图像分类入门 1-图像分类的概念
背景与意义
所谓图像分类问题,就是已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。虽然看起来挺简单的,但这可是计算机视觉领域的核心问题之一,并且有着各种各样的实际应用。在后面的课程中,我们可以看到计算机视觉领域中很多看似不同的问题(比如物体检测和分割),都可以被归结为图像分类问题。
一个简单的例子
以下图为例,图像分类模型读取该图片,并生成该图片属于集合 {cat, dog, hat, mug}中各个标签的概率。需要注意的是,对于计算机来说,图像是一个由数字组成的巨大的3维数组。在这个例子中,猫的图像大小是宽248像素,高400像素,有3个颜色通道,分别是红、绿和蓝(简称RGB)。如此,该图像就包含了248X400X3=297600个数字,每个数字都是在范围0-255之间的整型,其中0表示全黑,255表示全白。我们的任务就是把这些上百万的数字变成一个简单的标签,比如“猫”。
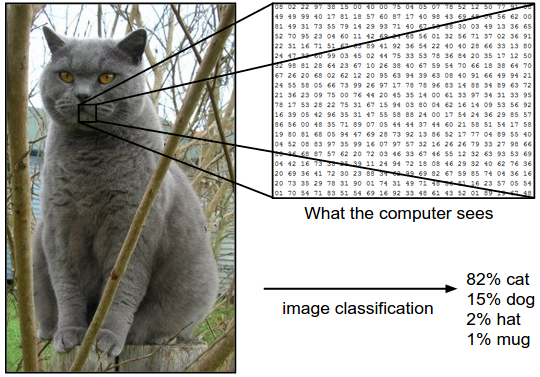
图像分类的任务,就是对于一个给定的图像,预测它属于的那个分类标签(或者给出属于一系列不同标签的可能性)。图像是3维数组,数组元素是取值范围从0到255的整数。数组的尺寸是宽度x高度x3,其中这个3代表的是红、绿和蓝3个颜色通道。
分类的种类
图像分类包括通用图像分类、细粒度图像分类等。图1展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。

图1. 通用图像分类
图2展示了细粒度图像分类-花卉识别的效果,要求模型可以正确识别花的类别。

图2. 细粒度图像分类展示
分类的难点
对于人来说,识别出一个像“猫”一样视觉概念是简单至极的,然而从计算机视觉算法的角度来看就值得深思了。我们在下面列举了计算机视觉算法在图像识别方面遇到的一些难点,要记住图像是以3维数组来表示的,数组中的元素是亮度值。
- 视角变化(Viewpoint variation):同一个物体,摄像机可以从多个角度来展现。
- 大小变化(Scale variation):物体可视的大小通常是会变化的(不仅是在图片中,在真实世界中大小也是变化的)。
- 形变(Deformation):很多东西的形状并非一成不变,会有很大变化。
- 遮挡(Occlusion):目标物体可能被挡住。有时候只有物体的一小部分(可以小到几个像素)是可见的。
- 光照条件(Illumination conditions):在像素层面上,光照的影响非常大。
- 背景干扰(Background clutter):物体可能混入背景之中,使之难以被辨认。
- 类内差异(Intra-class variation):一类物体的个体之间的外形差异很大,比如椅子。这一类物体有许多不同的对象,每个都有自己的外形。
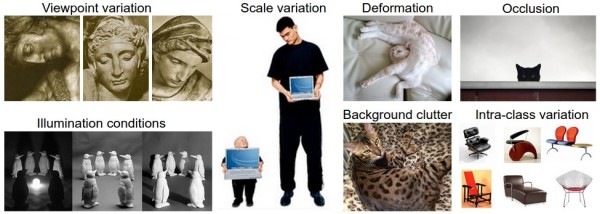
面对以上所有变化及其组合,好的图像分类模型能够在维持分类结论稳定的同时,保持对类间差异足够敏感。
常用的图像数据集
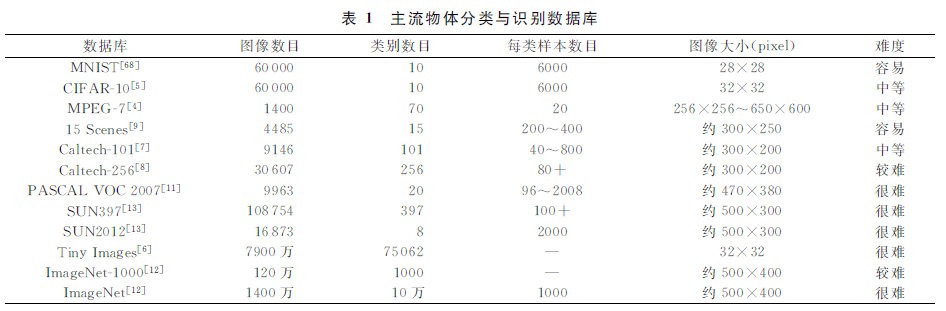
数据是视觉识别研究中最重要的因素之一,通 常我们更多关注于模型、算法本身,事实上,数据在 视觉任务中的作用越来越明显.大数据时代的到来, 也使得研究人员开始更加重视数据.在数据足够多 的情况下,我们甚至可以使用最简单的模型、算法, 比如最近邻分类、朴素贝叶斯分类器都能得到很好 的效果.鉴于数据对算法的重要性,我们将在本节对 视觉研究中物体分类与检测方面的主流数据集进行概 述。
MNIST 数据集
早期物体分类研究集中于一些较为简单的特定 任务,如OCR、形状分类等.OCR中数字手写识别 是一个得到广泛研究的课题,相关数据库中最著名 的是MNIST数据库.MNIST是一个数字手写识 别领域的标准评测数据集,数据库大小是60000,一 共包含10类阿拉伯数字,每类提供5000张图像进 行训练,1000张进行测试.MNIST的图像大小为 28×28,即784维,所有图像为手写数字,存在较大 的形变.
CIFAR 数据集
CIFAR-10和CIFAR-100数据库是Tiny images的两个子集,分别包含了10类和100类物 体类别.这两个数据库的图像尺寸都是32×32,而 且是彩色图像.CIFAR-10包含6万的图像,其中 5万用于模型训练,1万用于测试,每一类物体有 5000张图像用于训练,1000张图像用于测试. CIFAR-100与CIFAR-10组成类似,不同的是包含 了更多的类别:20个大类,大类又细分为100个小 类别,每类包含600张图像.CIFAR-10和CIFAR-100数据库尺寸较小,但是数据规模相对较大,非常 适合复杂模型特别是深度学习模型训练,因而成为 深度学习领域主流的物体识别评测数据集.
Caltech 数据集
Caltech-101是第一个规模较大的一般物体识 别标准数据库,除背景类别外,它一共包含了101类 物体,共9146张图像,每类中图像数目从40到800 不等,图像尺寸也达到300左右.Caltech-101是以 物体为中心构建的数据库,每张图像基本只包含一 个物体实例,且居于图像中间位置.物体尺寸相对图 像尺寸比例较大,且变化相对实际场景来说不大,比 较容易识别.Caltech-101每类的图像数目差别较 大,有些类别只有很少的训练图像,也约束了可以使 用的训练集大小.Caltech-256与类Caltech-101类 似,区别是物体类别从101类增加到了256类,每类 包含至少80张图像.图像类别的增加,也使得 Caltech-256上的识别任务更加困难,使其成为检 验算法性能与扩展性的新基准。
15 Scenes 数据集
15 Scenes是由Lazebnik等人在Li等人的13 Scenes数据库的基础上加入了两个新的场景构成的,一共有15个 自然场景,4485张图像,每类大概包含200~400张 图像,图像分辨率约为300×250.15 Scenes数据库 主要用于场景分类评测,由于物体分类与场景分类 在模型与算法上差别不大,该数据库也在图像分类 问题上得到广泛的使用
PASCAL VOC 数据集
PASCAL VOC从2005年到2012年每年都发布关于分类、检测、分割等任务的数据库,并在相应数据库上举行了算法竞赛,极大地推动了视觉研究的发展进步.最初2005年PASCAL VOC数据库只包含人、自行车、摩托车、汽车共4类,2006年类别数目增加到10类,2007年开始类别数目固定为20类,以后每年只增加部分样本.PACAL VOC数据库中物体类别均为日常生活中常见的物体,如交通工具、室内家具、人、动物等.PASCAL VOC数据库共包含9963张图片,图片来源包括filker等互联网站点以及其他数据库,每类大概包含96~2008张图像,均为一般尺寸的自然图像.PASCAL VOC数据库与Caltech-101相比,虽然类别数更少,但由于图像中物体变化极大,每张图像可能包含多个不同类别物体实例,且物体尺度变化很大,因而分类与检测难度都非常大.该数据库的提出,对物体分类与检测的算法提出了极大的挑战,也催生了大批优秀的理论与算法,将物体识别的研究推向了一个新的高度.
ImageNet 数据集
随着分类与检测算法的进步,很多算法在以上 提到的相关数据库上性能都接近饱和,同时随着大 数据时代的到来、硬件技术的发展,也使得在更大规 模的数据库上进行研究和评测成为必然.ImageNet是由Li主持构建的大规模图像数据库,图像类别按照WordNet构建,全库截止2013年共有1400万张图像,2.2万个类别,平均每类包含1000张图像.这是目前视觉识别领域最大的有标注的自然图像分辨率的数据集,尽管图像本身基本还是以目标为中心构建的,但是海量的数据和海量的图像类别,使得该数据库上的分类任务依然极具挑战性.除此 之外,ImageNet还构建了一个包含1000类物体 120万图像的子集,并以此作为ImageNet大尺度视 觉识别竞赛的数据平台,也逐渐成为物体分类算法 评测的标准数据集.
SUN数据集
SUN数据库的构建是希望给研究人员提供一个覆盖较大场景、位置、人物变化的数据库,库中的场景名是从WordNet中的所有场景名称中得来的.SUN数据库包含两个评测集,一个是场景识别数据集,称为SUN-397,共包含397类场景,每类至少包含100张图片,总共有108754张图像.另一个评测集为物体检测数据集,称为SUN2012,包含16873张图像。
Tiny images 数据集
Tiny images是一个图像规模更大的数据库, 共包含7900万张32×32图像,图像类别数目有 7.5万,尽管图像分辨率较低,但还是具有较高的区分度,而其绝无仅有的数据规模,使其成为大规模分 类、检索算法的研究基础.
我们也可以发现,物体类别越多,导致类间差越小,分类与检测任务越困难,图像数目、图像尺寸的大小,则直接对算法的可扩展性提出了更高的要求, 如何在有限时间内高效地处理海量数据、进行准确 的目标分类与检测成为当前研究的热点.
展开全文



