牛皮!照片随便拍,「光影」任意调,MIT谷歌新研究:NLT
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

金磊 发自 凹非寺
本文转载自:量子位(QbitAI)
在摄影这件事上,「光影」简直不要太重要。
毕竟大师们摄影作品,大多都是对「光」和「影」的拿捏。

△来自俄罗斯摄影师George Mayer
而最近,MIT 和谷歌等机构联手提出了一种用神经网络「打光」的新方法,大大降低了对「光影」拿捏的门槛——神经光线传输 (Nerual Light Transport,NLT)。
例如下图所示,只要拍好人物照片,无论背景如何转换,都可以相应的调节人物身上的「光影」。

去背景后的「AI 打光」效果更加明显。

还有这样的。

虽说「打光」效果是出来了,但这画风…有点像阴间的东西了。

言归正传,继续聊聊 NLT 这项技术。
NLT——拿捏光线的一把好手
光线传输(LT)可以描述一个场景中,物体在不同光照和方向下所呈现出来的样子。
而完整地了解一个场景的 LT,还可以实现任意光照下的新视图合成。
于是,MIT 和谷歌的研究人员基于图像 LT 采集(以人体为主),提出了一种半参数的深度学习框架,来学习 LT 的神经表示,名曰NLT。
总体而言,NLT 可以单独或同时完成以下两项任务:
用定向光或HDRI图,重新照亮场景的光线真实性。
合成具有视图依赖性效果的新视图。
来看下 NLT 在不同任务下的效果。
首先是「定向重打光」 (Directional Relighting)。

可以看到人物在光线的变化下,阴影、高亮的变化非常自然。
接下来,是基于「背景图的重打光」 (Image-Based Relighting)。

从背景图中,大致可以判断光源(太阳)的方向,而随着背景图的转动,人物身上的阴影也会随之发生改变。
最后,是「视图合成+同步光源」 (View Synthesis & Simultaneous)。

除了视觉效果惊艳之外,从定性角度来看,NLT 方法也取得了不错的效果。
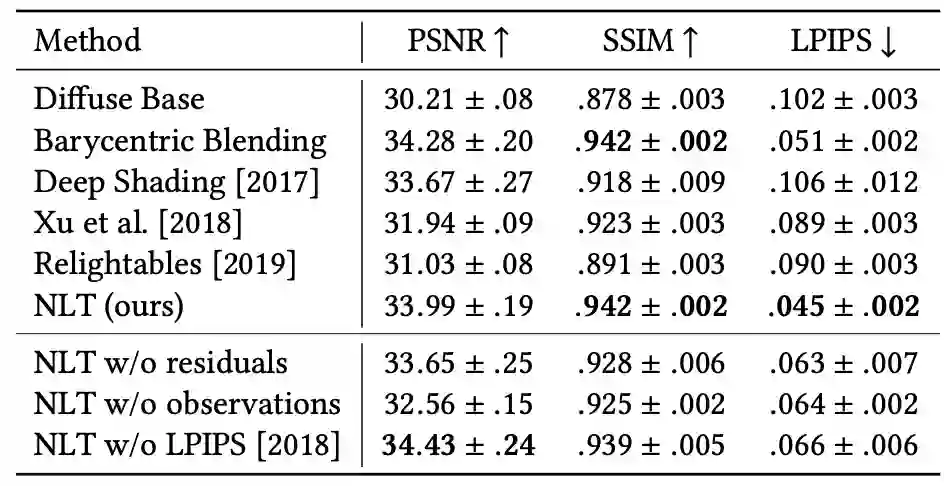
例如,在「重打光」(Redlighting)任务中,与其它基线方法相比,在 PSNR 和 SSIM 两个指标中都取得了最先进的结果。
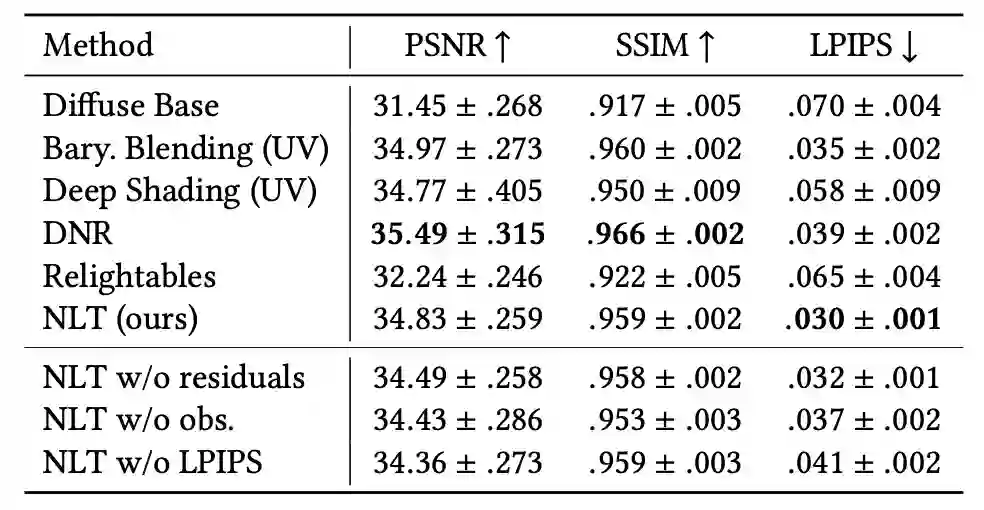
同样,在「视图合成」任务中,NLT 的结果也是相当不错。
那么,NLT 具体是如何实现这般效果的呢?
NLT模型:「查询」、「观测」两步走
NLT 的模型网络主要由2条路径构成,分别是查询路径 (Query Path)和观测路径 (Observation Path)。
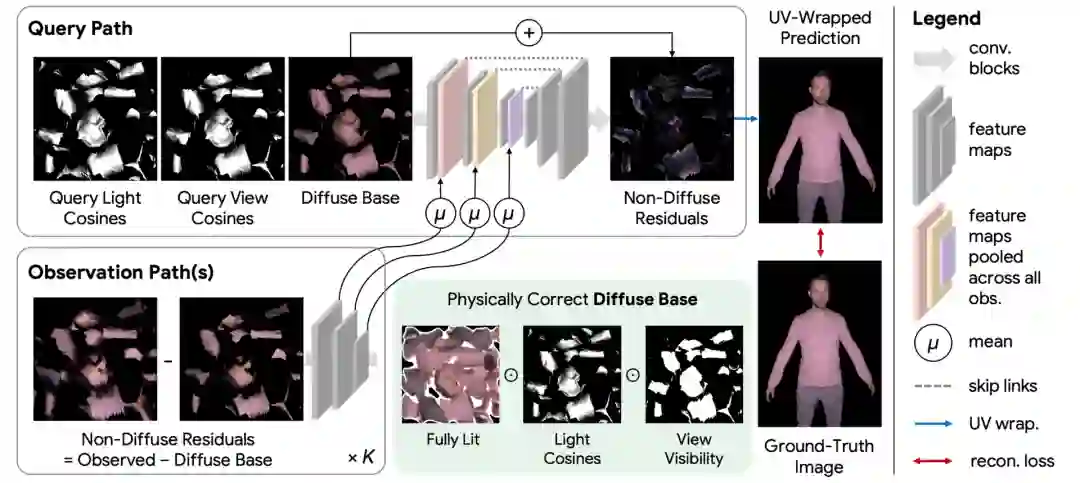
「观测路径」将附近的 K 个观测值作为输入,在目标光和观察方向周围采样,并将它们编码成多尺度特征,汇集起来用来消除对其顺序和数量的依赖。

接下来,这些汇集起来的特征将被连接到 「查询路径 」的特征激活上。
这条路径将所需的光线和观察方向,以及物理上精确的 disue base 作为输入。
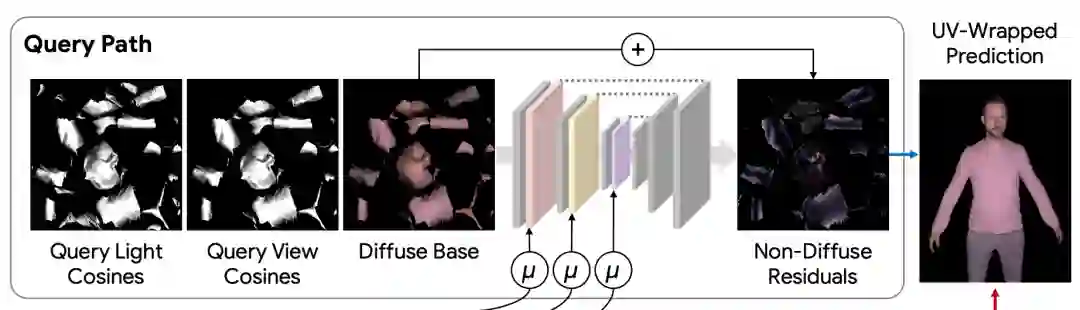
「查询路径」预测了一个残差图,该残差图被添加到diuse base上,用来产生纹理渲染。
最后,通过将深度神经网络嵌入到UV纹理空间中,便可以合成与可见光线和观看角度对应的纹理空间RGB图像。
华人小哥一作
这项研究的第一作者,是来自MIT的博士生,张修明。

张修明目前在 MIT 计算机科学与人工智能实验室(CSAIL),从事计算机视觉和计算机图形学领域的工作,尤其对重光照、视图合成和材料建模感兴趣。
另一位主要作者是Sean Fanello。

Sean Fanello是一名研究科学家,也是谷歌的经理,在谷歌领导容量性能捕获方面的工作。
研究兴趣主要包括数字人类、体积重建、高质量的深度传感和非刚性跟踪。
最后,项目将在近日开源,感兴趣的朋友持续关注下方参考链接中的信息更新。
参考链接:
http://nlt.csail.mit.edu/
推荐阅读
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!




