谷歌BERT斩获最佳长论文!自然语言顶会NAACL2019最佳论文5篇出炉
导读
自然语言处理四大顶会之一NAACL 2019 将于 6 月 2 日-7 日在美国明尼阿波利斯市举行。据官方统计,NAACL 2019 共收到 1955 篇论文,接收论文 424 篇,录取率仅为 22.6%。其中长论文投稿 1198 篇,短论文 757 篇。今日,大会揭晓了本届会议的最佳论文,谷歌 BERT 论文获得最佳长论文奖项。论文末尾附论文打包下载

https://naacl2019.org/blog/best-papers/
最佳长论文
BERT:Pre-raining of Deep Bidirectional Transformers for Language Understanding
作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova
http://www.zhuanzhi.ai/paper/49f897ff4de3ea0e5bb0326078a7dab9
本文介绍一种称为BERT的新语言表征模型,意为来自变换器的双向编码器表征量(BidirectionalEncoder Representations from Transformers)。不同于最近的语言表征模型(Peters等,2018; Radford等,2018),BERT旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的BERT表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推理)创建当前最优模型,无需对任务特定架构做出大量修改。
BERT的概念很简单,但实验效果很强大。它刷新了11个NLP任务的当前最优结果,包括将GLUE基准提升至80.4%(7.6%的绝对改进)、将MultiNLI的准确率提高到86.7%(5.6%的绝对改进),以及将SQuADv1.1问答测试F1的得分提高至93.2分(1.5分绝对提高)——比人类性能还高出2.0分。
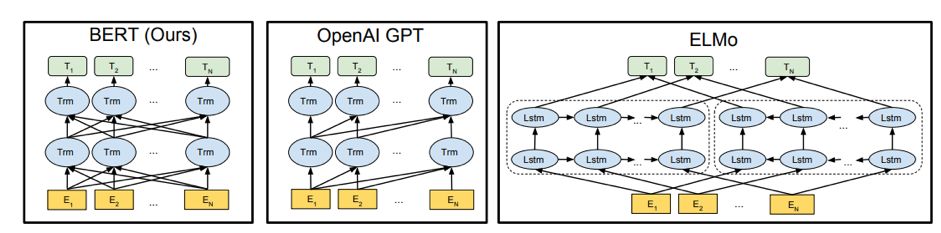
BERT的slides: BERT一作Jacob Devlin斯坦福演讲PPT:BERT介绍与答疑
最佳专题论文(Best Thematic Paper)
What's in a Name? Reducing Bias in Bios Without Access to Protected Attributes
作者:Alexey Romanov, Maria De-Arteaga, Hanna Wallach, Jennifer Chayes, Christian Borgs, Alexandra Chouldechova, Sahin Geyik, Krishnaram Kenthapadi, Anna Rumshisky and Adam Kalai(CMU、微软研究院、领英)
http://www.zhuanzhi.ai/paper/79969b317ac103d8804fbd49b8d05ebd
越来越多的研究提出了减少机器学习系统中偏见的方法。这些方法通常依赖于对受保护属性(如人种、性别或年龄)的获取。然而,这引发了两大问题:1)受保护的属性可能无法获取或不能合法使用;2)通常需要同时考虑多个受保护属性及其交集。为了减少职业分类中的偏见,本文作者提出了一种可以抑制某人真实职业预测概率与其姓名词嵌入之间关系的方法。
该方法利用了编码在词嵌入中的社会偏见,消除了对受保护属性的需要。重要的是,该方法仅在训练时需要获取人名,部署时并不需要。作者使用一个大型的在线传记数据集评估了该方法的两种变体,发现二者都能同时减少种族和性别偏见,而且几乎不降低分类器的真正率。
最佳可解释 NLP 论文
CNM: An Interpretable Complex-valued Network for Matching
作者:Qiuchi Li, Benyou Wang and Massimo Melucci
http://www.zhuanzhi.ai/paper/0c81fa70ab158c9ade6153b89769f882
本文试图用量子物理的数学框架来模拟人类语言。这个框架结合了量子物理中精心设计的数学公式,将不同的语言单位统一在一个复杂向量空间中,例如单词作为量子态的粒子,句子作为混合系统。建立了一个复值网络来实现该框架的语义匹配。由于具有良好约束的复值组件,网络允许对显式物理意义进行解释。提出的复值匹配网络(CNM)在两个基准问题回答(QA)数据集上具有与强CNN和RNN基线相当的性能。
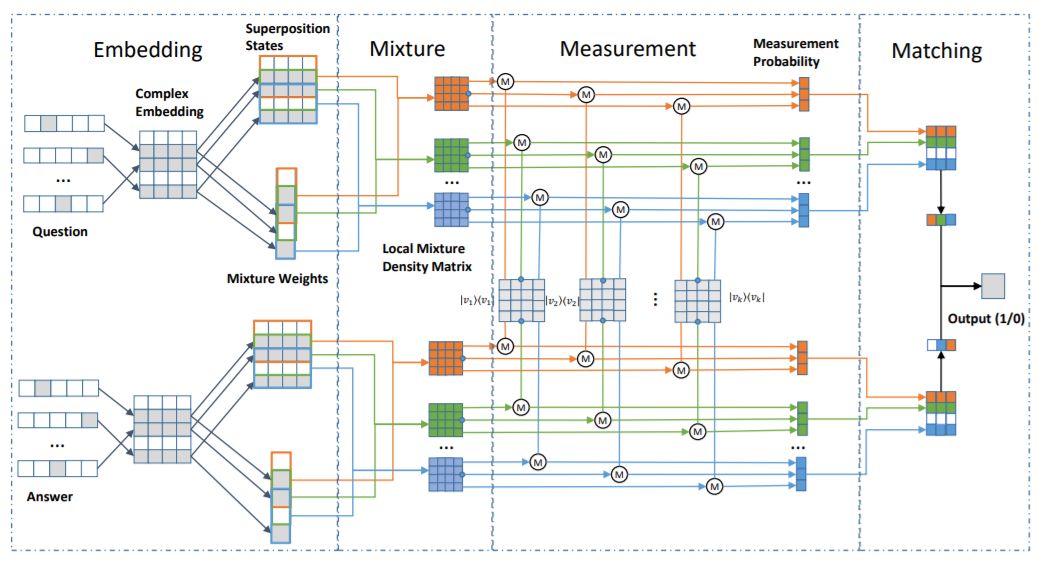
最佳短论文
Probing the Need for Visual Context in Multimodal Machine Translation
Ozan Caglayan, Pranava Madhyastha, Lucia Specia and Loïc Barrault(勒芒大学、帝国理工学院)
http://www.zhuanzhi.ai/paper/a68ff37f3cb06c904a54aab774f9da2f
当前关于多模态机器翻译(MMT)的研究表明,视觉模态要么是非必需的,要么作用有限。本文作者假设这是因为该任务唯一可用数据集 Multi30K 使用的句子太简单、简短和重复,这些语句将源文本渲染为充分的语境。然而,通常情况下,我们认为可以将视觉和文本信息结合起来,以实现基础翻译(ground translation)。
本文通过系统的分析来探讨视觉模态对当前最佳 MMT 模型的贡献,分析时作者部分地删除了源文本语境,使模型无法接收到完整的文本。结果表明,在有限的文本语境下,模型能够利用视觉输入生成更好的翻译结果。当前的研究认为视觉模态对 MMT 模型来说并不重要,要么是因为图像特征的质量,要么是因为将它们整合进模型的方式,但本研究颠覆了这一看法。

最佳资源论文
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie and Jonathan Berant(以色列特拉维夫大学、艾伦人工智能研究所)
http://www.zhuanzhi.ai/paper/684ae1611ba354e23f55d8791b56b60f
人们通常利用丰富的世界知识和特定语境来回答问题。近期研究主要聚焦于基于关联文档或语境来回答问题,对基础知识几乎没有要求。为了研究使用先验知识的问答,我们提出了一个关于常识问答的新型数据集 CommonsenseQA。为了捕捉关联之外的常识,我们从 ConceptNet (Speer et al., 2017) 中抽取了多个目标概念,它们与某个源概念具备同样的语义关系。
我们让众包工人编写提及源概念的选择题,并区分每个目标概念之间的差别。这鼓励众包工人编写具备复杂语义的问题,而问答这类问题通常需要先验知识。我们通过该步骤创建了 12,247 个问题,并用大量强基线模型做实验,证明该新型数据集是有难度的。我们的最优基线基于 BERT-large (Devlin et al., 2018),获得了 56% 的准确率,低于人类准确率(89%)。
【论文打包便捷下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“NAACL2019”就可以获取最佳论文集合的下载链接~
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!520+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



