【CVPR2018】如何增强Attention Model的推理能力
【导读】目前Attention Model已经被用到了机器视觉,自然语言理解,语音识别,机器翻译等等各行各业。各种各样的Attention Model也被各种Task使用。如何增强Attention Model的推理能力、在使用Attention Model的时候提升模型性能,成为了一个关键的问题。在本文中,我们介绍一种在CVPR 2018大会提出的方法,可以通过极为简单的改进有效的提升Attention Model的性能。
论文题目:Stacked Latent Attention for Multimodal Reasoning

什么是Attention Model
首先我们用下图的例子简单的重温Attention Model:
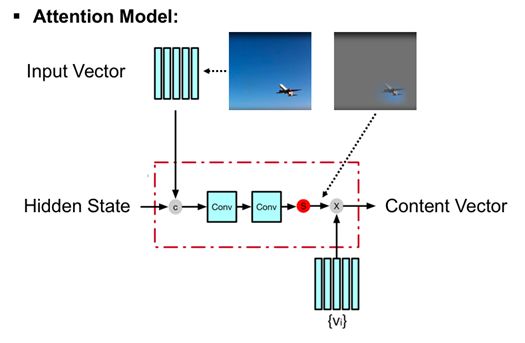
给定Hidden State,Attention Model可以学到对输入(图示中为图像)Tensor最相关的Mask,并使用Mask对输入Tensor进行加权和,并将加权和后得到的Content Vector作为Attention Model的输出。换而言之,Attention Model可以学到给定输入中最重要的部分,从而对输入进行“总结”。
增强Attention Model的性能的方法——Stacked Attention Model
接下来我们介绍一种非常常用的增强Attention Model的性能的方法:Stacked Attention Model。顾名思义,就是简单的拼接(Stack)多个Attention Model,将前一个AttentionModel的输出作为下一个Attention Model的输入。具体实现如下图所示:
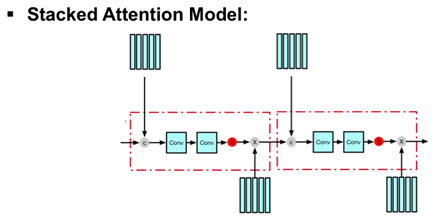
在今年刚刚召开的CVPR大会中,研究者对这种常用的增强Attention Model的方法进行了探索,提出了上图中方法的缺陷,并通过极为简单的改进有效地增强了Attention Model的推理性能:
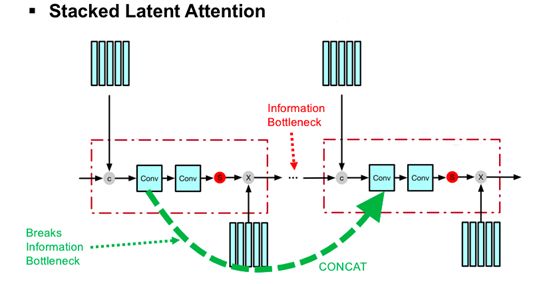
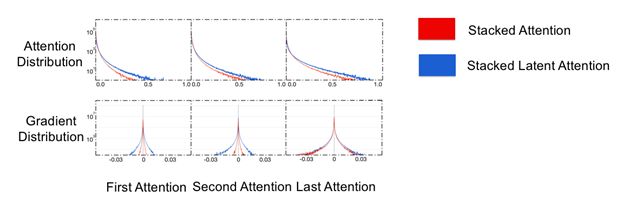
研究者发现,在Attention Model“总结”输入Tensor的同时,造成了信息瓶颈(Information Bottleneck),该信息瓶颈会导致模型性能下降。同时因Attention Model的SoftMax集中在Pathway上而造成了梯度弥散,进而导致在使用多层Attention Model时模型难以优化(Optimize)。
研究者提出,通过简单将多层Attention Model的隐变量(Latent State)连接(Concat)起来(上图绿色虚线),就可以解决信息瓶颈和梯度弥散问题。如上图所示,在没有绿色虚线的情况下,模型仅仅将多层Attention Model叠加起来,此方法不但1)在每两个Attention Model之间造成了信息瓶颈,同时2)因主要Pathway中有多个SoftMax,而造成梯度弥散。
文章提出,仅仅通过增加上图中的绿色虚线,将前一层Attention Model中的隐变量(LatentState) 连接(Concat)到下一个Attention Model中,就可以1)打破信息瓶颈,同时2)通过提供了新的Pathway避开原Pathway中的多个SoftMax,从而缓解梯度弥散,进而3)提升模型性能。

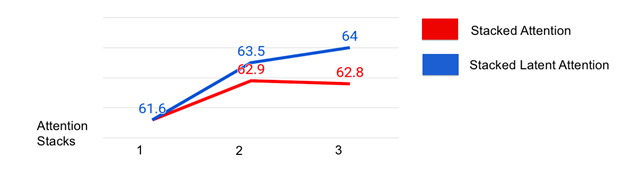
实验表明,当将多层Attention Models的隐变量连接起来,随着简单增加所连接的Attention Model的数量,整体模型性能得到了显著的提升。同时梯度弥散问题得到了明显的缓解:
该文章的更多细节可以参考:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Fan_Stacked_Latent_Attention_CVPR_2018_paper.pdf
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



