CMU邢波教授:基于双向语言模型的生物医学命名实体识别,无标签数据提升NER效果
【导读】生物医学文本挖掘领域近年来受到越来越多的关注,这得益于,科学文章,报告,医疗记录的电子化,使医疗数据更容易得到。这些生物医学数据包含许多生物和医学实体,如化学成分,基因,蛋白质,药物,疾病,症状等。在文本集合中准确识别这些实体是生物医学文本挖掘领域信息抽取系统的一个非常重要的任务,因为它有助于将文本中的非结构化信息转换为结构化数据。搜索引擎可以使用这种识别的实体来索引,组织和链接医学文档,这可以改善医疗信息检索效率。
实体的标识也可以用于数据挖掘和从医学研究文献中提取。例如,可以提取存储在关系数据库中的各种药物 - 基因相互作用的数据,以使计算机程序能够在它们之间进行推断。我们也可以在特定的文本实体之间进行二元关系提取,例如“疾病和症状之间关系的症状”,“药物和疾病之间的关系”的副作用,并将这些信息存储在健康知识库中。它也是更先进的自然语言理解任务中的第一步,可用于各种应用,如生物医学数据集的问答系统(QA),实体标准化及其与标准知识数据库(如MeSH)的链接。实体识别的高级应用包括自动文本摘要生成算法,可以更好地总结用户在医疗论坛中的对话,以及在自动化医疗领域使用聊天机器人。
论文:Effective Use of Bidirectional Language Modeling for Medical Named Entity Recognition

▌摘要
生物医学命名实体识别(NER)是医学文献文本挖掘的一项基础性工作,具有广泛的应用前景。 NER的现有方法需要手动特征工程来表示单词及其相应的上下文信息。基于深度学习的方法近年来越来越受到关注,因为它们的权重参数可以不需要手工设计就可以端到端学习。这些方法依赖于高质量的标记数据,因此代价很大。
为了解决这个问题,本文研究如何使用广泛可用的无标签文本数据来改善NER模型的性能。具体来说,在未标记的数据上训练双向语言模型(Bi-LM),并将其权重转移到与Bi-LM具有相同架构的NER模型,从而使NER模型有更好的参数初始化。本文评估了三种疾病NER数据集的方法,结果显示,与随机参数初始化模型相比,F1得分显着提高。还表明,双LM重量转移导致更快的模型训练。
▌详细内容
这篇文章将识别和标记实体文本的任务称为预定义的类别,如疾病,化学物质,基因等,称为命名实体识别(NER)。NER在自然语言处理(NLP)领域一直是一个被广泛研究的任务,在医学领域已经有许多应用NER的机器学习方法的作品。针对医学领域构建具有高精度和高召回率的NER系统是一个相当具有挑战性的任务,因为数据的语言差异很大。
首先,一个简单的基于字典的方法只能进行精确的匹配,不能正确地标记文本中含糊不清的缩写。例如,术语“STD”可以指短语“Sexually Transmitted Disease)性传播疾病”或是"Internet Standard(互联网标准)"。
其次,临床文本中存在多种形式的实体名称使用,可能导致实体链接和规范化问题。一个例子是以“淋巴细胞性白血病”,“无细胞白血病”,“淋巴性白血病”等不同形式出现的疾病“白血病”。
第三,由于蛋白质等生物医学实体的词汇相当广泛,相当迅速,这使得实体识别的任务更加具有挑战性,因为难以创建具有广泛覆盖范围的标记训练样例。例如,最近发现的诸如“小类人类样肽”(SHLPs 1-6)的蛋白质可能在新的文章中以缩写形式出现,并且这可能导致通过在无关例子上训练的NER标签的错误预测。而且,与一般文本相反,医学领域的实体可以具有更长的名称,这可以容易地导致NER标记器错误地预测所有标记。
最后,用于NER任务的最先进的机器学习方法依赖于高质量的标记数据,这是昂贵的,因此仅在有限数量的情况下可用。因此,需要能够利用容易获取的未标记数据的方法来改进其监督变体的性能。

文中图1是医疗文本中的一些示例。Disease实体是红颜色高亮显示。,以及anatomical实体是黄颜色高亮显示。
这篇文章提出一种方法,使用未标记的数据来预训练使用相关任务的NER模型的权重。具体来说,文章中在前后两个方向进行语言建模,以预训练NER模型的权重,后者使用监督训练数据进行精细调整。提出的NER模型在序列级应用双向长时短期记忆(Bi-LSTM),已经显示在每个时间步骤中有效地建模中心词周围的左右上下文信息,并且这种基于上下文的词表示帮助消除缩写的歧义。
Bi-LSTM还将“淋巴母细胞白血病”,“无细胞白血病”及其各种形式的术语映射到一个常见的潜在空间中,从而捕捉到短语中的语义含义,因此可以很容易地归一化为一种常见的实体类型。由Bi-LSTM在潜在语义空间中的词语境的强有力的表示也可以帮助正确分类在未见实体的情况下,因为具有相似语境的NER类被映射得更接近。
对于较长实体名称的情况,作者认为双向语言建模可以帮助学习相邻词之间的关系,并通过权重转移,NER模型应该能够学习这种模式。除了双向语言建模之外,还使用来自PubMed摘要的大量语料库中的未标记数据来训练被馈送到Bi-LSTM的单词向量。这已经表明改善了NER系统相对于随机初始化的字向量的性能。
▌模型结构
提取词级别的特征
由字符的emmbedding得到词的向量表示。
用CNN架构,最后maxpooling得到特征。
每个词的字符数不一样? 用0向量对齐,保证每个词中字符的个数是一致的
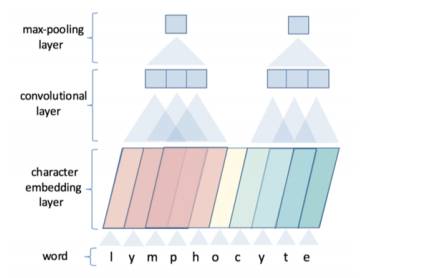
用词级别的特征进行序列化建模
词循环神经网络LSTM
Bi-LSTM:前向LSTM与后向LSTM,其中后向LSTM的输入的词是倒序的
编码层
可看成是对每个词的隐状态的仿射(一个向量空间线性变换加上平移变到另一个向量空间)
最终模型的架构如下图所示
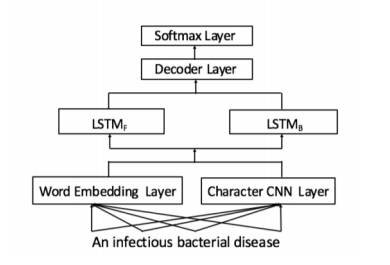
▌优化
提高模型准确度: 使用语言模型预训练(初始化)
语言模型: 目标:训练最大化给定序列的可能性的模型。 过程:计算在给定前面的词之后,下一个词的概率
和NMR一样,也有一个前向和后向的LSTM,后向的LSTM的输入为序列中词的倒序
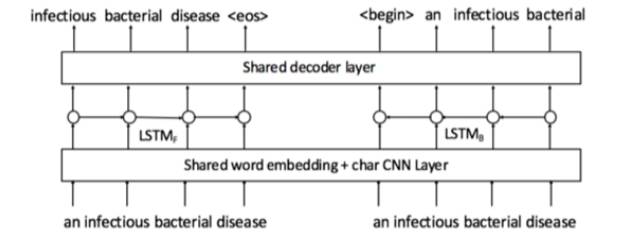
▌讨论
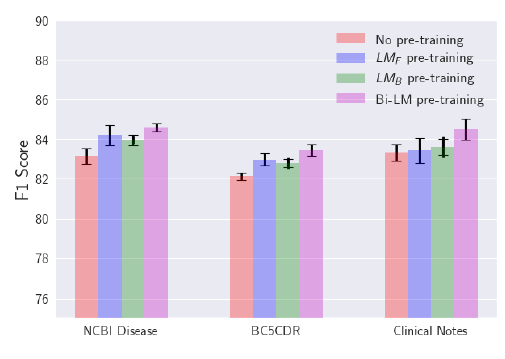
文中图6是所有数据集和模型的F1分数和误差项。
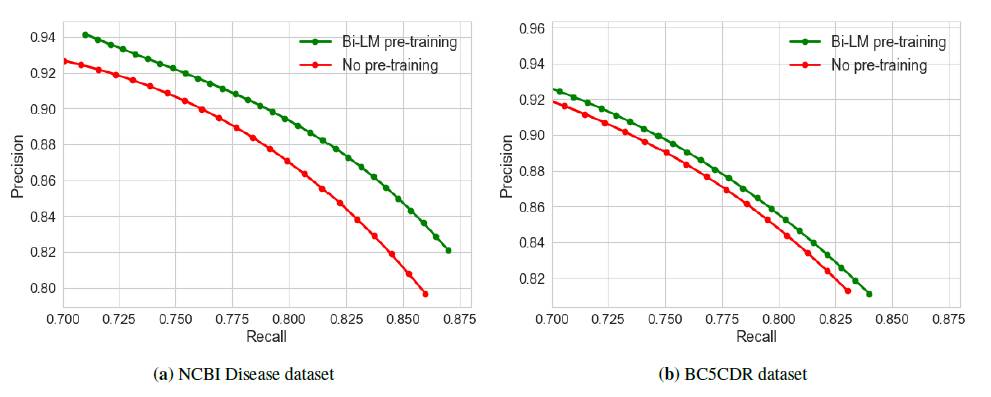
文中图7是Bi-LM模型试验预训练和没有预训练的Precision-Recall曲线。
提出的方法应用了权重的预训练,以改善模型在NER任务中的性能。在训练过程中,作者观察到模型的性能对隐藏层的输入和LSTM隐藏层的输出都是敏感的。为了达到最佳性能,需要仔细调整两个压差参数的值。模型的另一个限制是,它使用了1000多种不同尺寸的CNN滤波器来计算一个单词的基于字符的表示。与使用相同步幅的CNN滤波器相比,使用大量不同步长的CNN权重显着增加了模型参数的数量,从而大大增加了整体训练和推理时间。
使用这样的特征以及字嵌入已经显示出提高NER系统8的性能newswire文本。在生物医学领域,作者认为使用这些信息可以提高整体性能,因为医学文献有很多缩写和复杂的实体名称。
最后,作者发现,提出的模型预测未看到的实体的回想是大约50%,这是相当低的各种数据集的总体召回。改善看不见实体性能的一种可能的方法是训练更深更大的神经网络模型,以便他们可以学习复杂的信息。
作者也相信,如MeSH数据库等外部知识源的正确连接可以用来增加未看见的测试集实体的模型性能。
参考链接:https://arxiv.org/abs/1711.07908
▌特别提示-论文最新下载
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“BILM” 就可以获取最新论文 下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



