基于端到端深度神经网络的说话人与语言识别综述, 163页ppt,[InterSpeech2019]昆山杜克大学李明博士
【导读】InterSpeech 是语音处理领域的顶级会议,于9月15日-- 9月20日在奥地利格拉茨召开,昆山杜克大学李明博士在会上作了题为“End-to-end deep neural network-based speaker and language recognition”的报告,本文整理了报告的主要内容,并分享了报告163页PPT,非常值得学习。

https://interspeech2019.org/program/surveys/
报告人简介
李明,男,昆山杜克大学电子与计算机工程副教授,美国杜克大学电子与计算机工程系客座教授。2005年获南京大学通信工程专业学士学位,2008年获中科院声学所信号与信息处理专业硕士学位,2013年毕业于美国南加州大学电子工程系,获工学博士学位。2013-2017年任教于中山大学卡内基梅隆大学联合工程学院及电子与信息工程学院,副教授,博士生导师。研究方向包括音频语音信息处理,多模态行为信号分析等多个方向。已发表学术论文80 余篇,其中SCI期刊论文19篇。曾担任多个知名学术会议的科学委员会成员(ICASSP, INTERSPEECH, ODYSSEY and ISCSLP)以及多个知名学术期刊的审稿人(IEEE TPAMI,TASLP, TIFS, CIM, TETC, TAC, SPL及Speech Communication等),担任Interspeech2016及2018说话人识别领域主席。荣获了2009年Body Computing Slam Contest 第一名,IEEE DCOSS 2009 会议最佳论文奖。指导学生获得ISCSLP2016最佳学生论文奖,于2011年和2012年连续两次获得了INTERSPEECH speaker state challenge 第一名。2016年被授予IBM Faculty Award。

报告:
语音信号不仅包含词汇信息,还传递说话人、语言、性别、年龄、情感等多种副语言的语音属性信息。其背后的核心技术问题是基于文本独立或文本依赖的灵活时长语音信号的话语水平监督学习。在第一部分中,我们将首先阐述说话者和语言识别的问题。在第2节中,我们介绍了传统的流程中包含不同模块的框架,即特征提取、表示、可变性补偿和后端分类。然后很自然地引入端到端思想,并与传统框架进行了比较。我们将展示特征提取和CNN层、表示和编码层、后端建模和完全连接层之间的对应关系。具体来说,我们将在这里详细介绍端到端框架中的模块,如变长数据加载器、前端卷积网络结构设计、编码(或池)层设计、损失函数设计、数据增广设计、传输学习和多任务学习等。在第4节中,我们将介绍一些使用端到端框架来解决远场和噪声条件的鲁棒方法。最后,我们将把引入的端到端框架与其他相关任务连接起来,例如说话人二值化、副语言语音属性识别、反欺骗干扰对策等。
请关注专知公众号(点击上方蓝色专知关注)
后台回复“DNNSLR” 就可以获取完整版《基于端到端深度神经网络的说话人与语言识别综述》的下载链接~
目录内容:

问题定义

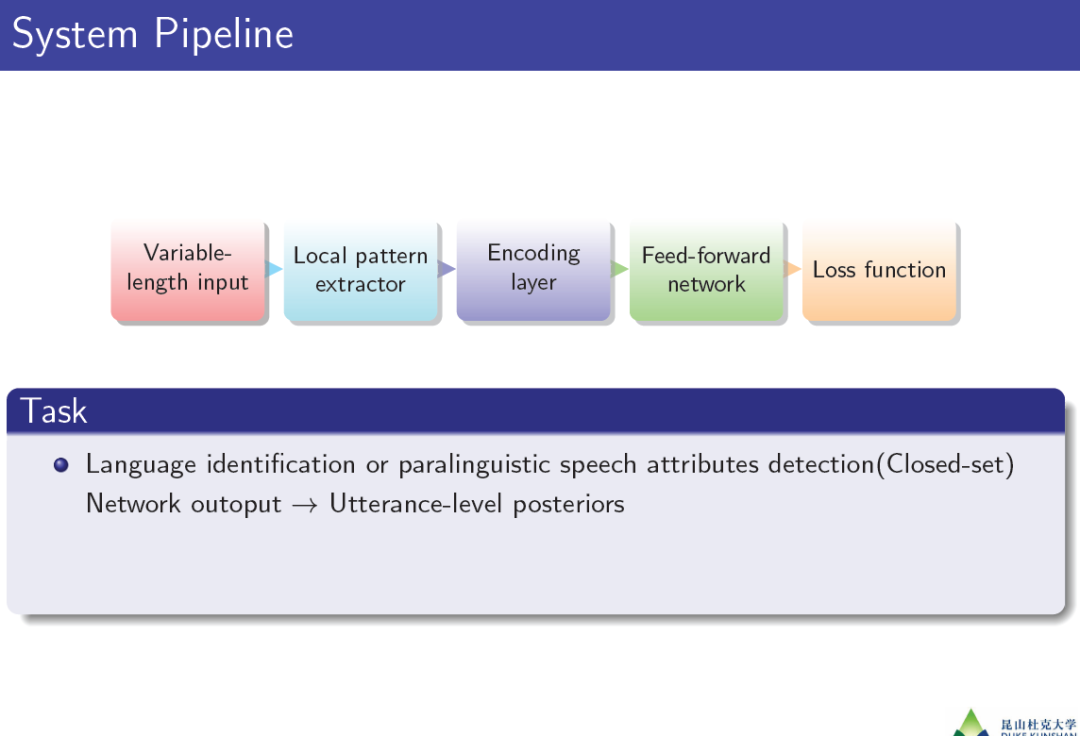
端到端框架:
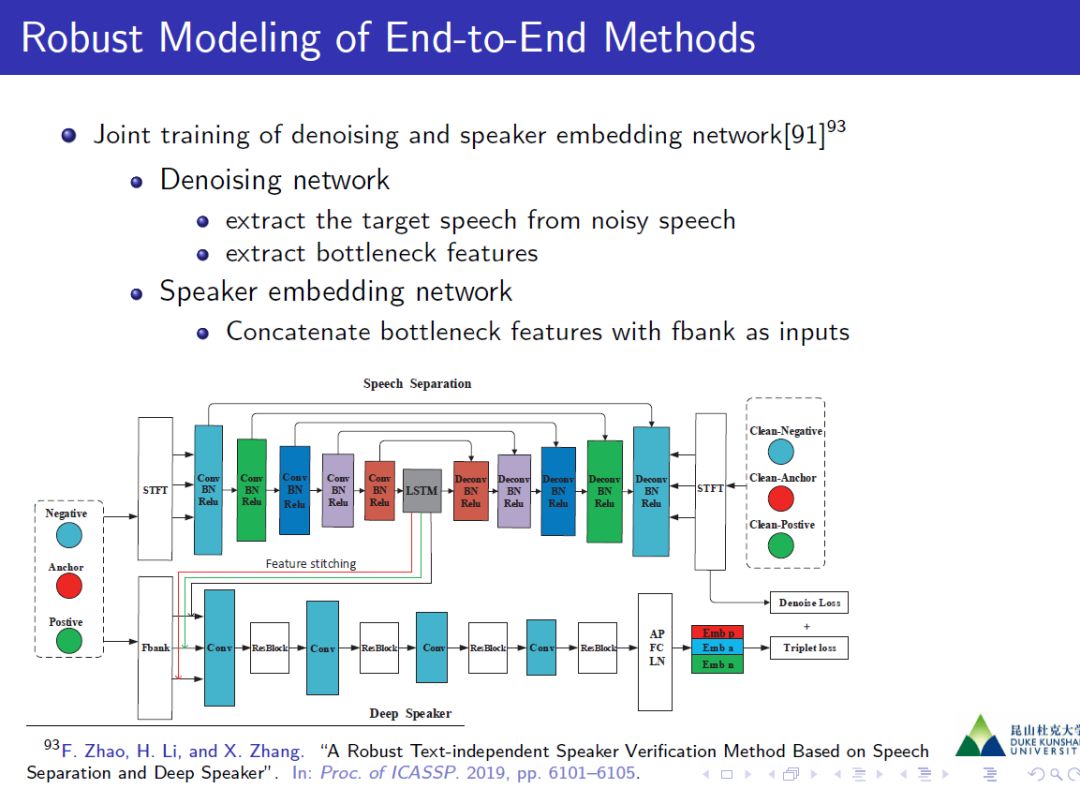
鲁棒端到端识别方法
参考文献:

更多请下载报告ppt查看
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



