【论文读书笔记】无监督视频物体分割新思路:实例嵌入迁移
【导读】 近日,针对视频物体分割中缺乏训练样本和准确率较低的问题,来自美国南加州大学、谷歌公司的学者发表论文提出基于实例嵌入迁移的无监督视频物体分割方法。其通过迁移封装在基于图像的实例嵌入网络(instance embedding network)中的知识来实现。 实例嵌入网络为每个像素生成一个嵌入向量,可以识别属于同一个物体的所有像素。本文将在静态图像上训练的实例网络迁移到视频对象分割上,将嵌入向量与物体和光流特征结合,而无需模型再训练或在线微调。 所提出的方法优于DAVIS数据集和FBMS数据集中最先进的无监督分割方法。
论文:Instance Embedding Transfer to Unsupervised Video Object Segmentation

我们提出一种无监督的视频物体分割方法,其通过迁移封装在基于图像的实例嵌入网络(instance embedding network)中的知识来实现。 实例嵌入网络为每个像素生成一个嵌入向量,可以识别属于同一个物体的所有像素。 尽管是在静态图像上训练的,但实例嵌入在连续的视频帧上也是稳定的,这使得我们能够按照时间序列将物体链接在一起。 因此,我们将在静态图像上训练的实例网络迁移到视频对象分割上,将嵌入向量与物体和光流特征结合,而无需模型再训练或在线微调。 所提出的方法优于DAVIS数据集和FBMS数据集中最先进的无监督分割方法。
▌介绍
视频理解中的一个重要任务是在时间和空间上定位物体。 理想情况下,它应该能够随着时间的推移使用一个物体mask(sharp object mask),来定位已有的或新的物体,这种情况被称为视频物体分割(VOS)。 如果没有给出要分割哪个物体的指示,则该任务被称为无监督视频物体分割或主要物体分割(primary object segmentation)。 一旦物体被分割,则后续的视觉效果工具和视频理解工具就可以利用这些信息。
目前,静态图像中的物体分割任务主要是基于全卷积神经网络(FCN)的方法。 这些神经网络需要在大数据集上进行物体分割任务,如PASCAL和COCO。 视频分割数据集一般较小,因为其标注非常昂贵。 因此,训练神经网络来解决视频分割更困难。 经典的视频分割工作使用光流法和基于浅层表观模型来生成分割结果,而最新的方法通常在图像分割数据集上预先训练网络,然后将网络应用到视频领域,有时也会结合光流。

图1:根据运动来改变视频中分割目标(前景)的示例。 在第一行,汽车是视频中的前景,在第二行,汽车则是视频中的背景。 为了解决这个问题,提出的方法首先获得物体实例的嵌入,并识别用于区分前景/背景的代表性嵌入,然后基于代表性嵌入来分割帧。 左: groundtruth。 中:通过PCA投影到RGB空间的嵌入的可视化,以及用于前景(洋红色)和背景(蓝色)的代表性点。 右:由所提出的方法产生的分割mask。
在本文中,作者提出了一种知识转换方法,通过迁移从静态图像中学习到的实例分割嵌入中的知识,并将其与物体和光流相结合来分割视频中的运动物体。 本文没有像其他方法那样直接将每个像素分类为前景/背景来训练FCN。而是在训练FCN的时候,从图像中同时学习物体实例的嵌入和语义类别。利用学习的嵌入之间的距离来编码像素之间的相似度。 作者认为,相比于前景/背景预测,从图像到视频迁移的实例嵌入是一个更有用的特征。 如图1所示,汽车出现在两个视频中,但是属于不同的类别(第一个视频是前景和第二个视频是背景)。 如果网络训练的时候,直接将汽车分类为第一个视频的前景,则它在第二个视频中也倾向于将汽车也分类为前景。因此,网络需要对每个序列进行微调。 相反,实例嵌入网络可以在两个视频序列中分别为汽车产生独特的嵌入,而不会干扰其他预测或需要额外微调。 然后该任务就变成了如何选择正确的嵌入以用作表观建模。本文依靠嵌入来编码物体实例信息,提出了一种基于物体分数和光流识别前景(目标物体)和背景的可表示性嵌入方法。可表示性嵌入的例子在图1的中间列中。最后,通过在一组代表性的前景或背景嵌入中找到最近邻来对所有像素进行分类。 这是一个非参数化的过程,在训练或测试时不需要监督信息。
在DAVIS数据集和FBMS数据集上对提出的方法进行评估。 即使不对目标数据集上的嵌入网络进行微调,提出的方法性能比以前最先进的方法还要好。 具体地,本文分别在DAVIS数据集和FBMS数据集上得到了78.5%和71.9%的平均交叉联合(intersectionover-union, IoU)。
主要贡献如下:
提出一种将静态图像训练的实例分割模型适应到视频的新策略。 值得注意的是,这种策略在视频数据集上表现良好,无需任何视频物体分割标注。
这种策略在DAVIS benchmark和FBMS benchmark测试中胜过以前的无监督方法,并且在测试时不需要重新训练任何网络的情况下,能接近半监督CNN的性能。
基于轨迹上的语义分数和运动特征,提出了在没有监督的情况下选择前景物体的新标准。
深入分析实例分割嵌入在时序上的稳定性。
▌模型简介
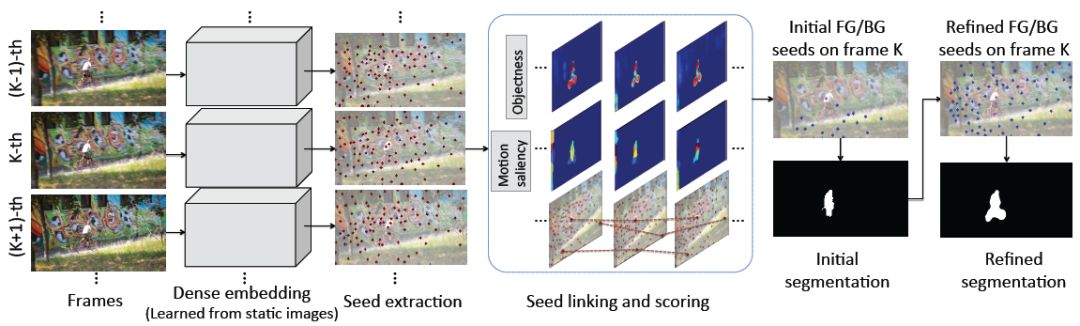
这是所提出的方法概览图。 给定视频序列,通过在静态图像上训练的实例分割网络来获得密集嵌入。 然后获得代表性的嵌入,称为种子。 种子在整个序列中连接起来(我们在这里显示连续3帧)。 选择基于物体和运动显着性得分最高的种子作为初始种子(品红色)以产生初始分割。 最后,识别更多的前景种子以及背景种子来改善分割。
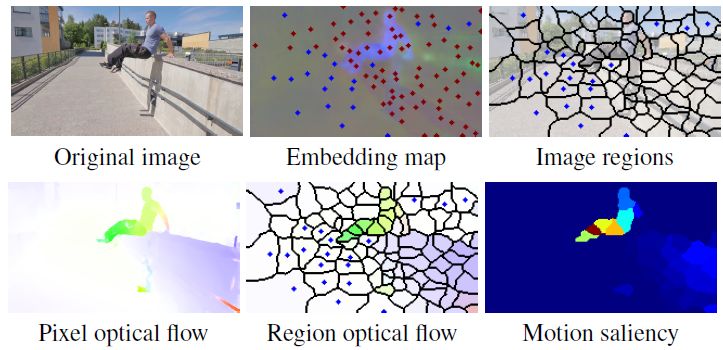
图中:第一行:左边是一幅图像。 中间:将嵌入图投影到RBG空间(通过PCA),其中初始背景种子SBG标记为蓝色,其他种子为红色。 右:嵌入图中每个种子附近的区域。 第二行:左边是光流。 中间:每个区域内的平均流量。 右:运动显著性分数图。
▌实验结果

表1:在DAVIS 2016数据集的评价结果。 提出的方法在两个评估指标上都达到了最高水平,并且胜过了在DAVIS上进行微调的方法。每个视频的结果放在文末的补充材料中。

图5:在DAVIS数据集的定性结果示例。 提出的方法对于外观变化大的视频(第一行),混淆的背景(第二行,有人在背景中),视角变化(第三行,不同的视角)和看不见的语义类别(第四行,以山羊为前景)具有较好的效果。

表2:在FBMS数据集测试集上的结果。 提出的方法在评估指标上达到了最高水平。
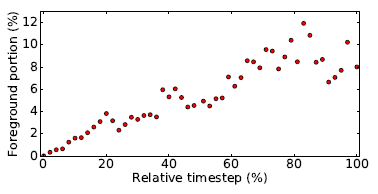
图6:错误分类的前景嵌入与相对时间步的比例。 随着时间的推移,更多的前景嵌入比前景本身更接近第一帧的背景。
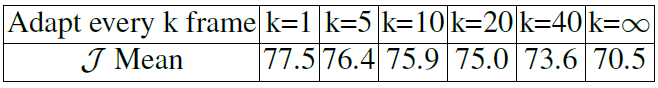
表3:分段性能与在线自适应频率。 在DAVIS训练集上进行的实验。 请注意,k = 1表示没有在线自适应。
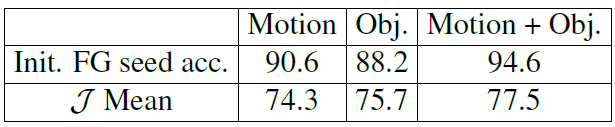
表4:分割性能与前景排名策略。 在DAVIS训练集上进行实验。

表5:采用该方法对DAVIS 评价数据集上进行半监督的视频物体分割结果。
▌结论
本文提出了一种将静态图像学习的实例嵌入转换到视频的无监督物体分割的方法。 为了适应视频物体分割问题的前景变化,本文训练网络来生成嵌入(该嵌入封装了实例信息),而不是训练直接输出前景/背景分数的网络。 在实例嵌入中,通过物体和运动显著性进行建模来识别代表性的前景/背景嵌入。 然后,根据前景/背景的嵌入相似性对像素进行分类。 与许多需要对目标数据集进行微调的方法不同,提出的方法在无监督的视频物体分割实现了最好的性能,并且没有任何微调,节省了大量的标注工作。
参考链接:
https://arxiv.org/abs/1801.00908
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



