【CVPR2018论文笔记】非监督任意姿势人体图像合成
【导读】在CVPR2018有很多优秀的文章,这篇文章目的在于以非监督的方式利用一张人体图像合成任意姿势的同一个人的新图片。
【CVPR 2018 论文】
Unsupervised Person Image Synthesis in Arbitrary Poses

摘要
我们提出了用生成对抗网络合成人在任意姿势的真实图像。输入一个人的图像并给定一个用2D骨架表示的姿势,我们的模型能够合成同一个人的一张新图片,这张图片基于给定的姿势并且能够从新的角度看原来的图片中可见的部分,也能合成原来图片不可见的部分。这个问题已经可以用监督学习解决:在训练过程中给出新的姿势及对应的真实图片。我们用一种完全非监督方法去解决这个问题。我们将这个挑战分为两个子任务:1. 我们考虑一个姿势条件双向生成器去将最开始生成的图像映射到原来的姿势,这样可以和输入的图像进行比较。2. 我们设计一个损失函数,将内容和风格一起考虑进来,这样可以产生高质量图像。在DeepFashion数据集上的实验表明我们模型生成的图像能够和监督学习生成的图像得到一样好的结果。
简介
从一张图像去生成一个人在任意姿势的图像有着很多激动人心的应用,包括时尚界和商业界、摄影学的自动编辑和动画制作。完成这个任务需要估计人体的三维几何模型、头发、衣服,还要知道可见部分的反射模型和预测被阻挡的部分,如果没有做这些工作,那将是很难完成的任务。然而,GAN已经在生成真实图像取得了很成功的效果。最近,GAN也被应用在从单视角图像得到人的多视角图像的问题,其产生效果很好,但受到必须为全监督方式的限制,也就是说训练过程需要给出同一个人穿着相同的衣服以不同姿势的照片。这就需要特定的数据集,特别是在时尚领域的数据集。如果将这个问题以非监督方式解决,那么在训练过程中我们可以利用很多图片,并且还可以用那些没有多角度人照片的数据集。
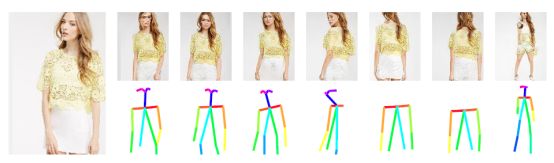
在本文中,我们提出了一个非监督的GAN框架,给定一个人的图片,自动生成一个人不同照相机视角或者不同姿势的图片。这个生成模型能够合成原始图像的可见部分,也能预测原始图像的不可见部分。如图1所示,生成图片有着和输入图片完全不一样的姿势,但其身体形状和纹理与原图片一模一样。为了去利用没有标签的数据(例如,训练数据包括一个人的单张图片加上需要的姿势),我们提出了一个GAN框架,这个框架包括姿势条件对抗网络,Cycle-GANs和针对图像迁移的损失函数。
更具体的,为了避免同一个人在不同的姿势需要不同的图片的问题,我们将问题分为两个阶段:1. 我们考虑了一个姿势条件双向对抗框架,这个框架给定一张训练图片,在给定姿势下生成新的图片,然后利用这个新的图片反过来转化到原来的姿势,进而可以和输入图片进行比较。2. 为了得到高质量图片,我们设计新的损失函数涉及到三种图片:1.原来的图片;2根据给定的姿势生成新的图片;3. 反过来转化到原来的姿势——为了并入内容项和风格项。这个函数以姿势参数为条件并且让生成的图像能够维持和原来的图片一样的内容和风格。
在DeepFashion数据集上的实验得到了非常好的结果,生成的图片和以监督学习得到的图片一样好。
问题描述
给定一个人的单视角图片,我们目标是以非监督方法训练一个GAN模型。我们学习映射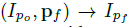
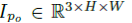
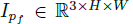
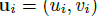
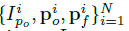
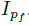
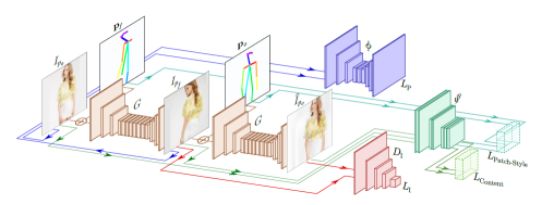
方法
图2表示模型的全框架,这个模型由四个主要部分组成:1.生成器G(I|P)将一个人一个姿势的图片映射到另一个姿势的图片。注意G用了两次,先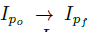
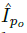
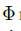
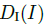
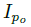
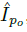
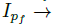
姿势表示
一个图片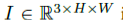
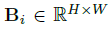
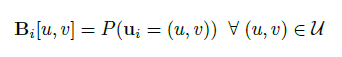
上式中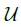
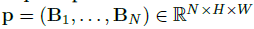
网络框架
生成器:生成器为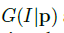
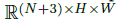
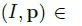
辨别器:辨别器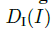
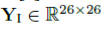
姿势检测: 给定一个人的图片I,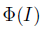
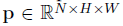
模型学习
图像对抗损失:和基本的GAN的类似,辨别器试图去辨别生成的图像和真实图片,生成器试图生成图像去欺骗辨别器。
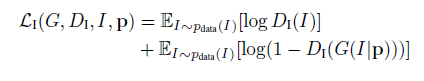
条件姿势损失:生成器不仅要生成类似真实的图片,还要保证新的图像其姿势和给定的姿势一致,即:
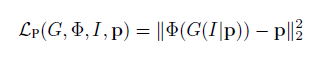
特征损失:我们需要保证生成的图像和原来的图像个人特征一致,例如身体形状、头发风格。我们设计了内容-风格损失函数。对于内容项,我们根据生成的图像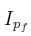
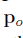
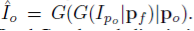
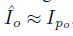
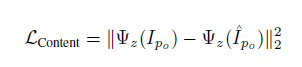
为了将原来图像的风格保留到新的图像上,我们要保证两个图像骨骼节点附近的纹理是相似的。我们让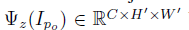
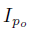
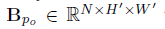
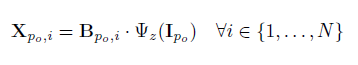
对于每个块,我们利用Gram 矩阵生成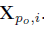
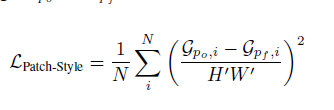
最后定义整个特征损失为:
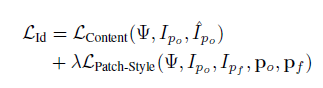
全部损失:将前面所有损失线性求和:
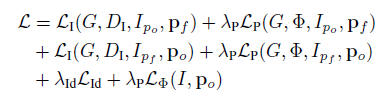
我们的目的是去:
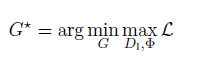
实验结果
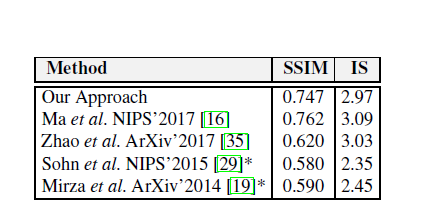
定量分析:
定性分析:

可以发现实验结果很好。
原文链接:
http://www.iri.upc.edu/files/scidoc/2024-Unsupervised-person-image-synthesis-in-arbitrary-poses.pdf
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



