【论文推荐】最新5篇语音识别(ASR)相关论文—音频对抗样本、对抗性语音识别系统、声学模型、序列到序列、口语可理解性矫正
【导读】专知内容组整理了最近五篇语音识别(Automatic Speech Recognition, ASR)相关文章,为大家进行介绍,欢迎查看!
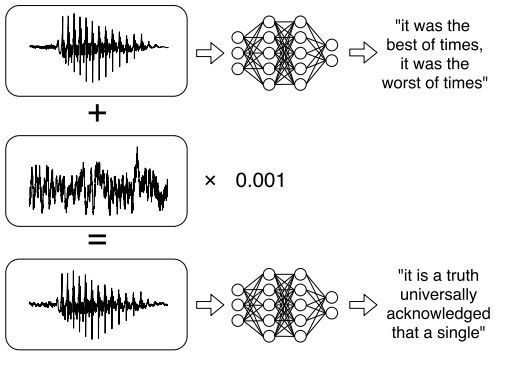
1. Audio Adversarial Examples: Targeted Attacks on Speech-to-Text(音频对抗样本:针对语音到文本的攻击)
作者:Nicholas Carlini,David Wagner
摘要:We construct targeted audio adversarial examples on automatic speech recognition. Given any audio waveform, we can produce another that is over 99.9% similar, but transcribes as any phrase we choose (at a rate of up to 50 characters per second). We apply our iterative optimization-based attack to Mozilla's implementation DeepSpeech end-to-end, and show it has a 100% success rate. The feasibility of this attack introduce a new domain to study adversarial examples.
期刊:arXiv, 2018年1月6日
网址:
http://www.zhuanzhi.ai/document/02b6a97d515f1ba5e9045bc90643ea6f
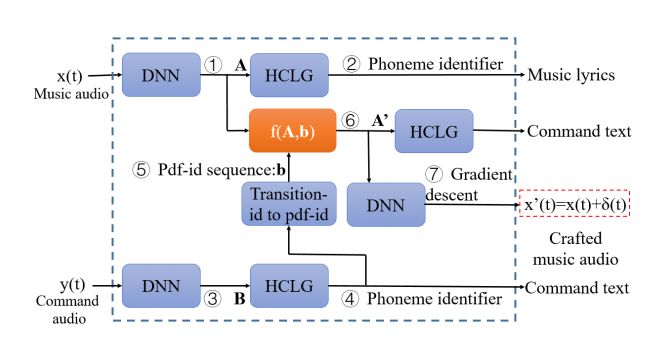
2. CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition(CommanderSong: 一种实用的对抗性语音识别系统)
作者:Xuejing Yuan,Yuxuan Chen,Yue Zhao,Yunhui Long,Xiaokang Liu,Kai Chen,Shengzhi Zhang,Heqing Huang,Xiaofeng Wang,Carl A. Gunter
摘要:ASR (automatic speech recognition) systems like Siri, Alexa, Google Voice or Cortana has become quite popular recently. One of the key techniques enabling the practical use of such systems in people's daily life is deep learning. Though deep learning in computer vision is known to be vulnerable to adversarial perturbations, little is known whether such perturbations are still valid on the practical speech recognition. In this paper, we not only demonstrate such attacks can happen in reality, but also show that the attacks can be systematically conducted. To minimize users' attention, we choose to embed the voice commands into a song, called CommandSong. In this way, the song carrying the command can spread through radio, TV or even any media player installed in the portable devices like smartphones, potentially impacting millions of users in long distance. In particular, we overcome two major challenges: minimizing the revision of a song in the process of embedding commands, and letting the CommandSong spread through the air without losing the voice "command". Our evaluation demonstrates that we can craft random songs to "carry" any commands and the modify is extremely difficult to be noticed. Specially, the physical attack that we play the CommandSongs over the air and record them can success with 94 percentage.
期刊:arXiv, 2018年1月25日
网址:
http://www.zhuanzhi.ai/document/ec3cf2da6bad04326cbc0f4dfd7314f0
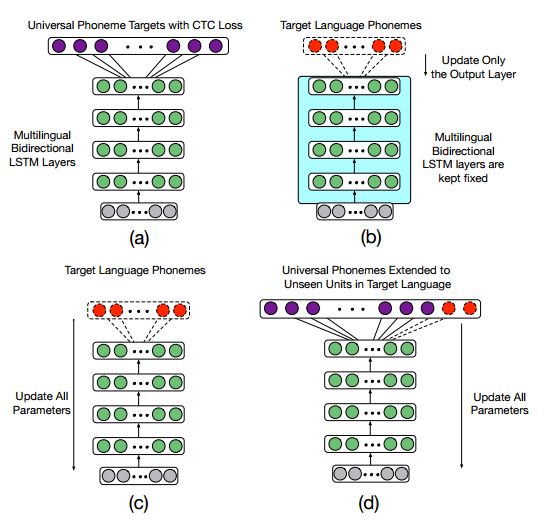
3. Multilingual Training and Cross-lingual Adaptation on CTC-based Acoustic Model(基于CTC的声学模型的多语种训练和跨语言适应方法)
作者:Sibo Tong,Philip N. Garner,Hervé Bourlard
摘要:Multilingual models for Automatic Speech Recognition (ASR) are attractive as they have been shown to benefit from more training data, and better lend themselves to adaptation to under-resourced languages. However, initialisation from monolingual context-dependent models leads to an explosion of context-dependent states. Connectionist Temporal Classification (CTC) is a potential solution to this as it performs well with monophone labels. We investigate multilingual CTC in the context of adaptation and regularisation techniques that have been shown to be beneficial in more conventional contexts. The multilingual model is trained to model a universal International Phonetic Alphabet (IPA)-based phone set using the CTC loss function. Learning Hidden Unit Contribution (LHUC) is investigated to perform language adaptive training. In addition, dropout during cross-lingual adaptation is also studied and tested in order to mitigate the overfitting problem. Experiments show that the performance of the universal phoneme-based CTC system can be improved by applying LHUC and it is extensible to new phonemes during cross-lingual adaptation. Updating all the parameters shows consistent improvement on limited data. Applying dropout during adaptation can further improve the system and achieve competitive performance with Deep Neural Network / Hidden Markov Model (DNN/HMM) systems on limited data.
期刊:arXiv, 2018年1月23日
网址:
http://www.zhuanzhi.ai/document/c40ff80e8ec1b8044c32cad289037b8b
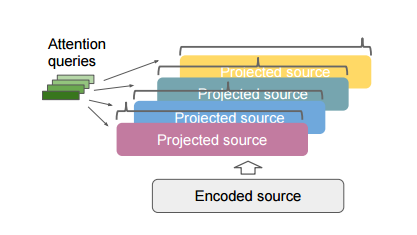
4. State-of-the-art Speech Recognition With Sequence-to-Sequence Models(采用序列到序列模型的前沿语音识别方法)
作者:Chung-Cheng Chiu,Tara N. Sainath,Yonghui Wu,Rohit Prabhavalkar,Patrick Nguyen,Zhifeng Chen,Anjuli Kannan,Ron J. Weiss,Kanishka Rao,Ekaterina Gonina,Navdeep Jaitly,Bo Li,Jan Chorowski,Michiel Bacchiani
摘要:Attention-based encoder-decoder architectures such as Listen, Attend, and Spell (LAS), subsume the acoustic, pronunciation and language model components of a traditional automatic speech recognition (ASR) system into a single neural network. In our previous work, we have shown that such architectures are comparable to state-of-the-art ASR systems on dictation tasks, but it was not clear if such architectures would be practical for more challenging tasks such as voice search. In this work, we explore a variety of structural and optimization improvements to our LAS model which significantly improve performance. On the structural side, we show that word piece models can be used instead of graphemes. We introduce a multi-head attention architecture, which offers improvements over the commonly-used single-head attention. On the optimization side, we explore techniques such as synchronous training, scheduled sampling, label smoothing, and minimum word error rate optimization, which are all shown to improve accuracy. We present results with a unidirectional LSTM encoder for streaming recognition. On a 12,500 hour voice search task, we find that the proposed changes improve the WER of the LAS system from 9.2% to 5.6%, while the best conventional system achieve 6.7% WER. We also test both models on a dictation dataset, and our model provide 4.1% WER while the conventional system provides 5% WER.
期刊:arXiv, 2018年1月19日
网址:
http://www.zhuanzhi.ai/document/9942c891541525c55c47a8f9d557c1ee
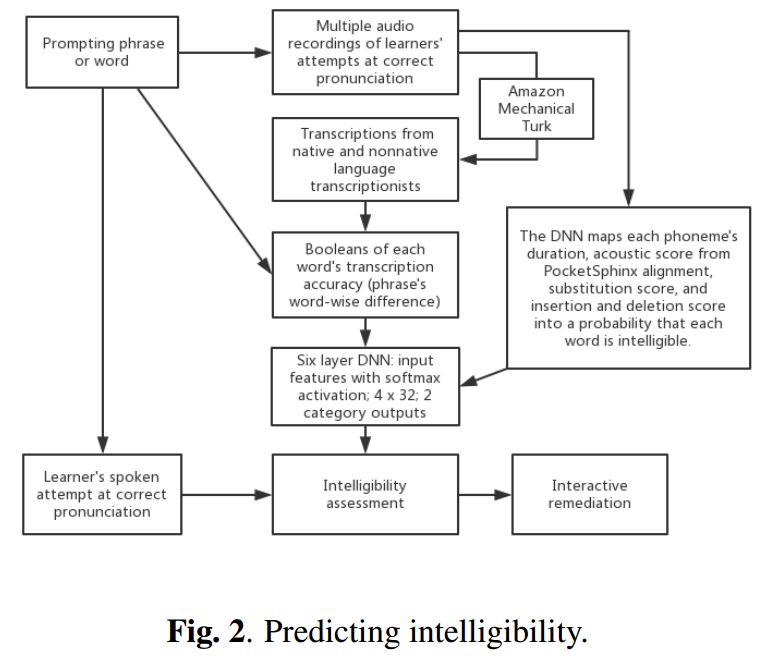
5. Spoken English Intelligibility Remediation with PocketSphinx Alignment and Feature Extraction Improves Substantially over the State of the Art(口语可理解性矫正)
作者:Yuan Gao,Brij Mohan Lal Srivastava,James Salsman
摘要:We use automatic speech recognition to assess spoken English learner pronunciation based on the authentic intelligibility of the learners' spoken responses determined from support vector machine (SVM) classifier or deep learning neural network model predictions of transcription correctness. Using numeric features produced by PocketSphinx alignment mode and many recognition passes searching for the substitution and deletion of each expected phoneme and insertion of unexpected phonemes in sequence, the SVM models achieve 82 percent agreement with the accuracy of Amazon Mechanical Turk crowdworker transcriptions, up from 75 percent reported by multiple independent researchers. Using such features with SVM classifier probability prediction models can help computer-aided pronunciation teaching (CAPT) systems provide intelligibility remediation.
期刊:arXiv, 2018年1月26日
网址:
http://www.zhuanzhi.ai/document/65cfc71d13f1f5d4a5e3ad37898fa916
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



