【论文推荐】ICLR18论文预读-深度学习泛化研究:多层非线性复合是对最大熵原理的递归逼近实现
点击上方“专知”关注获取更多AI知识!
【导读】两天前,专知公众号发布了深度学习顶会 ICLR 2018 匿名提交论文列表,今天我们很荣幸有老师和同学来自荐他们的在ICLR2018上的工作,后续我们会不断推出论文自荐活动,也希望愿意分享自己工作和成果的老师和同学多多和我们联系,希望专知伴随着大家一起成长,共同进步。
深度学习泛化研究:多层非线性复合是对最大熵原理的递归逼近实现
【前言】
深度学习在各领域得到成功应用的一个重要原因是其优秀的泛化性能。从ICLR 2017 “RethinkingGeneralization”的最佳论文到最近Hinton“要听上一万次”的信息瓶颈理论,对深度学习泛化性的理论研究近来受到了大量关注。近日,中国科技大学、北京交通大学和中科院自动化研究所的研究人员证明了深度学习的多层线性回归+非线性激活函数的复合实际是对原始最大熵原理的一种递归逼近实现,从经典的最大熵理论为深度学习泛化性能提供了一种新的解释。另外,这个工作也从最大熵的角度解释了深度学习中存在的信息瓶颈现象以及与泛化效果相关的一些网络结构设计。文章投稿到今年的深度学习表示学习会议ICLR 2018,会议采用openreview形式,review链接:
https://openreview.net/forum?id=r1kj4ACp-¬eId=r1kj4ACp-
【正文内容】
深度学习的是近年来的研究热点,能够在拟合数据集的同时拥有极佳的泛化性,因而在许多领域取得了成功的应用。《Towards Understanding Generalization of Deep Learning: Perspectiveof Loss Landscapes》中作者通过一个toy example发现在训练样本很少的情况下一个多层全连接网络仍然具有较好的泛化性能,然而传统的kernel regression虽然polynomial kernel order增加很容易过拟合(见下图)。
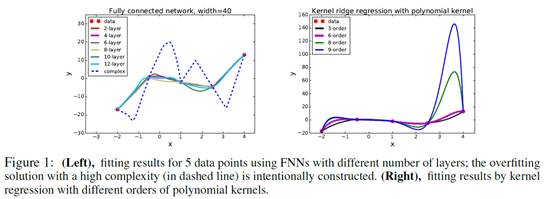
现在效果非常好的DNN,如图像识别中的ResNet、DenseNet,网络上百层,参数上千万、甚至已经远远超过训练样本的个数。经典泛化性理论,如margin bound 、VC维等,认为函数空间越复杂,泛化性能就越差,目前都不能很好地解释为什么参数众多的深度学习能够有如此优秀的泛化性能。
本文尝试从经典的最大熵理论来解释深度学习优秀的泛化性能:(1)证明了最大熵原理应用于softmax回归的充分必要条件,为特征选择和特征工程提供了理论指导;(2)并利用困难问题的分解算法,证明了以sigmoid为激活函数的DNN是最大熵模型的一个极佳近似。
1. 泛化性 v.s. 对数据集的假设
什么是泛化性?标准定义是:模型在未见过的同分布的测试集上的性能。但这一定义是对泛化性的期望,无法直接应用到指导算法的设计中。为此许多研究构建了可以实用的泛化性分析理论,如margin bound就给出了泛化误差的上界。本文的观点是,泛化能力是与模型对数据集的假设直接相关的。
所谓模型对数据集的假设,举个栗子:线性回归假设数据集线性可分,朴素贝叶斯模型假设数据集的特征条件独立——自然,如果数据集(X,Y)不满足模型的假设,模型依旧可以使用,但是泛化性能就会很受影响。从这个角度来说:
欠拟合是训练集不满足模型对数据的假设;
过拟合是训练集满足模型对数据的假设,但测试集不满足模型对数据的假设;
而正则项,是通过对模型的约束减少模型对数据的假设。
通过下面这个经典的介绍欠拟合/过拟合的例子来重述上面的讨论。蓝色的实线假设数据满足线性关系,而实际上训练集的五个点是不满足,导致underfitting。红色的虚线假设数据满足5次多项式关系,虽然完美拟合训练集数据,但无法很好地估计测试数据,导致overfitting。可以看出,对数据集给出额外的假设,无论是否符合训练集数据,都有可能造成模型泛化性能的下降。
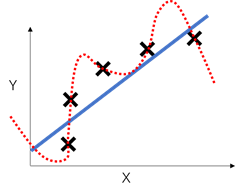
上面的讨论和最大熵有什么关系?最大熵原理的基本思想,就是除了与数据集分布相同这一基本假设之外,不添加任何额外假设,从而最小化过拟合的风险。换句话说,一个理论上完美利用最大熵原理的模型,可以在拟合训练数据集的同时拥有极佳的泛化性能。但显然,很多最大熵模型并没有实现这一点,问题在哪呢?
来回顾一下原始最大熵模型的定义:
[原始的最大熵模型]:设数据集为(X,Y),任务是找到X关于Y的一个估计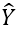
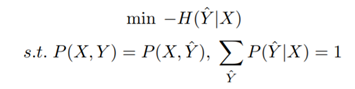
因为X,Y太多无法枚举,第一条约束条件是没法计算的。实际应用中,先驱们非常天才地引入了特征函数f(x,y)的概念:

从而可以用关于特征函数的期望相等代替原本的联合概率约束,从而最终得到问题的解:
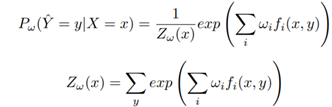
问题出在哪里?我们说特征函数是能应用最大熵原理的关键,但不恰当地应用也可能导致了对最大熵原理的破坏。问题就出现在特征函数f(x,y)的不恰当引入上。事实上,为求解方便引入的特征函数可能或多或少加入了对数据的假设,这时新问题和原始的最大熵问题就不一定等价了,因而泛化性能就无法得到保证了。只有当特征函数满足一定条件时,新问题才与最大熵等价。
所以,问题变成了:什么样的特征函数是恰当的--即满足什么条件的特征可以使推导得到的模型与原始最大熵问题等价?为此,论文提出了最大熵等价定理。
2. 最大熵等价原理
为便于围绕特征展开讨论,首先改变最大熵模型的形式,给出基于特征的最大熵模型;同时由于深度学习监督层一般是一个softmax回归模型,论文以softmax回归模型为实例,研究原始最大熵模型与softmax回归等价所需的特征约束条件。
[基于特征的最大熵模型]:设T是只与X相关的一组特征,可以用函数ti(x)表示特征T在样本x中存在的概率,即P(T=1|X=x)=ti(x),P(T=0|X=x)=1-ti(x),于是得到了基于特征的最大熵模型:
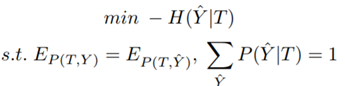
当然,这一问题还是无法直接求解。根据最大熵问题的解的形式,论文又定义了一个可以直接求解的softmax模型:
[基于特征的softmax模型]:设T满足上面的定义,那么在满足某种特殊的约束条件下的T,可以使问题的解的形式变为
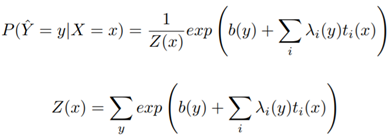
其中b和\lambda都是关于y的函数。可以看出,上面的解本质上是一个以特征T为输入的softmax回归(附加了偏置项)。
定义好以上两个模型后,论文证明了如下定理:
[最大熵等价定理]:对于数据集(X,Y),基于特征的softmax模型等价于原始最大熵模型的充分必要条件是:
1,在T的条件下,X和Y条件独立;
2,在Y的条件下,特征T中所有的特征条件独立。
具体的证明可以参见原文章。以上两个条件中,第一个条件保证了在T上定义的最大熵模型与原最大熵模型等价,因此称为等价条件(equivalent condition);第二个条件使在T上定义的最大熵模型可解---可以转换为基于特征 softmax回归,称为可解条件(solvable condition)。这一定理有什么意义呢?它为我们根据最大熵原理实现模型时提供了可操作的理论指导,并对于使用softmax回归类型的模型解决问题时,给出了特征学习/选择的指导和评价准则。
3. 基本DNN是对最大熵的递归逼近
啰啰嗦嗦这么多,都是在铺垫。给出了最大熵等价的特征条件后,终于可以尝试解决最初的问题:DNN是怎么实现对这两个特征条件的逼近,从而结合监督层的softmax实现最大熵的。等等,在这之前,还要插播介绍一个对于可分解问难问题的递归分解算法。
[可分解问题]:一个困难问题,如果可以等价为一个简单问题加上约束的形式,就是一个可分解问题。
[递归分解算法]
根据最大熵等价原理,显然最大熵就是一个可分解问题。假设我们现在有一个困难问题P,并且P可以等价于一个简单问题P1加上约束C1,记为P=P1+C1。但C1也不是直接满足的,可以把约束C1放松为优化问题p1。虽然放松了约束,P1+p1肯定还是比单纯的P1更接近原始的问题P。
于是,如果优化问题p1也可解,那么这一放松的问题可以采用类似EM的迭代算法求解:
1)固定p1中的参数,优化P1
2)固定P1中的参数,优化p1
3)不停地迭代以上两步直到收敛,
然而,可能p1也没有那么好求解,比如最大熵等价原理中的使满足两个特征条件的优化问题。论文证明发现最大熵等价原理中特征条件约束C1放松后的优化问题p1也是一个最大熵问题 (特征约束放松定理),因此也是可分解的。很自然的,继续执行以上的分解步骤,将p1分解为P2+p2。这样递归下去,直到分解的效果不明显了,即可以直接采用简单的算法P_L来近似p_L,从而得到了原始困难问题的一个递归分解:
P=P1+P2+…+P_L
这一递归分解问题也可以采用类似的迭代方法进行求解
1)固定P2,P3,…,P_L中的参数,优化P1;
2)固定P1,P3,…,P_L中的参数,优化P2;
…
L) 固定P1,P2,P3,…,P_(L-1)中的参数,优化P_L;
L+1) 不停地迭代以上L步直到收敛。
[DNN是最大熵问题的递归分解的结果]
小标题有点绕,但终于到正题了。定义了以上递归分解算法之后,我们就可以对最大熵问题进行递归分解。由于特征T是一个二元随机变量,只有存在与不存在两种取值,所以对每个特征Ti学习放松时的简单问题变成了逻辑回归。总结下,前方高能请注意:对于一个L层深度的递归分解解法,原始的最大熵问题可以通过\sum_{l=1}^{L}n_l个逻辑回归和一个sofmmax回归来逼近实现,这里的n_l是第l层递归深度的特征数目。聪明的你已经发现了这和一个基本DNN模型结构的惊人吻合:
递归的深度对应了DNN隐藏层的层数,只不过序号是反的,即第L层递归实际是由第1个隐藏层实现的;
每一层递归深度的特征数目对应了该层网络中的特征结点数目;
每次递归的简单问题的逻辑回归对应了一层中的显性回归+sigmoid激活函数;
递归分解的求解是由反向传播实现的。
至此,论文成功将深度学习建模为一种对原始最大熵模型的递归分解逼近:DNN通过多层特征学习+softmax回归近似无偏实现了最大熵,因此具有优秀的泛化性能。
4. 通过最大熵解释DNN的一些现象
如果你能坚持看到这里,恭喜你—上面三节其实已经回答了特征学习的三个基本问题:(why)为什么需要特征学习à满足特征约束、(what)需要什么样的特征约束à等价条件和可解条件、(how)如何实现这样的特征à递归分解, 即DNN。
在将DNN与最大熵联系在一起后,可以尝试从最大熵的角度解释与DNN有关的一些现象。首先就是最近火热的信息瓶颈理论。熟悉信息瓶颈理论的同学可能早就发现了,最大熵等价定理中的特征条件与信息瓶颈中的优化目标非常像。没错,论文也证明了最大熵的特征约束放松定理中的优化问题恰恰是信息瓶颈理论优化问题的充分条件,从而很好地解释DNN中为啥会出现中间层输出T与Y的互信息增大而与X的互信息减小这一现象。
进一步,DNN的很多结构设计被实验证明可以提高泛化性能,论文尝试从理论方面给予解释。首先就是DNN采取的多层非线性函数复合,这与传统的采用基函数显性组合(如小波、傅里叶)等完全不同,递归分解很好地解释了这一设计的原因。然后是shortcut的设计,一直是用方便训练时信息的流动来解释的。而从文中观点来看,CNN本质上就是一种采用X中的部分(感受野范围)作为输入的DNN,因此感受野越密集,损失的X中的信息越少,从而效果会越好。Shortcut改善泛化性能的秘诀就在于成功地提升了感受野的丰富程度。再比如常用的L2正则化、dropout、SGD等约束条件的引入,实质上就是对可解约束条件的近似。《On theemergence of invariance and disentangling in deep representations》论文中证明了,这些正则项带来I(X;T)的减少,进一步证明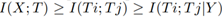
那是不是网络层数越高对最大熵拟合越好泛化性也就越好? 怎么解释ReLu激活函数?为什么冗余的特征在实验中证明效果更好?如何解释“rethinking generalization”论文中发现的深度学习模型对噪声的过拟合现象?这些问题有些在论文里已经尝试给出了回答,更多的问题欢迎大家到openreview上直接提问,在线解答和讨论。
附论文原文地址:
https://openreview.net/pdf?id=r1kj4ACp-
特注:
因篇幅限制,不能全部显示,完整版,请登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“ICLR” 主题,查看获得深度学习顶级会议ICLR的知识等资料!如下图所示~
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“ICLR” 就可以获取 ICLR2018匿名提交论文 的pd下载链接~~
更多专知荟萃知识资料全集获取,请查看:
【干货荟萃】机器学习&深度学习知识资料大全集(一)(论文/教程/代码/书籍/数据/课程等)
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
另外,请对分享或者自荐论文感兴趣的同学,扫码加入我们的论文交流群!

此外,请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



