初学者系列:Attentional Factorization Machines(AFM)详解
导读
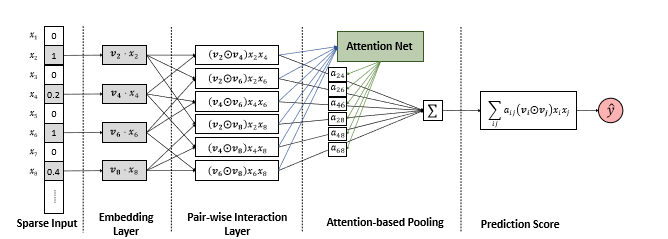
Pair-wise Interaction 层
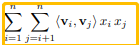
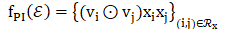
-
R_x = { (i,j) } i ∈ X, j ∈ X, j>i -
嵌入层的输出为E = { vixi } i∈X -
X为x中的非零特征集合
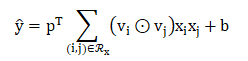
-
p∈R_k和b∈R分别表示预测层的权重和偏差。 -
在p=1,b=0时,变为FM
pair-wise interaction layer与NFM中的BI-Interaction层的操作是相似的的,都是实现FM 中的二阶特征交互。
Attention-based PoolingLayer
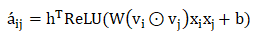
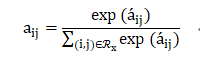
-
W∈ R_{t×k},b∈R_t,h∈R_t是模型参数,t表示注意网络的隐藏层大小(注意因子) -
a_{ij}是特征交互wij的注意力得分
在此,没有使用通过最小化预测损失来学习注意力得分(a_{ij}),是因为对于在训练数据中从未共同出现的特征,无法估计其交互的注意力得分。
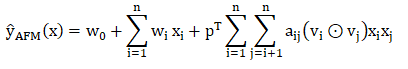
学习
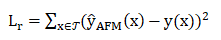
-
dropout:仅在成对交互层上使用,随机丢弃成对交互层上的神经元。 -
L2正则化:在注意力网络的权重矩阵W上加入。
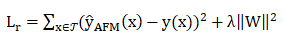
-
Python 2.7 -
Tensorflow 1.0.1
数据


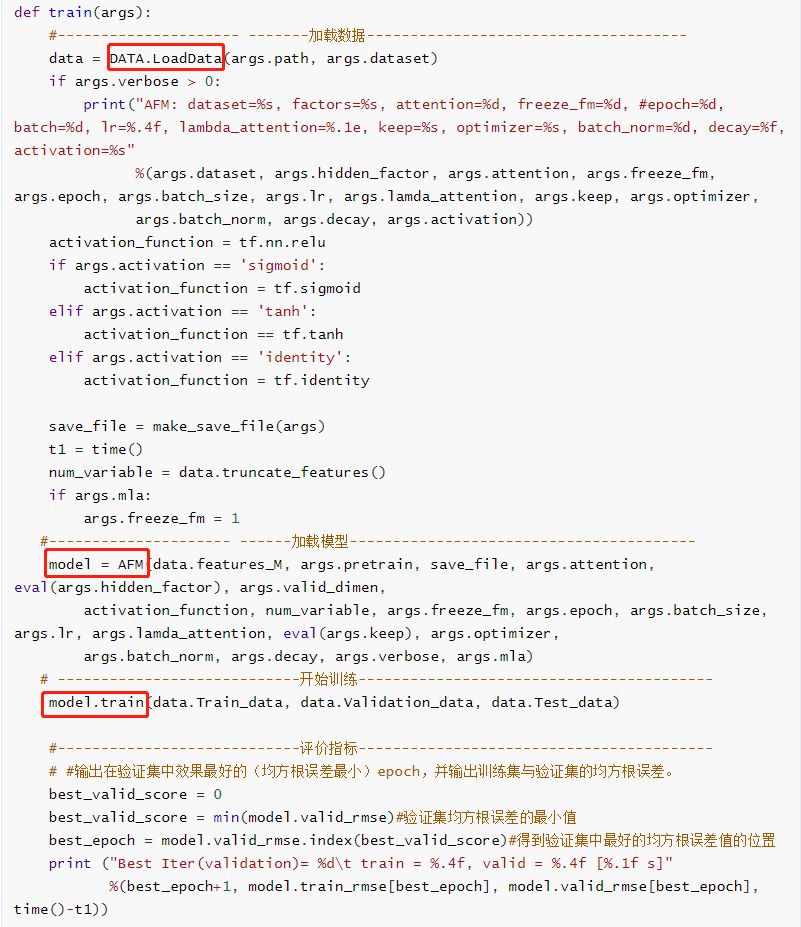
训练
-
Embedding层:跟之前的其它模型中Embedding层的实现是一样的,通过函数tf.nn.embedding_lookup()根据输入特征的索引号找到对应权重中的一行。

-
成对交互层:相当于FM中二阶交叉项特征交互的计算。

-
基于注意力的池化层:主要是通过注意力网络计算得到注意力得分 a_{ij},来学习每个特征交互的重要性。

-
输出层


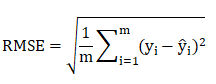

测试






展开全文



