春节充电系列:李宏毅2017机器学习课程学习笔记24之结构化学习-Structured SVM(part 2)
【导读】我们在上一节的内容中已经为大家介绍了台大李宏毅老师的机器学习课程的Structured learning-Structured SVM(part 2),这一节将主要针对讨论Structured learning-Structured SVM的其他知识。本文内容主要针对机器学习中Structured learning-Structured SVM的Non-separable case,Regularization,Structured SVM,Cutting Plane Algorithm,Multi-class SVM和Binary SVM以及Beyond Structured SVM分别详细介绍。话不多说,让我们一起学习这些内容吧
春节充电系列:李宏毅2017机器学习课程学习笔记02之Regression
春节充电系列:李宏毅2017机器学习课程学习笔记03之梯度下降
春节充电系列:李宏毅2017机器学习课程学习笔记04分类(Classification)
春节充电系列:李宏毅2017机器学习课程学习笔记05之Logistic 回归
春节充电系列:李宏毅2017机器学习课程学习笔记06之深度学习入门
春节充电系列:李宏毅2017机器学习课程学习笔记07之反向传播(Back Propagation)
春节充电系列:李宏毅2017机器学习课程学习笔记08之“Hello World” of Deep Learning
春节充电系列:李宏毅2017机器学习课程学习笔记09之Tip for training DNN
春节充电系列:李宏毅2017机器学习课程学习笔记10之卷积神经网络
春节充电系列:李宏毅2017机器学习课程学习笔记11之Why Deep Learning?
春节充电系列:李宏毅2017机器学习课程学习笔记12之半监督学习(Semi-supervised Learning)
春节充电系列:李宏毅2017机器学习课程学习笔记13之无监督学习:主成分分析(PCA)
春节充电系列:李宏毅2017机器学习课程学习笔记14之无监督学习:词嵌入表示(Word Embedding)
春节充电系列:李宏毅2017机器学习课程学习笔记15之无监督学习:Neighbor Embedding
春节充电系列:李宏毅2017机器学习课程学习笔记16之无监督学习:自编码器(autoencoder)
春节充电系列:李宏毅2017机器学习课程学习笔记17之深度生成模型:deep generative model part 1
春节充电系列:李宏毅2017机器学习课程学习笔记18之深度生成模型:deep generative model part 2
春节充电系列:李宏毅2017机器学习课程学习笔记19之迁移学习(Transfer Learning)
春节充电系列:李宏毅2017机器学习课程学习笔记20之支持向量机(support vector machine)
春节充电系列:李宏毅2017机器学习课程学习笔记21之结构化学习(Structured learning)介绍篇
春节充电系列:李宏毅2017机器学习课程学习笔记22之结构化学习(Structured learning)线性模型
春节充电系列:李宏毅2017机器学习课程学习笔记23之结构化学习-Structured SVM(part 1)
课件网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17.html
视频网址:
https://www.bilibili.com/video/av15889450/index_1.html
李宏毅机器学习笔记24 Structured learning-Structured SVM(part 2)
1.Non-separable case
上一次笔记我们讲到了non-separable case的梯度下降的loss function,实际上minimize这个新的损失函数就是最小化训练集error的上界

我们定义一个新的损失函数C’,C’是正确的y和错误的y之间的差距,我们希望这个C’越小越好,然而C’可能是不可微分函数。所以我们要找到C’的上界,minimize这个上界实际上就是minimize这个C’,C’的上界就是如下图所示的Cn,证明如下

Cn的种类还有很多种,例如slack variable rescaling

2.Regularization
因为训练数据和测试数据可能有不同的分布,所以我们可以加上正则项

梯度下降的时候也会有相应的改变

3.Structured SVM
我们可以通过移位改变Cn不等式的形式,当我们试图最小化Cn的时候,下图两式是相等的
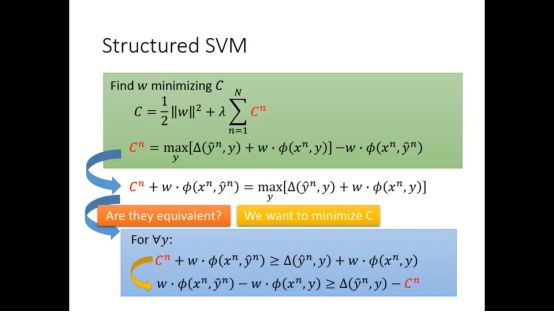
于是整个式子总结来说就变成下图的形式
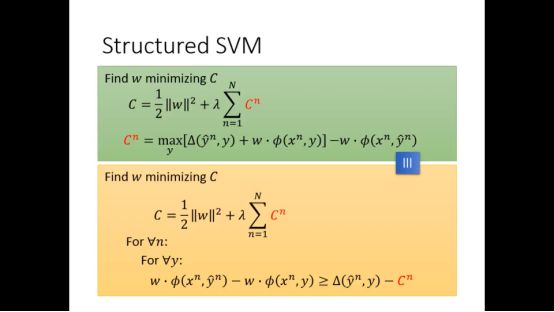
我们将Cn改个名称
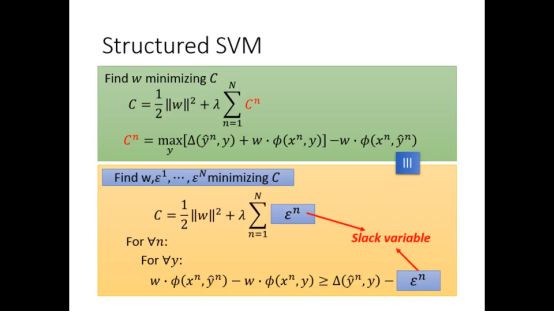
进一步我们可以发现slack variable是大于等于0的
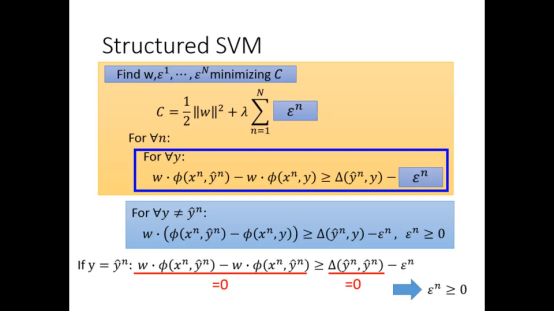
Slack variable的作用是放宽限制,使得margin更小
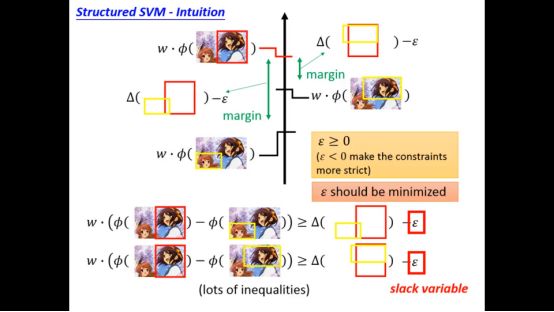
总的来说就变成如下形式
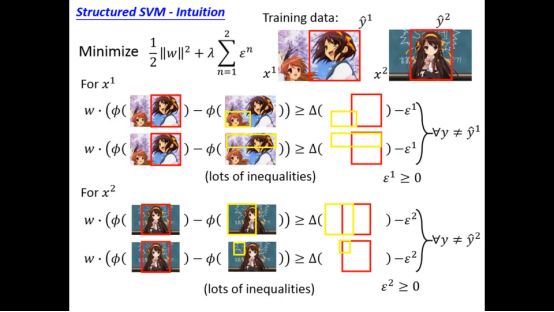
我们要解决的问题和SVM是大同小异的,可以用SVM已有的一些方法解决问题,但唯一的缺点就是限制太多了
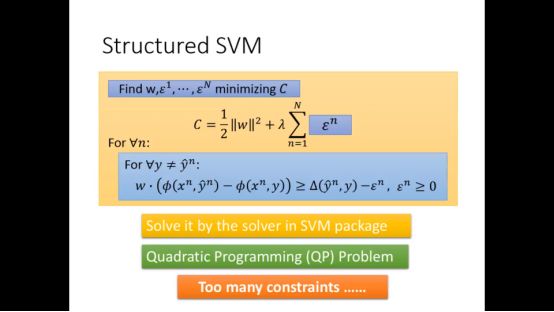
当将以上式子图像化我们可以发现w和slack variable将C空间划分为好多区域,我们要找到满足这些限制条件的最小的C
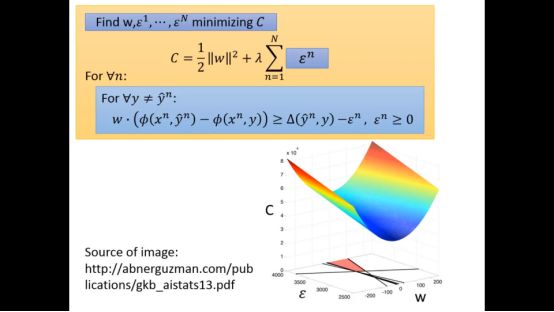
4.Cutting Plane Algorithm
尽管限制很多,但有些限制并没有真正的影响结果
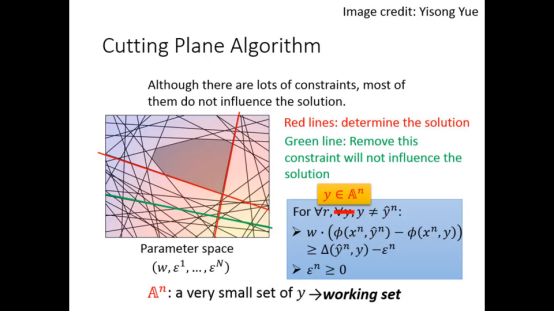
我们可以采用Cutting Plane Algorithm找到满足限制条件的最小的C
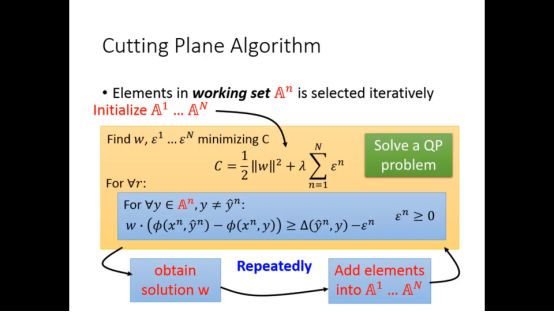
当我们没有任何限制的时候会找到一个最小点

每次寻找最严重的contraints
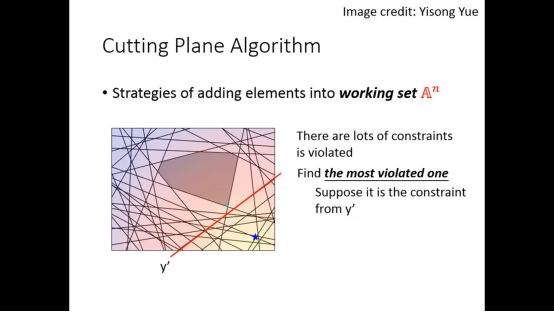
然后针对这个contraints找C,并假设这个contraints是来自y’

继续迭代下去
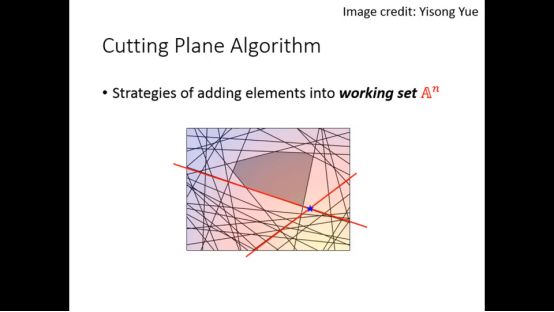
最终找到最后的点
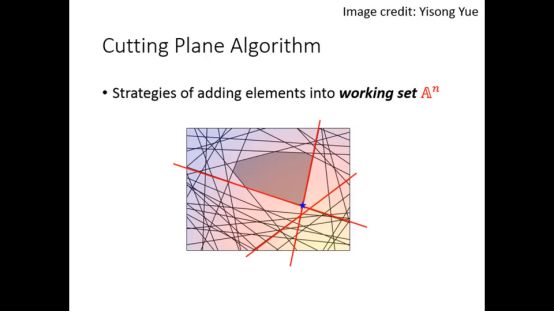
我们需要一个衡量看哪个限制是违反最严重的方法

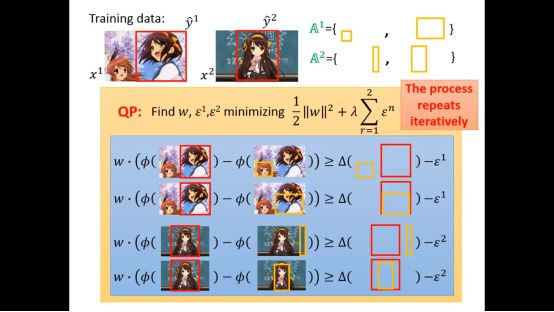
所以cutting plane algorithm整体流程如下

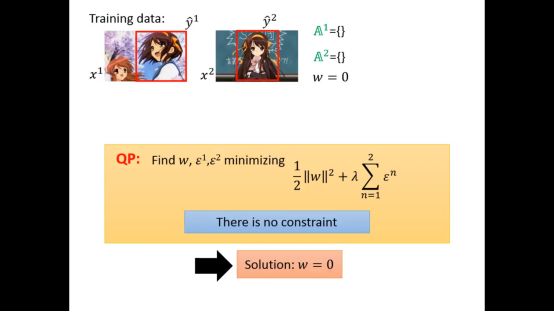
下面再举一个实际的例子,最开始w为0,没有限制
然后针对每个训练集我们会找到y’
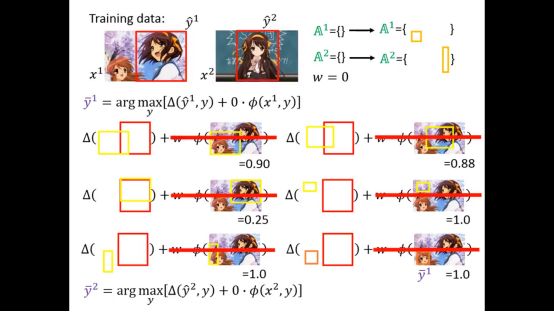
这里我们有两个训练集,所有有两个限制,一般的solver都可以解决这个问题,得到w1
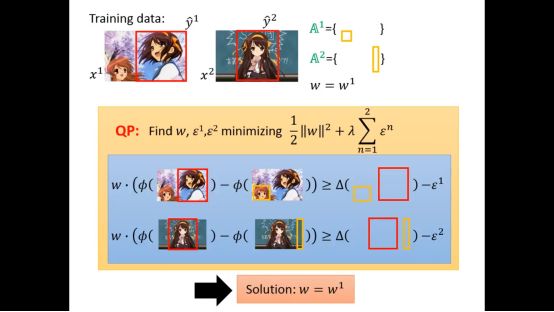
得到w1后继续找下去
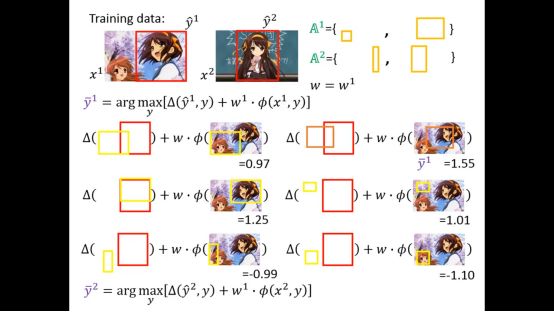
然后一直迭代,知道算法结束
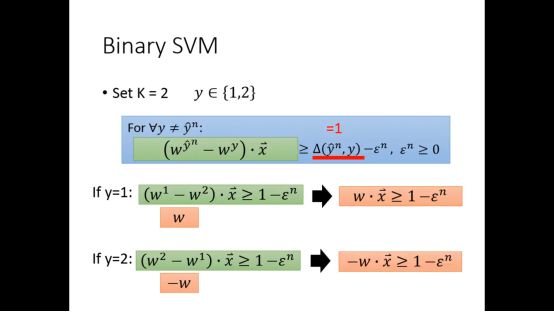
5.Multi-class SVM和Binary SVM
对于Multi-class SVM,就对应这个K个weight向量

Problem2的表达式也会有相应改变

假设有N的data,K个类,就有N(k-1)个限制

我们可以稍微改变一下限制函数的形式

Binary SVM就是Multi-class SVM的一种特殊情况
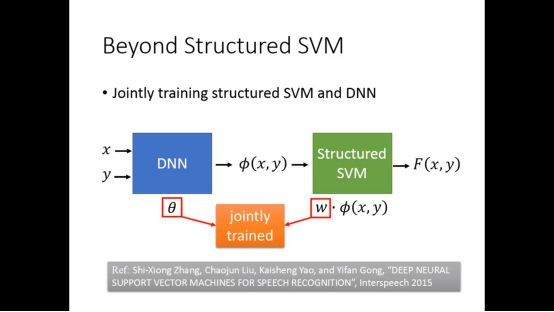
6.Beyond Structured SVM
因为structured SVM是线性的,有限,所以需要融入DNN
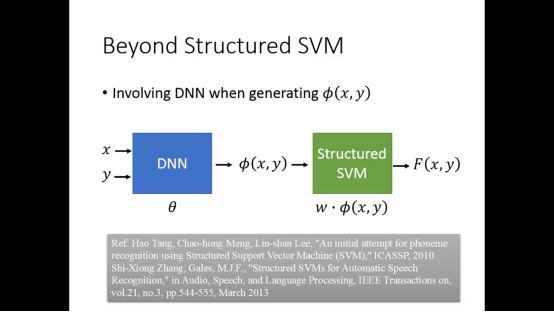
Θ和w会一起训练
对于Structured SVM的内容我们就介绍完了。
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“LHY2017” 就可以获取 2017年李宏毅中文机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



