【ACMMM17获奖比赛论文报告】让机器告诉你谁是下一个明星?- Social Media Prediction分享(附下载)
点击上方“专知”关注获取更多AI知识!
哪部电影将会爆红?谁即将获得格莱美大奖?明天哪些股票会涨?人们对未来有着许许多多的预测,这些预测不仅仅是为了娱乐,还能为那些预测正确的人带来真正的价值。因此,预测分析在学术界和工业界引起了广泛关注。
社会媒体已经走进我们的生活,我们也要学会利用社会媒体获取有用的信息。目前,研究人员根据不同行业建立了大量的社会化媒体数据集,这将有助于我们在社交媒体技术和应用方面取得重大进展。因此,中国科学院大学(CAS),中央研究院(AS),微软亚洲研究院(MSRA)联合组织了这次ACM multimedia 2017 Social Media Prediction(SMP)grand challenge。
竞赛组委会发布了一个大规模的社交媒体数据集,包括80K用户和超过770K条社交媒体内容信息,目的是使SMP数据集尽可能丰富多样,最大限度地代表社会媒体“世界”。
下面我们着重介绍其中一个赛题:流行度预测。
网址链接:http://www.acmmm.org/2017/challenge/
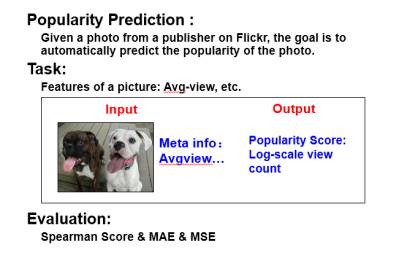
这个任务的目的是预测一个用户在社交媒体上发布不同状态的影响力,比如,给定这个用户的一张照片,自动预测照片的流行度(如Flickr上图片的浏览量(View Count)等)。由于组织方公布了一份基于Flickr平台的数据集,所以这次任务的主要目的,就是利用Flickr上用户的部分照片的浏览量,预测其余照片的浏览量。具体来说就是输入用户发布的Flickr图片特征,输出图片浏览量的对数值。评价指标为spearman’Rho, MAE和MSE。
下面我们结合本次大赛第三名的得奖团队分享的slides来仔细介绍比赛细节及竞赛思路和相关算法。
l 数据集
-元数据:

-统计数据:

-图片:

上述图片是三个用户分别按照流行度由高到低(图片浏览量log-view)来排列的一组图片。单从图片中我们其实并不能很清晰地辨别出不同流行程度的图片之间的区别,所以在考虑算法所使用的特征时,我们将重点放在了图片对应的元数据信息上,图片本身的信息将作为辅助。
l 流行度预测系统概览
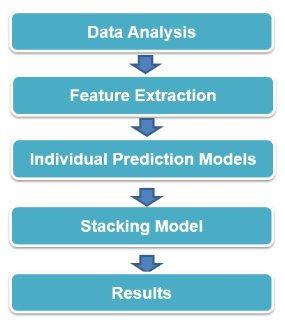
整个竞赛流程如上图所示。数据分析的目的是为下一步特征提取做铺垫,可以剔除部分无用的元数据,提高算法效率。特征提取在竞赛中是非常重要的一步,通常找到一个好特征的意义可能远远大于尝试各种各样的算法。在这次竞赛中,由于问题非常明确,利用一个用户的一部分已知浏览量(label)的数据进行训练,预测另一部分图片的浏览量,粗略地可以理解为一个回归问题,所以最开始我们采用了一些独立的回归模型,在回归模型预测结果的基础上,加入了高层学习器来提升实验效果。
l 数据分析

l 特征抓取

上述特征是能够直接从数据集中获得的特征,比如用户平均浏览量,分组的个数,每张图片对应的标签数量、标题长度、描述长度等,甚至是图片的发布时间。

上述特征是无法直接从元数据中得到,而是需要进行简单加工获得的。其中包括图片的deep特征,颜色和大小,另外,对发布时间进行切分也是很重要的一个特征提取环节。根据我们在社交媒体上的活动经验,不同时间分布的状态获得的关注度应该是不同的,实验结果也证实了我们的猜想。在这个任务中,我们将用户图片的发布时间切分为周一到周日,以及一天中的四个时段,将此作为特征加入训练,效果有一定的提升。
l 算法
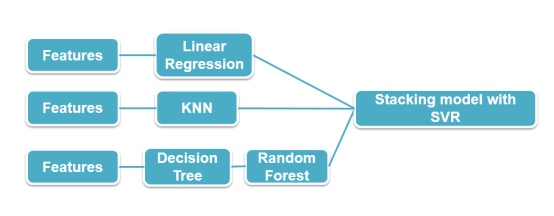

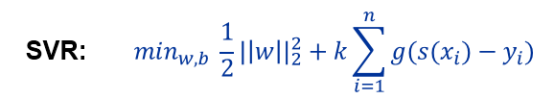
l 结果
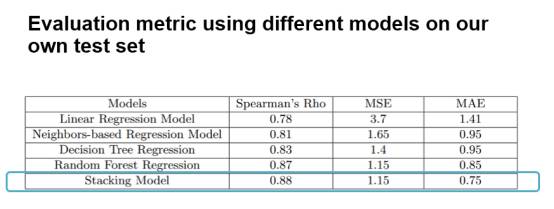
最后结果显示,融合模型的效果不错,交叉验证后spearman系数能达到0.88。
l 总结
1. 一个好的特征的效果远大于模型
2. 模型融合可能带来一定的提升效果
3. 以此延伸的一些可能应用,比如自动生成一张用户喜欢的图片、虚拟出一个受欢迎的用户等等。
文末附上相关论文和slides,欢迎交流讨论!
再谈谈其他队员在这次比赛一些方法探索:
1. 论文:Social Media Prediction Based on Residual Learning and Random Forest
网址链接:https://dl.acm.org/citation.cfm?id=3127894
在本论文中,作者提出了一个统一的模型,这个模型包含了深度残差网络和随机森林回归,用以解决社交媒体预测的问题。给出一个条目,这个条目包含图像和与之关联的社交信息,任务的主要目的就是预测出这个条目的被察看次数。在回归问题中,首先基于社交相关的信息对察看次数进行随机森林回归来预测。由于回归器倾向于学习到一个相对平滑的模型来避免过拟合,极度的高或者低的察看数是很难预测的。作者利用残差网络来改善这个问题。在初始的预测的基础上,计算预测值和真实值的残差。之后,将图像和相关的社交信息输入一个13层的ResNet,将网络的输出作为初始预测值的补偿,以补偿过高或者过低的预测。实验显示提出的方法的效果强于其他的所有方法。
2. 论文是:Multi-feature Fusion for Predicting Social Media Popularity
网址链接:https://dl.acm.org/citation.cfm?id=3127897
我们知道这次比赛的任务的目标是预测社交媒体上一个用户提交的不同条目的影响力。有很多因素影响到一个图像的流行度,不仅仅是图像本身特征,还包含用户社交信息,例如上传时的描述,甚至是上传时间等等。在这个项目中,作者提出了一种快速有效的框架。首先是对图像特征与社交特征进行选择,图像特征包括全局特征描述,例如Local Binary Pattern与Color Names,局部特征描述,例如Local Maximal Occurrence,以及深度特征。对于社交特征,用户特征,条目特征和时间特征被选择出来。除此之外,多特征的融合分别使用在线性回归,基于时间与特征聚类的矩阵分解,以及SVM模型上。之后对预测结果进行了比较分析。最终选择了效果最好的方法来对测试图像的流行度进行预测。
3. 论文题目:Combining Multiple Features for Image Popularity Prediction in Social Media
网址链接:https://dl.acm.org/citation.cfm?id=3127900
流行度预测,也就是预测指定的条目的全部用户交互数,是一类非常重要的问题并且近年来吸引了广泛的关注。它能够帮助构建很多真实场景下的应用,例如冷启动推荐,在线广告等。ACM MM的社交媒体预测任务的目标是预测社交媒体上用户发布的图像的流行度。
在本论文中,作者详述了比赛中所使用的方法。方法主要基于严格选择的特征以及回归方法。每个特征的有效性由不同模型单变量的对照实验得以验证。在上述结果的基础上,作者进一步整合了验证有效的特征,在效果最好的回归模型上进行了训练,来获得最后的结果。
4. 论文题目是:A Hybrid Model Combining Convolutional Neural Network with XGBoost for Predicting Social Media Popularity
网址链接:https://dl.acm.org/citation.cfm?id=3127902
作者提出了一个融合的模型来进行社交媒体预测,这个模型结合了XGBoost和卷积神经网络(CNN)。CNN模型被用于学习高层的基于社交信息的特征。这些高层的表示进一步的使用于XGBoost来预测发布的条目的流行度。这个方法在真实的社交媒体预测数据集上得以验证。
5. 论文题目是:Popularity Meter: An Influence- and Aesthetics-aware Social Media Popularity Predictor
网址链接:https://dl.acm.org/citation.cfm?id=3127903
社交媒体网站已经成为用户在社交网络上进行内容共享和交流的重要渠道。网站上发布的图像,甚至来自同一用户的图像,往往得到的关注度大不相同。这就引出了社交媒体中的图像流行度预测问题。为了解决这一问题,作者利用了对图像流行度有相当大影响的三个基本特征,即用户特征、元数据和美学特征。更进一步,作者使用了效果很好的预测模型来确认了作者采用的特征在预测图像流行度任务上的有效性。在真实Flickr数据集上的实验结果表明利用支持向量回归(SVR)和分类回归树(CART)的结合的方法得到了很好的结果。通过对内容和社交行为特征的理解,本文的研究成果也有助于为内容推荐和广告投放等重要应用设计更好的算法。
特别提示:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“ SMP” 就可以获取所有ACM获奖比赛论文报告的pdf下载链接~~
特别提示:
专知,为人工智能从业者提供专业可信的AI知识分发服务;请登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“机器学习” 主题,直接获取查看获得关于机器学习更多的知识资料,包括链路荟萃动态资讯精华文章等资料,帮助你更好获取机器学习知识!如下图所示。
更多专知荟萃知识资料全集获取,请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【教程实战】Google DeepMind David Silver《深度强化学习》公开课教程学习笔记以及实战代码完整版
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



