【论文笔记】ICLR 2018 Wasserstein自编码器
动机
表示学习领域最初是由监督方法驱动的,大规模标记数据集为这种方法带来了令人印象深刻的结果。相比之下,无监督生成模型,致力于使用概率的方法对低维数据建模。近年来,这两种方法已经趋于一致,在交叉处形成的新领域。变分自动编码器(Variational Auto-Encoder,VAEs)是其中一种成熟的方法,能处理大规模数据,并且在理论上优雅,但缺点是生成的图像模糊。生成对抗网络(Generative Adversarial Network,GAN)能生成较高质量的图片,但是没有编码器,难以训练,并且遭受“模式崩溃“问题(无法建模刻画真实数据的多样性)之苦。为了解决这些问题,Google Brain的研究员提出了Wasserstein Auto Encoder模型。
从VAE开始
标准的自编码器的结构如下图所示,原始数据经过编码器,编码成隐向量,然后隐向量通过解码器,解码出原始图片,将这些隐向量存起来,之后就可以通过解码器重构图像:
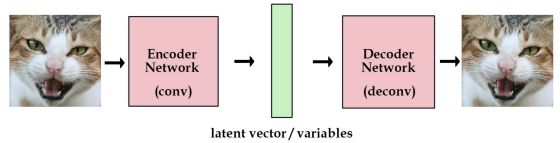
但是,我们想建一个产生式网络,而不是一个存储图片的网络。像上面的网络一样,合理的潜在变量都是编码器从原始图片中产生的,因此我们还不能产生任何未知的东西。
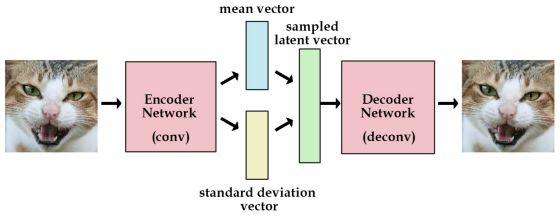
VAE在标准自编码器的基础上加了一个约束,即强迫编码器生成服从单位高斯分布的潜在变量。那么产生新的图片时,只要从单位高斯分布中采样,然后传给解码器就行了。
因此,在训练VAE的时候,需要考虑两个部分
1. 潜在变量的分布于编码器引入的分布Q的差异,这部分由KL散度进行衡量。
2. 重构图片的误差。
而为了体现生成的潜在变量约束与某种分布,使用一种重参数化的技术,即编码器的输出变为该分布的均值和方差,潜在变量从该分布中采样之后,再输入到解码器。
模型结构
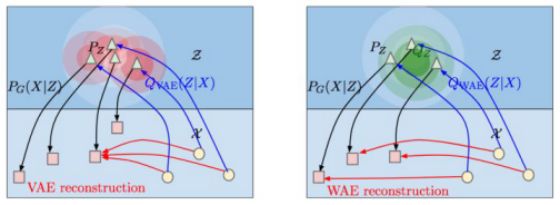
从上图中可以看出,WAE和VAE其实是很相似的!目标均为最小化两项
1.重构损失函数
2.先验分布与编码器Q引入的分布的差异。
在VAE中,对于所有从 中取样的不同输入样本x,都迫使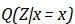
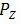
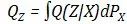
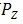
下面详细讨论WAE的两个优化目标。
1.重构损失,为了衡量两个概率分布(原始数据的分布,生成数据的分布)之间的距离,常用的两类方法是f-散度和optimal transport f散度的公式为:
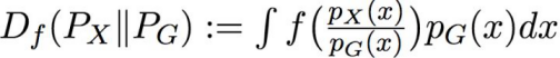
其中,f是满足f(1) = 0的凸函数。f-散度常见的例子有KL散度(Kullback-Leibler divergence)和JS散度(Jenson-Shannon divergence)。
OT的定义为:
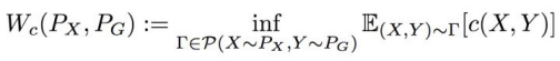
其中,c(x, y)为损失函数。当p ≥ 1时,若c(x, y) = dp(x, y),则称为Wasserstein距离。
2.正则子
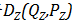
论文中提出了两种正则子:
基于GAN的正则子,即,
然后使用对抗训练加以逼近。
基于MMD(Maximun mean discrepancy)的正则子,即
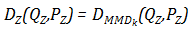
其中,

MMD在符合高维分布数据上表现出色,比基于GAN逼近要节省算力。
因此最终,WAE的计算目标为:
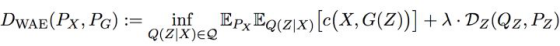
实验结果
研究人员在MNIST数据集和CelebA 数据集上试验了WAE,可以看出WAE重建的画质高于VAE。


论文链接:https://arxiv.org/abs/1711.01558

-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



