统在日常活动中与人类的互动越来越充分,信任的作用必须得到更仔细的审视。信任传达了这样的概念:当与智能系统交互时,人类往往表现出与其他人类交互时相似的行为,因此可能会误解遵从机器的决策所带来的风险。偏见会进一步影响信任或过度信任的潜在风险,因为这些系统通过模仿我们自己的思维过程、继承我们自己的隐含偏见来学习。在这个演讲中,我将透过智能系统的镜头来讨论这一现象。
6、使算法值得信赖:统计科学可以为透明度、解释和验证做出哪些贡献?
(Making Algorithms Trustworthy: What Can Statistical Science Contribute to Transparency, Explanation and Validation?)
演讲人:David Spiegelhalter,剑桥大学

David Spiegelhalter
对自动化咨询系统的透明度、可解释性和经验验证的要求并不新鲜。早在上世纪80年代,基于规则的系统的支持者与基于统计模型的系统的支持者之间就有过激烈的讨论,争论的焦点就是哪个系统更加透明。
7、为软件2.0设计计算机系统(Designing Computer Systems for Software 2.0)
演讲人:Kunle Olukotun,斯坦福大学

Kunle Olukotun
使用机器学习从数据生成模型正在取代许多应用程序的传统软件开发。我们开发软件的方式发生了根本性的变化,称为Software 2.0,它极大地提高了这些应用程序的质量和部署的易用性。Software 2.0方法的持续成功和扩展必须得到为机器学习应用程序量身定制的强大、高效和灵活的计算机系统的支持。这个演讲将描述一种优化计算机系统以满足机器学习应用需求的设计方法。全栈设计方法集成了针对应用程序特性和现代硬件优势进行优化的机器学习算法,为可编程性和性能设计的领域特定语言和高级编译技术,以及同时具备高灵活性和高能效的硬件架构。
介绍赞助商也成了会议报道的惯例,毕竟是一票难求、人才济济的会议。今年的赞助商如果说有变化,那么最大的变化就是——公司覆盖的行业类型增多了。可以发现,除了谷歌、微软、亚马逊、Facebook和BAT等传统的AI巨头,越来越多的传统企业,比如投行、银行,以及创业企业出现在了赞助商名单里,这说明AI的影响确实扩大了。
钻石赞助商:

铂金赞助商:

黄金赞助商:





白银赞助商:





【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。





