【论文推荐】最新5篇深度强化学习相关论文推荐—经验驱动的网络、自动数据库管理、双光技术推荐系统、UAVs、多代理竞争对手
【导读】专知内容组整理了最近强化学习相关文章,为大家进行介绍,欢迎查看!
1. Experience-driven Networking: A Deep Reinforcement Learning based Approach(经验驱动的网络:一种基于深度强化学习的方法)
作者:Zhiyuan Xu,Jian Tang,Jingsong Meng,Weiyi Zhang,Yanzhi Wang,Chi Harold Liu,Dejun Yang
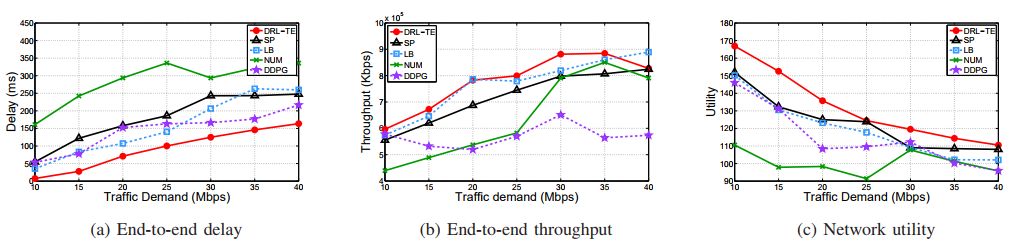
摘要:Modern communication networks have become very complicated and highly dynamic, which makes them hard to model, predict and control. In this paper, we develop a novel experience-driven approach that can learn to well control a communication network from its own experience rather than an accurate mathematical model, just as a human learns a new skill (such as driving, swimming, etc). Specifically, we, for the first time, propose to leverage emerging Deep Reinforcement Learning (DRL) for enabling model-free control in communication networks; and present a novel and highly effective DRL-based control framework, DRL-TE, for a fundamental networking problem: Traffic Engineering (TE). The proposed framework maximizes a widely-used utility function by jointly learning network environment and its dynamics, and making decisions under the guidance of powerful Deep Neural Networks (DNNs). We propose two new techniques, TE-aware exploration and actor-critic-based prioritized experience replay, to optimize the general DRL framework particularly for TE. To validate and evaluate the proposed framework, we implemented it in ns-3, and tested it comprehensively with both representative and randomly generated network topologies. Extensive packet-level simulation results show that 1) compared to several widely-used baseline methods, DRL-TE significantly reduces end-to-end delay and consistently improves the network utility, while offering better or comparable throughput; 2) DRL-TE is robust to network changes; and 3) DRL-TE consistently outperforms a state-ofthe-art DRL method (for continuous control), Deep Deterministic Policy Gradient (DDPG), which, however, does not offer satisfying performance.
期刊:arXiv, 2018年1月18日
网址:
http://www.zhuanzhi.ai/document/a7587f12fdf1318cc67016caa31fc9bd
2. The Case for Automatic Database Administration using Deep Reinforcement Learning(基于深度强化学习的自动数据库管理)
作者:Ankur Sharma,Felix Martin Schuhknecht,Jens Dittrich
摘要:Like any large software system, a full-fledged DBMS offers an overwhelming amount of configuration knobs. These range from static initialisation parameters like buffer sizes, degree of concurrency, or level of replication to complex runtime decisions like creating a secondary index on a particular column or reorganising the physical layout of the store. To simplify the configuration, industry grade DBMSs are usually shipped with various advisory tools, that provide recommendations for given workloads and machines. However, reality shows that the actual configuration, tuning, and maintenance is usually still done by a human administrator, relying on intuition and experience. Recent work on deep reinforcement learning has shown very promising results in solving problems, that require such a sense of intuition. For instance, it has been applied very successfully in learning how to play complicated games with enormous search spaces. Motivated by these achievements, in this work we explore how deep reinforcement learning can be used to administer a DBMS. First, we will describe how deep reinforcement learning can be used to automatically tune an arbitrary software system like a DBMS by defining a problem environment. Second, we showcase our concept of NoDBA at the concrete example of index selection and evaluate how well it recommends indexes for given workloads.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/f20ff5adc45065afb895823c29a2cccb
3. Reinforcement Learning based Recommender System using Biclustering Technique(基于强化学习的双光技术推荐系统)
作者:Sungwoon Choi,Heonseok Ha,Uiwon Hwang,Chanju Kim,Jung-Woo Ha,Sungroh Yoon
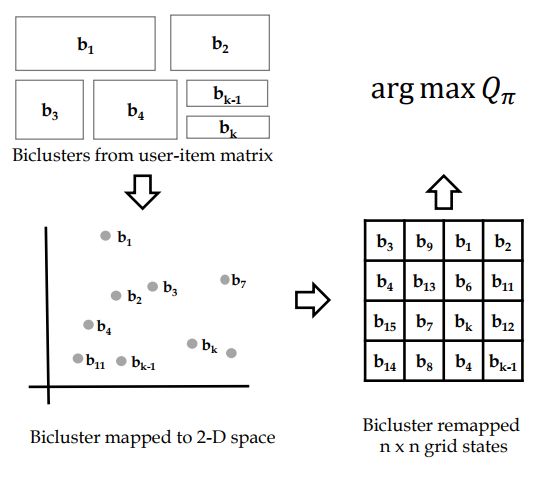
摘要:A recommender system aims to recommend items that a user is interested in among many items. The need for the recommender system has been expanded by the information explosion. Various approaches have been suggested for providing meaningful recommendations to users. One of the proposed approaches is to consider a recommender system as a Markov decision process (MDP) problem and try to solve it using reinforcement learning (RL). However, existing RL-based methods have an obvious drawback. To solve an MDP in a recommender system, they encountered a problem with the large number of discrete actions that bring RL to a larger class of problems. In this paper, we propose a novel RL-based recommender system. We formulate a recommender system as a gridworld game by using a biclustering technique that can reduce the state and action space significantly. Using biclustering not only reduces space but also improves the recommendation quality effectively handling the cold-start problem. In addition, our approach can provide users with some explanation why the system recommends certain items. Lastly, we examine the proposed algorithm on a real-world dataset and achieve a better performance than the widely used recommendation algorithm.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/ae02e4b8b10b159d2d7427439d32ca29
4. Cellular-Connected UAVs over 5G: Deep Reinforcement Learning for Interference Management(蜂窝连接的超过5G的UAVs:深度强化学习的干扰管理)
作者:Ursula Challita,Walid Saad,Christian Bettstetter
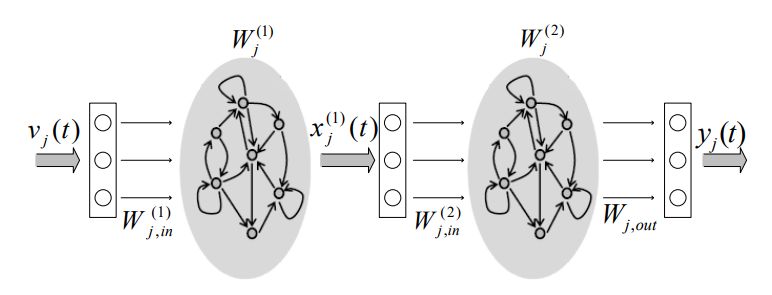
摘要:In this paper, an interference-aware path planning scheme for a network of cellular-connected unmanned aerial vehicles (UAVs) is proposed. In particular, each UAV aims at achieving a tradeoff between maximizing energy efficiency and minimizing both wireless latency and the interference level caused on the ground network along its path. The problem is cast as a dynamic game among UAVs. To solve this game, a deep reinforcement learning algorithm, based on echo state network (ESN) cells, is proposed. The introduced deep ESN architecture is trained to allow each UAV to map each observation of the network state to an action, with the goal of minimizing a sequence of time-dependent utility functions. Each UAV uses ESN to learn its optimal path, transmission power level, and cell association vector at different locations along its path. The proposed algorithm is shown to reach a subgame perfect Nash equilibrium (SPNE) upon convergence. Moreover, an upper and lower bound for the altitude of the UAVs is derived thus reducing the computational complexity of the proposed algorithm. Simulation results show that the proposed scheme achieves better wireless latency per UAV and rate per ground user (UE) while requiring a number of steps that is comparable to a heuristic baseline that considers moving via the shortest distance towards the corresponding destinations. The results also show that the optimal altitude of the UAVs varies based on the ground network density and the UE data rate requirements and plays a vital role in minimizing the interference level on the ground UEs as well as the wireless transmission delay of the UAV.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/ac9753d24e0b2cdba97a22851b3a6e6e
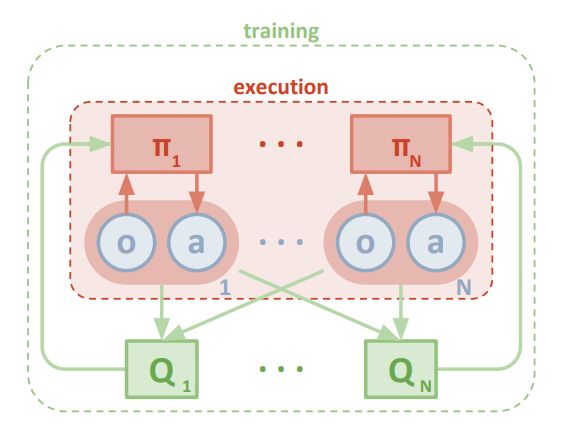
5. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments(混合合作竞争环境下的多代理竞争对手)
作者:Ryan Lowe,Yi Wu,Aviv Tamar,Jean Harb,Pieter Abbeel,Igor Mordatch
摘要:We explore deep reinforcement learning methods for multi-agent domains. We begin by analyzing the difficulty of traditional algorithms in the multi-agent case: Q-learning is challenged by an inherent non-stationarity of the environment, while policy gradient suffers from a variance that increases as the number of agents grows. We then present an adaptation of actor-critic methods that considers action policies of other agents and is able to successfully learn policies that require complex multi-agent coordination. Additionally, we introduce a training regimen utilizing an ensemble of policies for each agent that leads to more robust multi-agent policies. We show the strength of our approach compared to existing methods in cooperative as well as competitive scenarios, where agent populations are able to discover various physical and informational coordination strategies.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/9e333bc1a9010f7e008e07a135c8b29c
更多论文请上专知查看:PC登录 www.zhuanzhi.ai 点击论文查看
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



