【最新TensorFlow1.4.0教程02】利用Eager Execution 自定义操作和梯度 (可在 GPU 运行)
点击上方“专知”关注获取更多AI知识!
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问http://www.zhuanzhi.ai, 手机端访问http://www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。随着TensorFlow 1.4 Eager Execution的出现,TensorFlow的使用出现了革命性的变化。专知为大家推出TensorFlow 1.4系列教程:
02: 利用 Eager Execution 自定义操作和梯度 (可在 GPU 上运行)
待定
使用Eager Execution自定义操作及其梯度函数
在老版本的TensorFlow中,编写自定义操作及其梯度非常麻烦,而且像编写能在GPU上运行的操作和梯度需要用C++编写。TensorFlow 1.4中Eager Execution特性的引入,使得自定义操作和梯度变得非常简单。下面的例子是我用TensorFlow 1.4的Eager Execution特性编写的Softmax激活函数及其梯度,这个自定义的操作可以像老版本中的tf.nn.softmax操作一样使用,并且在梯度下降时可以使用自定义的梯度函数。
import tensorflow as tf
import tensorflow.contrib.eager as tfe
import numpy as np
# 开启Eager Execution
tfe.enable_eager_execution()
# 展示信息的间隔
verbose_interval = 500
# 加了注解之后,可以自定义梯度,如果不加注解,tf会自动计算梯度
# 加了注解之后,需要返回两个值,第一个值为loss,第二个值为梯度计算函数
# 本函数的参数中,step表示当前所在步骤,x表示Softmax层的输入,y是one-hot格式的label信息
@tfe.custom_gradient
def softmax_loss(step, x, y):
# 将x限定在-20和20之间,防止产生过大的值
x = tf.clip_by_value(x, -20, 20);
exp = tf.exp(x)
sum = tf.reduce_sum(exp, 1)
sum = tf.reshape(sum, [-1, 1])
# Softmax中的归一化
sm = tf.divide(exp, sum)
# 用Cross-Entropy计算Softmax的损失函数
loss = -tf.log(tf.clip_by_value(sm, 1e-10, 1.0)) * y
loss = tf.reduce_mean(loss)
if step % verbose_interval == 0:
# 计算准确率
predict = tf.argmax(sm, 1).numpy()
target = np.argmax(y, 1)
accuracy = (predict == target).sum() / len(target)
print("\nstep: {}".format(step))
print("accuracy = {}".format(accuracy))
# 定义梯度函数
def grad(_):
# Softmax在Cross-Entropy下梯度非常简单
# 即 object - target
d = sm - y
# 需要返回损失函数相对于softmax_loss每个参数的梯度
# 第一和第三个参数不需要训练,因此将梯度设置为None
return None, d, None
#返回损失函数和梯度函数
return loss, grad
下面,我们使用自定义的softmax层来实现一个用多层神经网络分类手写数字数据集的示例。
使用自定义的Softmax层分类MNIST数据集
MNIST数据集
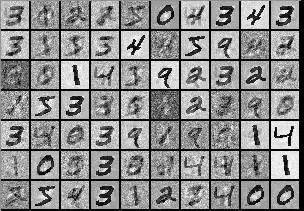
MNIST由手写数字图片组成,包含0-9十种数字,常被用作测试机器学习算法性能的基准数据集。MNIST包含了一个有60000张图片的训练集和一个有10000张图片的测试集。深度学习在MNIST上可以达到99.7%的准确率。TensorFlow中直接集成了MNIST数据集,无需自己单独下载。
神经网络结构
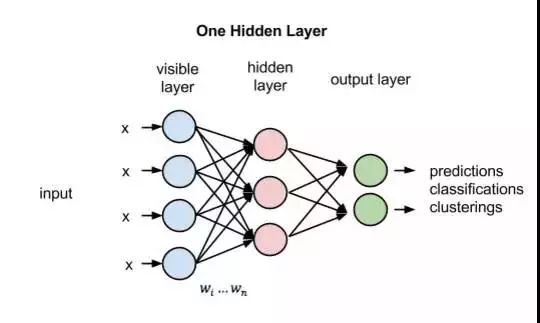
本教程使用具有1个隐藏层的MLP作为网络的结构,使用RELU作为隐藏层的激活函数,使用SOFTMAX作为输出层的激活函数。
从图中可以看出,网络具有输入层、隐藏层和输出层一共3层,但在代码编写时,会将该网络看作由2个层组成(2次变换):
Layer 0: 一个Dense Layer(全连接层),由输入层进行线性变换变为隐藏层,并使用RELU对变换结果进行激活。用公式表达形式为H= relu(XW_0 + b_0),其中:
X: 输入层,是形状为[batch_size, input_dim]的矩阵,矩阵的每行对应一个样本,每列对应一个特征(一个像素)
H: 隐藏层的输出,是形状为[batch_size, hidden_dim]的矩阵,矩阵的每行对应一个样本隐藏层的输出
relu: 使用RELU激活函数进行激活
W_0: 形状为[input_dim, hidden_dim]的矩阵,是全连接层线性变换的参数
b_0: 形状为[hidden_dim]的矩阵,是全连接层线性变换的参数(偏置)
Layer 1: 一个Dense Layer(全连接层),由隐藏层进行线性变换为输出层,并使用SOFTMAX对变换结果进行激活。用公式表达形式为:OUTPUT = softmax(HW_1 + b_1),其中:
OUTPUT: 输出层,是形状为[batch_size, output_dim]的矩阵,矩阵的每行对应一个样本,每列对应样本属于某类的概率。例如该例子中第0列表示输入手写数字为1的概率。
softmax: 使用SOFTMAX激活函数进行激活
W_1: 形状为[hidden_dim, output_dim]的矩阵,是全连接层线性变换的参数
b_1: 形状为[output_dim]的矩阵,是全连接层线性变换的参数(偏置)
神经网络的训练过程,即神经网络参数的调整过程。待参数能够很好地预测测试集中样本的类别(label),神经网络就训练成功了。
Eager Execution实现的多层神经网络代码
#coding=utf-8
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import tensorflow.contrib.eager as tfe
import numpy as np
# 开启Eager Execution
tfe.enable_eager_execution()
# 使用TensorFlow自带的MNIST数据集,第一次会自动下载,会花费一定时间
mnist = input_data.read_data_sets("/data/mnist", one_hot=True)
# 展示信息的间隔
verbose_interval = 500
# 加了注解之后,可以自定义梯度,如果不加注解,tf会自动计算梯度
# 加了注解之后,需要返回两个值,第一个值为loss,第二个值为梯度计算函数
# 本函数的参数中,step表示当前所在步骤,x表示Softmax层的输入,y是one-hot格式的label信息
@tfe.custom_gradient
def softmax_loss(step, x, y):
# 将x限定在-20和20之间,防止产生过大的值
x = tf.clip_by_value(x, -20, 20);
exp = tf.exp(x)
sum = tf.reduce_sum(exp, 1)
sum = tf.reshape(sum, [-1, 1])
# Softmax中的归一化
sm = tf.divide(exp, sum)
# 用Cross-Entropy计算Softmax的损失函数
loss = -tf.log(tf.clip_by_value(sm, 1e-10, 1.0)) * y
loss = tf.reduce_mean(loss)
if step % verbose_interval == 0:
# 计算准确率
predict = tf.argmax(sm, 1).numpy()
target = np.argmax(y, 1)
accuracy = (predict == target).sum() / len(target)
print("\nstep: {}".format(step))
print("accuracy = {}".format(accuracy))
# 定义梯度函数
def grad(_):
# Softmax在Cross-Entropy下梯度非常简单
# 即 object - target
d = sm - y
# 需要返回损失函数相对于softmax_loss每个参数的梯度
# 第一和第三个参数不需要训练,因此将梯度设置为None
return None, d, None
#返回损失函数和梯度函数
return loss, grad
with tf.device("/gpu:0"):
# 第一层网络的参数,输入为28*28=784维,隐藏层150维
W0 = tf.get_variable("W0", shape=[784, 150])
b0 = tf.get_variable("b0", shape=[150])
# 第二层网络的参数,一共有10类数字,因此输出为10维
W1 = tf.get_variable("W1", shape=[150, 10])
b1 = tf.get_variable("b1", shape=[10])
# 构建多层神经网络
def mlp(step, x, y, is_train = True):
hidden = tf.matmul(x, W0) + b0
hidden = tf.nn.relu(hidden)
# 如果在训练,使用dropout层防止过拟合
# Eager Execution使得我们可以利用Python的if语句动态调整网络结构
if is_train:
hidden = tf.nn.dropout(hidden, keep_prob = 0.75)
logits = tf.matmul(hidden, W1) + b1
# 调用我们自定义的Softmax层
loss = softmax_loss(step, logits, y)
if step % verbose_interval == 0:
print("loss = {}".format(loss.numpy()))
return loss
optimizer = tf.train.AdamOptimizer(learning_rate = 1e-3)
# 执行3000步
for step in range(3000):
# 生成128个数据,batch_data是图像像素数据,batch_label是图像label信息
batch_data, batch_label = mnist.train.next_batch(128)
# 梯度下降优化网络参数
optimizer.minimize(lambda: mlp(step, batch_data, batch_label))
运行结果:
step: 0
accuracy = 0.078125
loss = 0.25111961364746094
step: 500
accuracy = 0.9296875
loss = 0.023569952696561813
step: 1000
accuracy = 0.9453125
loss = 0.01356084831058979
step: 1500
accuracy = 0.96875
loss = 0.008165322244167328
step: 2000
accuracy = 0.953125
loss = 0.009977160021662712
step: 2500
accuracy = 0.984375
loss = 0.0029998861718922853
随着训练的进行,多层神经网络的准确率越来越高,损失越来越小。不过这两个指标并不能真正反映分类器的质量,因为我们是在训练数据集上测试的,严格来说,应该在测试数据集上进行测试。由于篇幅有限,这里就不介绍如何在训练集上进行测试了。
特注:
获取TensorFlow1.4.0代码最新更新,请登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“ TensorFlow” 主题,查看获得TensorFlow最新更新代码与知识等资料!如下图所示~

请加入TensorFlow学习群交流~

请扫描小助手,加入专知人工智能群,交流分享~

此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),获取更多专知荟萃知识资料全集获取,请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【干货荟萃】机器学习&深度学习知识资料大全集(一)(论文/教程/代码/书籍/数据/课程等)
【GAN货】生成对抗网络知识资料全集(论文/代码/教程/视频/文章等)
【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请扫描小助手,加入专知人工智能群,交流分享~
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



