【干货】理解特征工程Part 2——类别数据(附代码)
【导读】不管是机器学习、深度学习或统计方法,任何的智能系统都需要数据支持。而原始数据往往很难被算法直接利用,因此特征工程显得尤为重要。这是一篇完全手把手教你在实际应用中如何理解特征工程的教程,在上一篇,作者研究了关于连续数值数据的特征工程的流行策略,通过实例和代码详细展示了连续数值数据特征工程的过程。
在本文中,我们将看到另一种类型的结构化数据,它本质上是离散的,通常被称为类别数据。本文介绍了一些在离散类别数据上进行特征工程的主流策略,并且谈到了使用特征工程处理大型特征空间的一些方法。
作者 | Dipanjan (DJ) Sarkar
编译 | 专知
翻译 | Chaofan, Xiaowen

Understanding Feature Engineering (Part 2) —Categorical Data
简介
在本系列的前一篇文章中,我们介绍了用于处理结构化连续数值数据的各种特征工程策略。在本文中,我们将看看另一种类型的结构化数据,它本质上是离散的,通常被称为类别数据。处理数值数据通常比类别数据更容易,因为我们无需处理属于任何类别类型的任何数据属性中与每个类别值有关的附加语义复杂性。我们将来讨论处理类别数据的几种编码方案,以及一些用于处理大规模特征爆炸(通常称为“维度诅咒”)的流行技术。
动机
我确信,现在你必须认识到特征工程的动机和重要性,我们在本系列的'第一部分'中也对此做了相同的详细说明。简而言之,机器学习算法不能直接处理类别数据,在开始对数据建模之前,你需要对此数据进行一定量转换。
了解分类数据
在深入研究特征工程策略之前,先了解分类数据表示。典型地,任何本质上属于类别的数据属性表示属于特定有限类别(categories)或类(class)的离散值。在模型预测的属性或变量的上下文中,这些通常也被称为类或标签(通常称为响应变量)。这些离散值本质上可以是文本或数字(甚至可以是非结构化数据,如图像!)。有两类主要类别的数据,Nominal(定类变量)定类和Ordinal(定序变量)定序。
在任何定类定类分类数据属性中,该属性的值之间没有排序的概念。考虑一个天气类别的简单例子,如下图所示。我们可以看到,在这个特定的场景中,我们有六个主要的类别,没有任何概念或顺序(刮风并不总是在晴天之前发生,也不是小于或大于晴天)。

同样,电影,音乐和视频游戏类型,国名,食物和美食类也是定类定类数据的。
定序定序类别属性在其价值中有一定的顺序意义或概念。 例如请看下图的衬衫大小。 很明显,在考虑衬衫时(S小于M,小于L等等),在这种情况下,考虑衬衫的顺序或尺寸很重要。
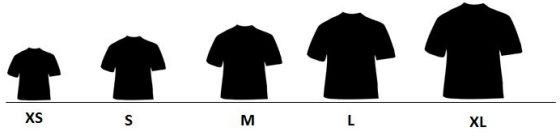
定序定序类别属性还包括鞋子的大小,教育水平和就业角色等。理解了类别数据之后,让我们看看特征工程的一些策略。
类别数据的特征工程虽然在各种机器学习框架中已经取得了很多进展,如可以接受像文本标签这样复杂的类别数据类型。 通常,特征工程中的任何标准工作流程都涉及将这些分类值转换为数字标签的某种形式,然后对这些值应用一些编码方案。 我们在开始之前加载必要的模块:
import pandas as pd
import numpy as np
变换定类属性
定类定类属性由离散的分类值组成,它没有概念或顺序的意思。 这里的想法是将这些属性转换为更具代表性的数字格式。 我们来看看与视频游戏销售有关的新数据集。
vg_df = pd.read_csv('datasets/vgsales.csv', encoding='utf-8')
vg_df[['Name', 'Platform', 'Year', 'Genre', 'Publisher']].iloc[1:7]
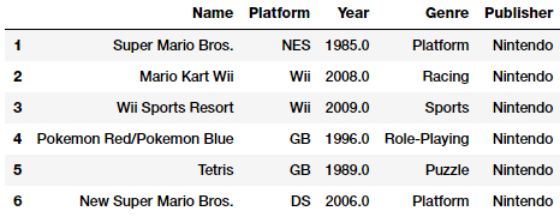
让我们专注于上述数据中描述的视频游戏Genre属性。 很明显,这是一个像Publisher和Platform一样的定类上的分类属性。 我们可以很容易地得到独特的视频游戏类型列表如下。
genres = np.unique(vg_df['Genre'])
genres
Output
------
array(['Action', 'Adventure', 'Fighting', 'Misc', 'Platform',
'Puzzle', 'Racing', 'Role-Playing', 'Shooter', 'Simulation',
'Sports', 'Strategy'], dtype=object)
这告诉我们有12个不同的视频游戏类型。 我们现在可以生成一个标签编码方案,通过利用scikit-learn将每个类别映射到一个数值。
from sklearn.preprocessing import LabelEncoder
gle = LabelEncoder()
genre_labels = gle.fit_transform(vg_df['Genre'])
genre_mappings = {index: label for index, label in
enumerate(gle.classes_)}
genre_mappings
Output
------
{0: 'Action', 1: 'Adventure', 2: 'Fighting', 3: 'Misc',
4: 'Platform', 5: 'Puzzle', 6: 'Racing', 7: 'Role-Playing',
8: 'Shooter', 9: 'Simulation', 10: 'Sports', 11: 'Strategy'}
因此,在LabelEncoder对象gle的帮助下,每个类型值被映射到一个数字,从而生成了一个映射方案。 转换后的标签存储在我们可以写回data frame的
genre_labels值中。
vg_df['GenreLabel'] = genre_labels
vg_df[['Name', 'Platform', 'Year', 'Genre', 'GenreLabel']].iloc[1:7]
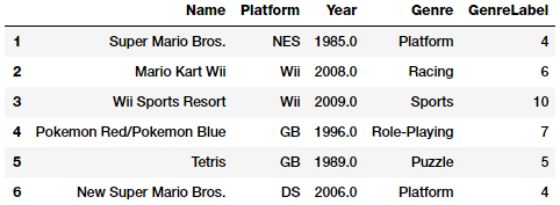
如果你计划将它们用作预测的响应变量,那么这些标签通常可以直接用于scikit-learn等框架,但是如前所述,我们需要额外的编码步骤,然后才能将它们用作特征。
转换定序属性
定序属性是类别属性中具有序列特征的属性。让我们考虑一下我们在本系列第1部分中使用的神奇宝贝数据集( Pokémon dataset )。 以Generation属性为例。
poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8')
poke_df = poke_df.sample(random_state=1,
frac=1).reset_index(drop=True)
np.unique(poke_df['Generation'])
Output
------
array(['Gen 1', 'Gen 2', 'Gen 3', 'Gen 4', 'Gen 5', 'Gen 6'],
dtype=object)
根据以上输出,我们可以看到共有6代,每个神奇宝贝通常属于基于视频游戏的特定时代(当它们被发布时),并且电视系列也遵循类似的时间线。 这个属性通常是有序的(这里需要领域知识),因为属于第一代的大多数神奇宝贝都是比第二代更早在视频游戏和电视节目中推出的。 动漫迷们可以查看下图,它列出了每一代流行的神奇宝贝的一部分(球迷们的看法可能不同!)。

因此,他们是有序的。 一般来说,没有通用的模块或功能来根据订单自动将这些特征映射和转换为数字表示。 因此,我们可以使用自定义编码\映射方案。
gen_ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3,
'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
poke_df['GenerationLabel'] = poke_df['Generation'].map(gen_ord_map)
poke_df[['Name', 'Generation', 'GenerationLabel']].iloc[4:10]
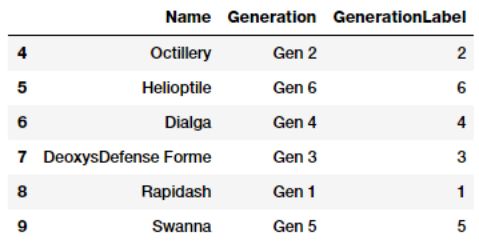
从上面的代码中可以明显看出,来自pandas的map(...)函数在转换这个定序特征时非常有用。
编码分类属性
如果你记得我们之前提到的内容,通常对类别数据的特征工程包括一个转换过程,我们在前一部分描述了一个转换过程,以及一个强制编码过程,我们应用特定的编码方案为特定的每个类别\值创建虚拟变量或特征分类属性。
你可能会好奇,我们只需要将类别转换为数字标签就行了,为什么还需要对它们编码?原因很简单。考虑到视频游戏的类型,如果我们直接在机器学习模型中提供GenreLabel属性作为特征,它会认为它是一个连续的数字特征,并认为10(Sports)大于6(Racing),但这是没有意义的,因为体育类型当然不会比赛车更大或更小,但它们本质上是不同的价值或类别,不能直接比较。因此,我们需要额外的一层编码方案,其中针对每个属性的所有不同类别中的每个唯一值或类别创建虚拟特征。
One-hot编码方案考虑到我们有任何具有m个标签(转换后)的分类属性的数字表示,这种one-hot编码方案将该属性编转换为m个只能包含1或0值的二元特征。分类中的每个观察值特征因此被转换为大小为m的矢量,其中只有一个值为1(表示它是激活的)。我们来看看我们的神奇宝贝数据集的一个子集,它描述了两个感兴趣的属性。
poke_df [['Name','Generation','Legendary']].iloc [4:10]
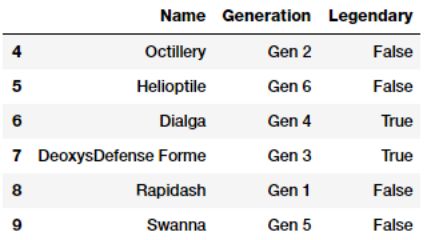
感兴趣的属性是神奇宝贝Generation及Legendary。 第一步是根据我们以前学到的内容将这些属性转换为数字表示。
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
# transform and map pokemon generations
gen_le = LabelEncoder()
gen_labels = gen_le.fit_transform(poke_df['Generation'])
poke_df['Gen_Label'] = gen_labels
# transform and map pokemon legendary status
leg_le = LabelEncoder()
leg_labels = leg_le.fit_transform(poke_df['Legendary'])
poke_df['Lgnd_Label'] = leg_labels
poke_df_sub = poke_df[['Name', 'Generation', 'Gen_Label',
'Legendary', 'Lgnd_Label']]
poke_df_sub.iloc[4:10]
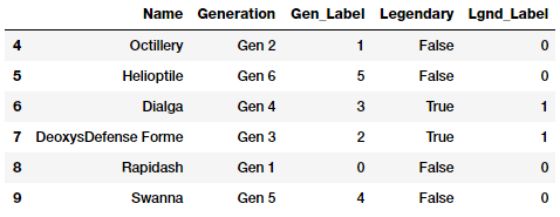
Gen_Label和Lgnd_Label用数字表示了类别特征。 现在让我们在这些特征上应用一种one-hot编码方案。
# encode generation labels using one-hot encoding scheme
gen_ohe = OneHotEncoder()
gen_feature_arr = gen_ohe.fit_transform(
poke_df[['Gen_Label']]).toarray()
gen_feature_labels = list(gen_le.classes_)
gen_features = pd.DataFrame(gen_feature_arr,
columns=gen_feature_labels)
# encode legendary status labels using one-hot encoding scheme
leg_ohe = OneHotEncoder()
leg_feature_arr = leg_ohe.fit_transform(
poke_df[['Lgnd_Label']]).toarray()
leg_feature_labels = ['Legendary_'+str(cls_label)
for cls_label in leg_le.classes_]
leg_features = pd.DataFrame(leg_feature_arr,
columns=leg_feature_labels)
通常,你可以使用fit_transform(...)函数将两个特征一起编码,并将两个特征的二维数组传递给它们。但是我们分别对每个特征进行编码,以便更容易理解。 现在让我们连接这些特征并查看最终结果。
poke_df_ohe = pd.concat([poke_df_sub, gen_features, leg_features], axis=1)
columns = sum([['Name', 'Generation', 'Gen_Label'],
gen_feature_labels, ['Legendary', 'Lgnd_Label'],
leg_feature_labels], [])
poke_df_ohe[columns].iloc[4:10]

因此,你可以看到已为Generation创建了6个虚拟变量或二元特征,并且为Legendary创建了2个虚拟变量或二元特征,因为它们分别是这些属性中不同类别的总数。。 一个类别的激活状态由这些虚拟变量之一中的1值表示,这在上面的数据中是很明显的。
因为在你的训练数据上建立了这种编码方案,并建立了一些模型,在使用新数据预测之前,对新数据也需要这样的编码,如下所示。
new_poke_df = pd.DataFrame([['PikaZoom', 'Gen 3', True],
['CharMyToast', 'Gen 4', False]],
columns=['Name', 'Generation', 'Legendary'])
new_poke_df

你可以通过调用scikit-learn的LabeLEncoder和OneHotEncoder API来处理数据。 首先我们进行Transformation。
new_gen_labels = gen_le.transform(new_poke_df['Generation'])
new_poke_df['Gen_Label'] = new_gen_labels
new_leg_labels = leg_le.transform(new_poke_df['Legendary'])
new_poke_df['Lgnd_Label'] = new_leg_labels
new_poke_df[['Name', 'Generation', 'Gen_Label', 'Legendary',
'Lgnd_Label']]
生成数字标签之后,即可应用编码方案.
new_gen_feature_arr = gen_ohe.transform(new_poke_df[['Gen_Label']]).toarray()
new_gen_features = pd.DataFrame(new_gen_feature_arr,
columns=gen_feature_labels)
new_leg_feature_arr = leg_ohe.transform(new_poke_df[['Lgnd_Label']]).toarray()
new_leg_features = pd.DataFrame(new_leg_feature_arr,
columns=leg_feature_labels)
new_poke_ohe = pd.concat([new_poke_df, new_gen_features, new_leg_features], axis=1)
columns = sum([['Name', 'Generation', 'Gen_Label'],
gen_feature_labels,
['Legendary', 'Lgnd_Label'], leg_feature_labels], [])
new_poke_ohe[columns]

因此,你可以看到,通过利用scikit-learn强大的API,可以轻松地将此方案应用于新数据。
你还可以通过利用pandas的to_dummies(...)函数轻松应用one-hot编码方案。
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
pd.concat([poke_df[['Name', 'Generation']], gen_onehot_features],
axis=1).iloc[4:10]
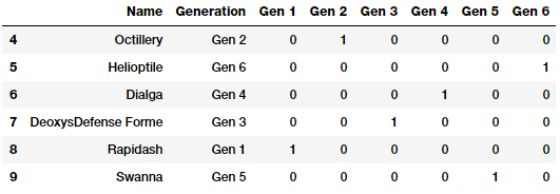
上述数据描述了应用于Generation属性的one-hot编码方案,并且结果与预期的早期结果相比相同。
虚拟编码方案(Dummy Coding )
虚拟编码方案类似于one-hot编码方案,不同点在于,在虚拟编码方案中,当应用于具有m个不同标签的分类特征时,我们得到m-1个二进制特征。 因此,类别变量的每个值被转换为大小为m-1的向量。额外的特征完全被忽略,因此如果分类值从{0,1,...,m-1}到第0或第m-1 特征列被丢弃,对应的类别值通常由全零(0)的向量表示。 让我们尝试通过删除第一级二进制编码特征(Gen 1)来
在神奇宝贝Generation中应用伪编码方案。
gen_dummy_features = pd.get_dummies(poke_df['Generation'],
drop_first=True)
pd.concat([poke_df[['Name', 'Generation']], gen_dummy_features],
axis=1).iloc[4:10]
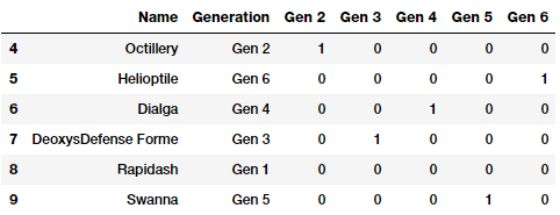
如果你愿意,你也可以选择向下面那样舍弃最后一级二进制编码特征(Gen 6)。
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
gen_dummy_features = gen_onehot_features.iloc[:,:-1]
pd.concat([poke_df[['Name', 'Generation']], gen_dummy_features],
axis=1).iloc[4:10]
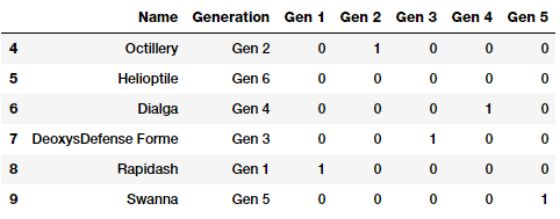
基于上述描述,很明显属于丢弃特征的类别被表示为像我们之前讨论的零向量(0)。
效应编码方案(Effect Coding)
效应编码方案实际上与虚拟编码方案很像。除了在编码时,效应编码将虚拟编码中全为0的特征值变成了-1。下面是一个例子。
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
gen_effect_features = gen_onehot_features.iloc[:,:-1]
gen_effect_features.loc[np.all(gen_effect_features == 0,
axis=1)] = -1.
pd.concat([poke_df[['Name', 'Generation']], gen_effect_features],
axis=1).iloc[4:10]
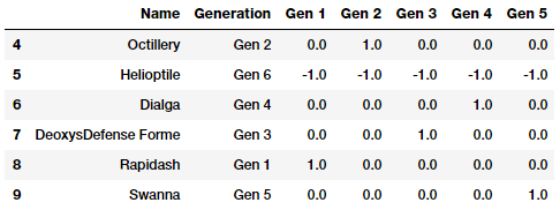
上面的输出清楚地表明,属于第六代的神奇宝贝现在用虚拟编码中的零值表示-1值。
计数方案(Bin-counting)
到目前为止我们讨论的编码方案在一般的分类数据上工作得很好,但是当任何特征中类别数的数量变得非常大时,问题就来了。m个标签就会产生m个独立的特征。这可以很容易地增加特征集的大小,导致出现如存储问题,模型训练在时间、空间和内存方面的问题。 除此之外,我们还必须处理通常所谓的“维度诅咒”,即特征多但是并且没有足够的代表性样本,模型性能开始受到影响,经常导致过拟合。

因此,我们需要针对具有大量可能类别(如IP地址)的特征寻找其他解决方案。二进制计数方案是处理具有多个类别的分类变量的有用方案。在这个方案中,我们不是使用实际的标签值进行编码,而是使用基于概率的关于值的统计信息以及我们在建模过程中预期的实际目标或响应值。一个简单的例子,将基于过去的IP地址历史数据和DDOS攻击中使用的历史数据,我们可以为任何IP地址造成的DDOS攻击建立概率值。使用这些信息,我们可以对输入特征进行编码,该输入特征描述了如果将来出现相同的IP地址,那么引起DDOS攻击的概率值是多少。这个方案需要详尽的历史数据作为先决条件。用一个完整的例子来描述这个目前是困难的,但是有几个在线的资源,你可以参考相同的资源。
特征哈希方案(Feature Hashing)
特征哈希方案是处理大规模分类特征的另一个有用的特征工程方案。在该方案中,哈希函数通常与预先设置的编码特征的数量(作为预定义长度的向量)一起使用,使得特征的哈希值被用作这个预定向量中的索引,并且值是相应更新的。由于哈希函数将大量值映射为小的有限值集合,因此多个不同的值可能会创建相同的哈希,称为冲突。通常,使用带符号的哈希函数,以便将从哈希获得的值的符号用作存储在适当索引处的最终特征向量中的值的符号。这应确保较少冲突和由冲突造成的误差积累。
哈希方案适用于字符串,数字和其他结构,如向量。你可以将哈希输出视为有限的一组b bins,以便当哈希函数应用于相同的值\ categories时,根据哈希值将它们分配到b bins中相同的bin(或bin的子集) 。我们可以预先定义b值,它将成为我们使用特征哈希方案编码的每个分类属性的编码特征向量的最终大小。
因此,即使我们在一个特征中有1000多个不同的类别,并且我们将b = 10设置为最终的特征向量大小,但如果我们使用one-hot编码方案,输出特征集合仍然只有10个特征。我们来考虑我们视频游戏数据集中的Genre属性。
unique_genres = np.unique(vg_df[['Genre']])
print("Total game genres:", len(unique_genres))
print(unique_genres)
Output
------
Total game genres: 12
['Action' 'Adventure' 'Fighting' 'Misc' 'Platform' 'Puzzle' 'Racing'
'Role-Playing' 'Shooter' 'Simulation' 'Sports' 'Strategy']
我们可以看到总共有12种类型的视频游戏。 如果我们在Genre特征上使用了one-hot编码,那我们最终得到12个特征。 相反,我们现在将通过利用scikit-learn的FeatureHasher类来使用功能哈希方案,该类使用带有签名的32位Murmurhash3哈希函数。 在这种情况下,我们将预先定义最终的特征向量大小为6。
from sklearn.feature_extraction import FeatureHasher
fh = FeatureHasher(n_features=6, input_type='string')
hashed_features = fh.fit_transform(vg_df['Genre'])
hashed_features = hashed_features.toarray()
pd.concat([vg_df[['Name', 'Genre']], pd.DataFrame(hashed_features)],
axis=1).iloc[1:7]
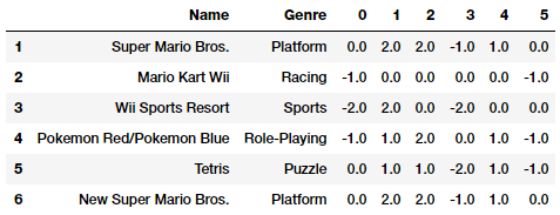
结论
这些例子为你提供了一个在离散的类别数据上应用特征工程的好例子。如果你阅读本系列的第1部分,你会发现与连续的数值数据相比,处理类别数据有一定难度,但绝对有趣!我们还讨论了使用特征工程处理大型特征空间的一些方法,但你还应该记住还有其他技术,包括特征选择和降维方法来处理大型特征空间。我们将在后面的文章中介绍其中的一些方法。
本文中使用的所有代码和数据集都可以从下面链接中获取。
https://github.com/dipanjanS/practical-machine-learning-with-python/tree/master/notebooks/Ch04_Feature_Engineering_and_Selection
原文链接:
https://towardsdatascience.com/understanding-feature-engineering-part-1-continuous-numeric-data-da4e47099a7b
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能知识星球服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



