【论文推荐】最新八篇主题模型相关论文—主题建模优化、变分推断、情绪强度、神经语言模型、搜索、社区聚合、主题建模的问题、光谱学习
【导读】专知内容组整理了最近八篇主题模型(Topic Model)相关文章,为大家进行介绍,欢迎查看!
1. Application of Rényi and Tsallis Entropies to Topic Modeling Optimization(Renyi和Tsallis熵在主题建模优化中的应用)
作者:Koltcov Sergei
机构:National Research University Higher School of Economics,
摘要:This is full length article (draft version) where problem number of topics in Topic Modeling is discussed. We proposed idea that Renyi and Tsallis entropy can be used for identification of optimal number in large textual collections. We also report results of numerical experiments of Semantic stability for 4 topic models, which shows that semantic stability play very important role in problem topic number. The calculation of Renyi and Tsallis entropy based on thermodynamics approach.
期刊:arXiv, 2018年3月1日
网址:
http://www.zhuanzhi.ai/document/816c7644baa708ae678d14b7f8abdf28
2. ADMM-based Networked Stochastic Variational Inference(基于ADMM的网络随机变分推断)
作者:Hamza Anwar,Quanyan Zhu
机构:IEEE
摘要:Owing to the recent advances in "Big Data" modeling and prediction tasks, variational Bayesian estimation has gained popularity due to their ability to provide exact solutions to approximate posteriors. One key technique for approximate inference is stochastic variational inference (SVI). SVI poses variational inference as a stochastic optimization problem and solves it iteratively using noisy gradient estimates. It aims to handle massive data for predictive and classification tasks by applying complex Bayesian models that have observed as well as latent variables. This paper aims to decentralize it allowing parallel computation, secure learning and robustness benefits. We use Alternating Direction Method of Multipliers in a top-down setting to develop a distributed SVI algorithm such that independent learners running inference algorithms only require sharing the estimated model parameters instead of their private datasets. Our work extends the distributed SVI-ADMM algorithm that we first propose, to an ADMM-based networked SVI algorithm in which not only are the learners working distributively but they share information according to rules of a graph by which they form a network. This kind of work lies under the umbrella of `deep learning over networks' and we verify our algorithm for a topic-modeling problem for corpus of Wikipedia articles. We illustrate the results on latent Dirichlet allocation (LDA) topic model in large document classification, compare performance with the centralized algorithm, and use numerical experiments to corroborate the analytical results.
期刊:arXiv, 2018年2月28日
网址:
http://www.zhuanzhi.ai/document/674d4e782a72898396ed6827e265c21e
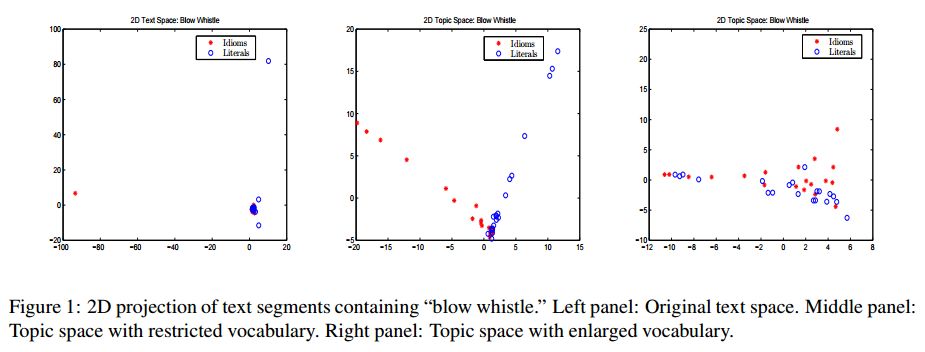
3. Classifying Idiomatic and Literal Expressions Using Topic Models and Intensity of Emotions(使用主题模型和情绪强度将习语和文字表达分类)
作者:Jing Peng,Anna Feldman,Ekaterina Vylomova
机构:Montclair State University,Bauman State Technical University
摘要:We describe an algorithm for automatic classification of idiomatic and literal expressions. Our starting point is that words in a given text segment, such as a paragraph, that are highranking representatives of a common topic of discussion are less likely to be a part of an idiomatic expression. Our additional hypothesis is that contexts in which idioms occur, typically, are more affective and therefore, we incorporate a simple analysis of the intensity of the emotions expressed by the contexts. We investigate the bag of words topic representation of one to three paragraphs containing an expression that should be classified as idiomatic or literal (a target phrase). We extract topics from paragraphs containing idioms and from paragraphs containing literals using an unsupervised clustering method, Latent Dirichlet Allocation (LDA) (Blei et al., 2003). Since idiomatic expressions exhibit the property of non-compositionality, we assume that they usually present different semantics than the words used in the local topic. We treat idioms as semantic outliers, and the identification of a semantic shift as outlier detection. Thus, this topic representation allows us to differentiate idioms from literals using local semantic contexts. Our results are encouraging.
期刊:arXiv, 2018年2月27日
网址:
http://www.zhuanzhi.ai/document/3a2e1b8fb8dfebf67b9d077c7064302e
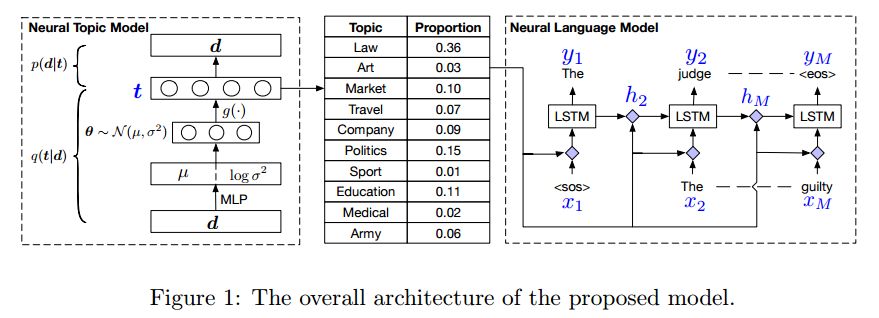
4. Topic Compositional Neural Language Model(主题组合神经语言模型)
作者:Wenlin Wang,Zhe Gan,Wenqi Wang,Dinghan Shen,Jiaji Huang,Wei Ping,Sanjeev Satheesh,Lawrence Carin
机构:Duke University,Baidu Silicon Valley AI Lab,Purdue University
摘要:We propose a Topic Compositional Neural Language Model (TCNLM), a novel method designed to simultaneously capture both the global semantic meaning and the local word ordering structure in a document. The TCNLM learns the global semantic coherence of a document via a neural topic model, and the probability of each learned latent topic is further used to build a Mixture-of-Experts (MoE) language model, where each expert (corresponding to one topic) is a recurrent neural network (RNN) that accounts for learning the local structure of a word sequence. In order to train the MoE model efficiently, a matrix factorization method is applied, by extending each weight matrix of the RNN to be an ensemble of topic-dependent weight matrices. The degree to which each member of the ensemble is used is tied to the document-dependent probability of the corresponding topics. Experimental results on several corpora show that the proposed approach outperforms both a pure RNN-based model and other topic-guided language models. Further, our model yields sensible topics, and also has the capacity to generate meaningful sentences conditioned on given topics.
期刊:arXiv, 2018年2月27日
网址:
http://www.zhuanzhi.ai/document/451aa662fdc53b3368075278ddd4a032
5. The Search Problem in Mixture Models(混合模型中的搜索问题)
作者:Avik Ray,Joe Neeman,Sujay Sanghavi,Sanjay Shakkottai
机构:University of Texas, Austin,Rheinische Friedrich-Wilhelms-Universit¨at Bonn
摘要:We consider the task of learning the parameters of a {\em single} component of a mixture model, for the case when we are given {\em side information} about that component, we call this the "search problem" in mixture models. We would like to solve this with computational and sample complexity lower than solving the overall original problem, where one learns parameters of all components. Our main contributions are the development of a simple but general model for the notion of side information, and a corresponding simple matrix-based algorithm for solving the search problem in this general setting. We then specialize this model and algorithm to four common scenarios: Gaussian mixture models, LDA topic models, subspace clustering, and mixed linear regression. For each one of these we show that if (and only if) the side information is informative, we obtain parameter estimates with greater accuracy, and also improved computation complexity than existing moment based mixture model algorithms (e.g. tensor methods). We also illustrate several natural ways one can obtain such side information, for specific problem instances. Our experiments on real data sets (NY Times, Yelp, BSDS500) further demonstrate the practicality of our algorithms showing significant improvement in runtime and accuracy.
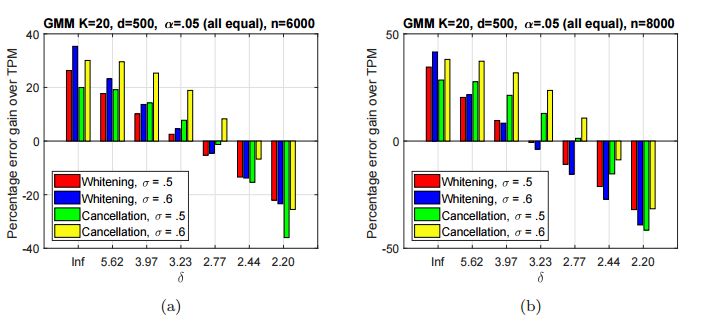
期刊:arXiv, 2018年2月25日
网址:
http://www.zhuanzhi.ai/document/f28c33c342337d98ea8d479117f3bc62
6. Learning Topic Models by Neighborhood Aggregation(通过社区聚合学习主题模型)
作者:Ryohei Hisano
机构:The University of Tokyo
摘要:Topic models are one of the most frequently used models in machine learning due to its high interpretability and modular structure. However extending the model to include supervisory signal, incorporate pre-trained word embedding vectors and add nonlinear output function to the model is not an easy task because one has to resort to highly intricate approximate inference procedure. In this paper, we show that topic models could be viewed as performing a neighborhood aggregation algorithm where the messages are passed through a network defined over words. Under the network view of topic models, nodes corresponds to words in a document and edges correspond to either a relationship describing co-occurring words in a document or a relationship describing same word in the corpus. The network view allows us to extend the model to include supervisory signals, incorporate pre-trained word embedding vectors and add nonlinear output function to the model in a simple manner. Moreover, we describe a simple way to train the model that is well suited in a semi-supervised setting where we only have supervisory signals for some portion of the corpus and the goal is to improve prediction performance in the held-out data. Through careful experiments we show that our approach outperforms state-of-the-art supervised Latent Dirichlet Allocation implementation in both held-out document classification tasks and topic coherence.
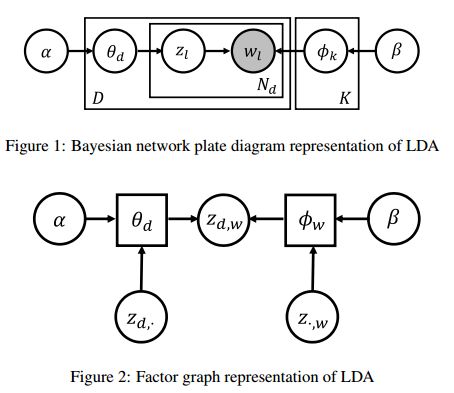
期刊:arXiv, 2018年2月22日
网址:
http://www.zhuanzhi.ai/document/9d08d8068c655f737fe07721ceefcb0b
7. What is Wrong with Topic Modeling? (and How to Fix it Using Search-based Software Engineering)(主题建模有什么问题?(以及如何使用基于搜索的软件工程修复它))
作者:Amritanshu Agrawal,Wei Fu,Tim Menzies
机构:North Carolina State Universit
摘要:Context: Topic modeling finds human-readable structures in unstructured textual data. A widely used topic modeler is Latent Dirichlet allocation. When run on different datasets, LDA suffers from "order effects" i.e. different topics are generated if the order of training data is shuffled. Such order effects introduce a systematic error for any study. This error can relate to misleading results;specifically, inaccurate topic descriptions and a reduction in the efficacy of text mining classification results. Objective: To provide a method in which distributions generated by LDA are more stable and can be used for further analysis. Method: We use LDADE, a search-based software engineering tool that tunes LDA's parameters using DE (Differential Evolution). LDADE is evaluated on data from a programmer information exchange site (Stackoverflow), title and abstract text of thousands ofSoftware Engineering (SE) papers, and software defect reports from NASA. Results were collected across different implementations of LDA (Python+Scikit-Learn, Scala+Spark); across different platforms (Linux, Macintosh) and for different kinds of LDAs (VEM,or using Gibbs sampling). Results were scored via topic stability and text mining classification accuracy. Results: In all treatments: (i) standard LDA exhibits very large topic instability; (ii) LDADE's tunings dramatically reduce cluster instability; (iii) LDADE also leads to improved performances for supervised as well as unsupervised learning. Conclusion: Due to topic instability, using standard LDA with its "off-the-shelf" settings should now be depreciated. Also, in future, we should require SE papers that use LDA to test and (if needed) mitigate LDA topic instability. Finally, LDADE is a candidate technology for effectively and efficiently reducing that instability.
期刊:arXiv, 2018年2月21日
网址:
http://www.zhuanzhi.ai/document/f1ab43948a8abb95a727b3696db50ca9
8. SpectralLeader: Online Spectral Learning for Single Topic Models
(SpectralLeader:单一主题模型的在线光谱学习)
作者:Tong Yu,Branislav Kveton,Zheng Wen,Ole J. Mengshoel,Hung Bui
机构:Carnegie Mellon University,Adobe Research,Google DeepMind
摘要:We study the problem of learning a latent variable model from a stream of data. Latent variable models are popular in practice because they can explain observed data in terms of unobserved concepts. These models have been traditionally studied in the offline setting. The online EM is arguably the most popular algorithm for learning latent variable models online. Although it is computationally efficient, it typically converges to a local optimum. In this work, we develop a new online learning algorithm for latent variable models, which we call SpectralLeader. SpectralLeader always converges to the global optimum, and we derive a $O(\sqrt{n})$ upper bound up to log factors on its $n$-step regret in the bag-of-words model. We show that SpectralLeader performs similarly to or better than the online EM with tuned hyper-parameters, in both synthetic and real-world experiments.
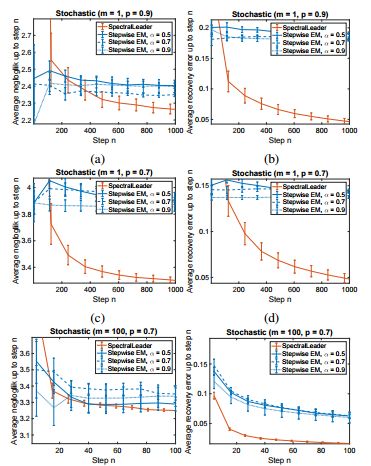
期刊:arXiv, 2018年2月17日
网址:
http://www.zhuanzhi.ai/document/5b3ee98e4c2a5958f497c391a10d6cf4
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



