【论文推荐】最新5篇视频分类相关论文—上下文门限、深度学习、时态特征、结构化标签推理、自动机器学习调优
【导读】专知内容组整理了最近五篇视频分类(Video Classification)相关文章,为大家进行介绍,欢迎查看!
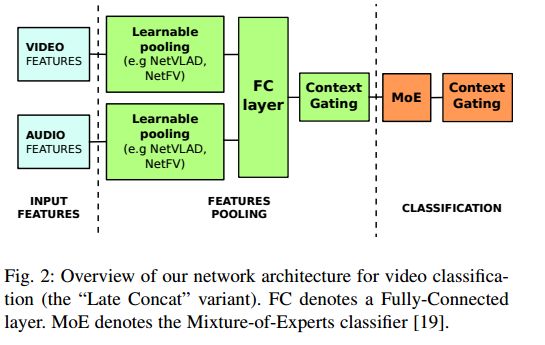
1.Learnable pooling with Context Gating for video classification(基于可学习的池化与上下文门限视频分类)
作者:Antoine Miech,Ivan Laptev,Josef Sivic
摘要:Current methods for video analysis often extract frame-level features using pre-trained convolutional neural networks (CNNs). Such features are then aggregated over time e.g., by simple temporal averaging or more sophisticated recurrent neural networks such as long short-term memory (LSTM) or gated recurrent units (GRU). In this work we revise existing video representations and study alternative methods for temporal aggregation. We first explore clustering-based aggregation layers and propose a two-stream architecture aggregating audio and visual features. We then introduce a learnable non-linear unit, named Context Gating, aiming to model interdependencies among network activations. Our experimental results show the advantage of both improvements for the task of video classification. In particular, we evaluate our method on the large-scale multi-modal Youtube-8M v2 dataset and outperform all other methods in the Youtube 8M Large-Scale Video Understanding challenge.
期刊:arXiv, 2018年3月5日
网址:
http://www.zhuanzhi.ai/document/8987845b6e5906d5c4f3cdaca451aa8b
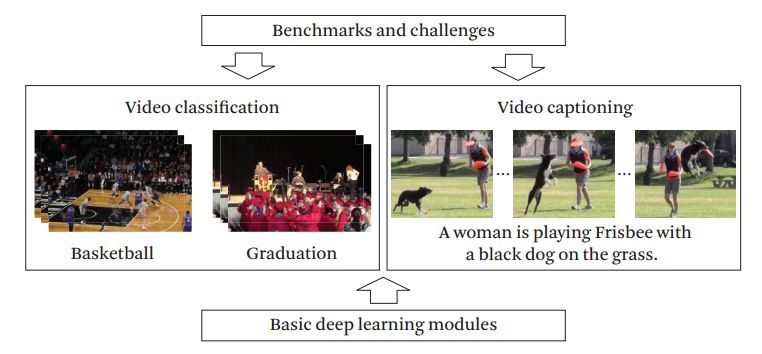
2.Deep Learning for Video Classification and Captioning(基于深度学习的视频分类和描述)
作者:Zuxuan Wu,Ting Yao,Yanwei Fu,Yu-Gang Jiang
机构:College Park,University of Maryland,Fudan University
摘要:Accelerated by the tremendous increase in Internet bandwidth and storage space, video data has been generated, published and spread explosively, becoming an indispensable part of today's big data. In this paper, we focus on reviewing two lines of research aiming to stimulate the comprehension of videos with deep learning: video classification and video captioning. While video classification concentrates on automatically labeling video clips based on their semantic contents like human actions or complex events, video captioning attempts to generate a complete and natural sentence, enriching the single label as in video classification, to capture the most informative dynamics in videos. In addition, we also provide a review of popular benchmarks and competitions, which are critical for evaluating the technical progress of this vibrant field.
期刊:arXiv, 2018年2月22日
网址:
http://www.zhuanzhi.ai/document/2a33c8e2ff075981e9cf6264fd3d4f00
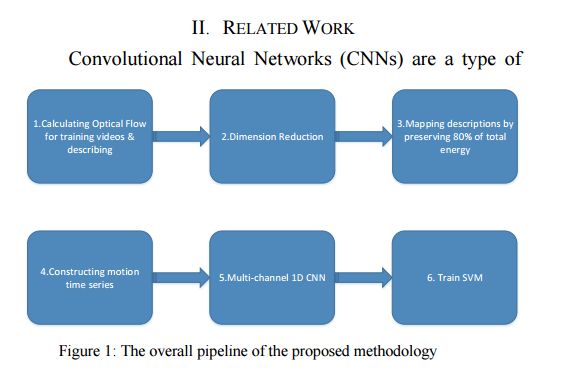
3.Learning Representative Temporal Features for Action Recognition(学习具有代表性的动作识别的时态特征)
作者:Ali Javidani,Ahmad Mahmoudi-Aznaveh
机构:Shahid Beheshti University,Shahid Beheshti University
摘要:In this paper we present a novel video classification methodology that aims to recognize different categories of third-person videos efficiently. The idea is to tracking motion in videos and extracting both short-term and long-term features from motion time series by training a multi-channel one dimensional Convolutional Neural Network (1D-CNN). The positive point about our method is that we only try to learn representative temporal features along the temporal dimension. Spatial features are extracted using pre-trained networks that have already been trained on large scale image recognition datasets. Learning features toward only one dimension reduces the number of calculations significantly and makes our method applicable to even smaller datasets. Furthermore we show that not only our method could reach state-of-the-art results on two public datasets UCF11 and jHMDB, but also we could obtain a strong feature vector representation which in compare with other methods it is much efficient.
期刊:arXiv, 2018年2月20日
网址:
http://www.zhuanzhi.ai/document/815b0c2d536494605d2ee74ef38fd421
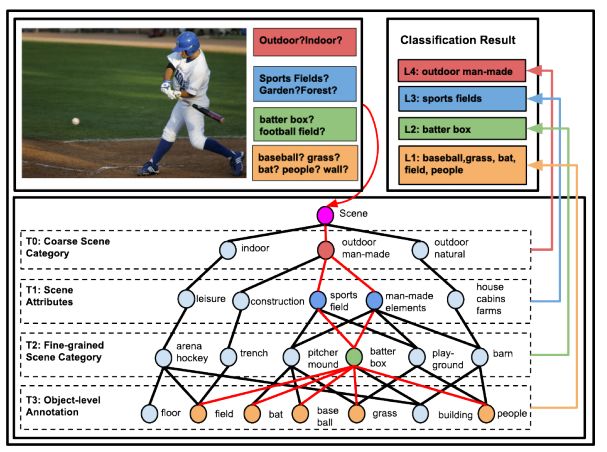
4.Structured Label Inference for Visual Understanding(视觉理解的结构化标签推理)
作者:Nelson Nauata,Hexiang Hu,Guang-Tong Zhou,Zhiwei Deng,Zicheng Liao,Greg Mori
摘要:Visual data such as images and videos contain a rich source of structured semantic labels as well as a wide range of interacting components. Visual content could be assigned with fine-grained labels describing major components, coarse-grained labels depicting high level abstractions, or a set of labels revealing attributes. Such categorization over different, interacting layers of labels evinces the potential for a graph-based encoding of label information. In this paper, we exploit this rich structure for performing graph-based inference in label space for a number of tasks: multi-label image and video classification and action detection in untrimmed videos. We consider the use of the Bidirectional Inference Neural Network (BINN) and Structured Inference Neural Network (SINN) for performing graph-based inference in label space and propose a Long Short-Term Memory (LSTM) based extension for exploiting activity progression on untrimmed videos. The methods were evaluated on (i) the Animal with Attributes (AwA), Scene Understanding (SUN) and NUS-WIDE datasets for multi-label image classification, (ii) the first two releases of the YouTube-8M large scale dataset for multi-label video classification, and (iii) the THUMOS'14 and MultiTHUMOS video datasets for action detection. Our results demonstrate the effectiveness of structured label inference in these challenging tasks, achieving significant improvements against baselines.
期刊:arXiv, 2018年2月19日
网址:
http://www.zhuanzhi.ai/document/ac2339b6e9d809705f79fc00ac00b099
5.MLtuner: System Support for Automatic Machine Learning Tuning(MLtuner:自动机器学习调优的系统支持)
作者:Henggang Cui,Gregory R. Ganger,Phillip B. Gibbons
机构:Carnegie Mellon University
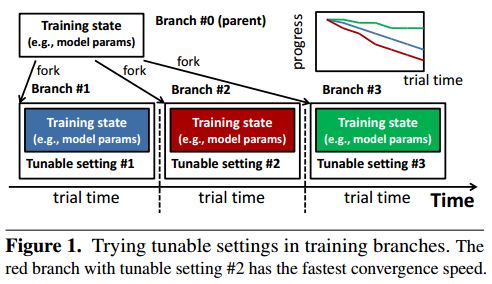
摘要:MLtuner automatically tunes settings for training tunables (such as the learning rate, the momentum, the mini-batch size, and the data staleness bound) that have a significant impact on large-scale machine learning (ML) performance. Traditionally, these tunables are set manually, which is unsurprisingly error-prone and difficult to do without extensive domain knowledge. MLtuner uses efficient snapshotting, branching, and optimization-guided online trial-and-error to find good initial settings as well as to re-tune settings during execution. Experiments show that MLtuner can robustly find and re-tune tunable settings for a variety of ML applications, including image classification (for 3 models and 2 datasets), video classification, and matrix factorization. Compared to state-of-the-art ML auto-tuning approaches, MLtuner is more robust for large problems and over an order of magnitude faster.
期刊:arXiv, 2018年3月20日
网址:
http://www.zhuanzhi.ai/document/5803972ddb941d18dd2cd93d89b8b10b
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!
展开全文



