DeepMind新作生成查询网络GQN:无监督渲染3D场景
给定立方体积木的几个侧面剪影,你能否「脑补」出它的整个 3D 形状?这看起来像是行测中的图形题,考验人们从 2D 画面到 3D 空间的转换能力。在 DeepMind 最新发表在顶级期刊 Science 的论文《Neural scene representation and rendering》中,计算机通过「生成查询网络 GQN」也拥有了这种空间推理能力。
理解视觉场景时,我们依赖的不仅仅是眼睛:我们的大脑利用已有知识来推理,并做出远远超过视线所及的推论。例如,当第一次进入一个房间时,你会立即认出里面的物品以及它们的位置。如果你看到一张桌子的三条腿,你会推断可能还有第四条腿,形状和颜色相同,只不过在视线之外。即使你看不到房间里的所有东西,你也可以勾画出它的布局,或者从另一个角度想象它的样子。
这些视觉和认知任务对人类来说似乎毫不费力,但对我们的人工智能系统来说却是一个重大挑战。如今,最先进的视觉识别系统需要使用由人类标注的大量图像数据来进行训练的。获取这些数据是一个成本高昂且耗时的过程,需要人工对数据集中每个场景中每个对象的每个方面进行标记。而实验结果通常只能捕获到整体场景内容的一小部分,这限制了根据该数据训练的人工视觉系统。随着我们开发出现实世界中更复杂的机器,我们希望它们可以充分理解周围的环境:最近的地面在哪里?沙发是用什么材料做的?哪一个光源产生了所有的阴影?电灯开关可能在哪里?
DeepMind新提出的GQN,就是这样一种新思路。 DeepMind 创始人(同时也是该论文的作者之一)戴密斯·哈萨比斯表示:「我们一直着迷于大脑是如何在意识中构建空间图像的,我们的最新《Science》论文引入了 GQN:它可以从一些 2D 快照中重建场景的 3D 表示,并可以通过任何新的视角不断增强这一表示。」
DeepMind的这套视觉系统,也即生成查询网络(GQN),使用从不同视角收集到的某个场景的图像,然后生成关于这个场景的抽象描述,通过一个无监督的表示学习过程,学习到了场景的本质。之后,在学到的这种表示的基础上,网络会预测从其他新的视角看这个场景将会是什么样子。这一过程非常类似人脑中对某个场景的想象。而理解一个场景中的视觉元素是典型的智能行为。
表示网络与生成网络
GQN模型由两部分组成:一个表示网络、一个生成网络。
表示网络将智能体观察到的图像作为输入,然后生成一个描述潜在场景的表示(向量)。
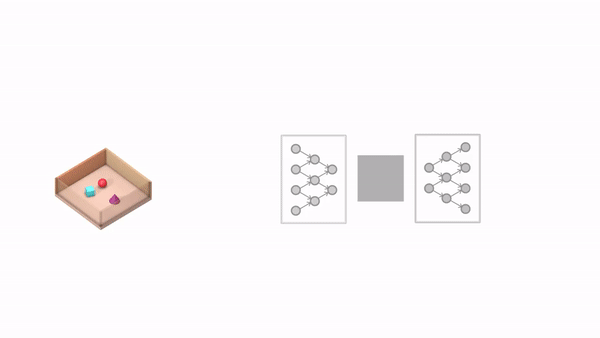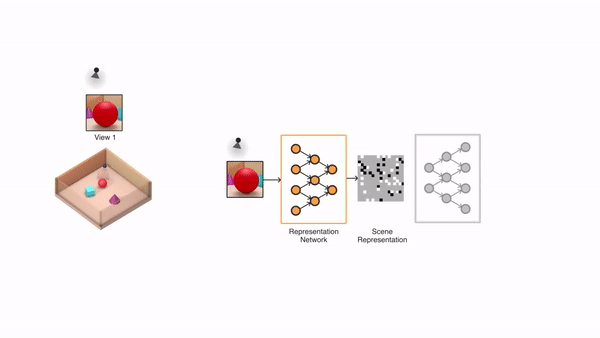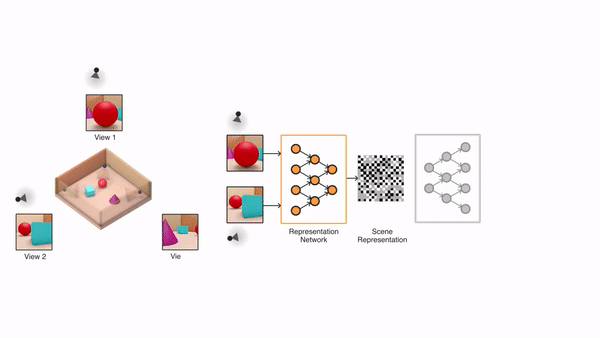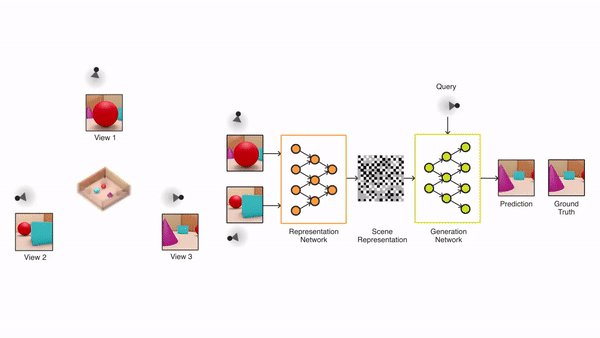
生成网络的任务是从一个之前没有观察到的角度,来预测(也可以叫“想象”)出这个潜在的场景。
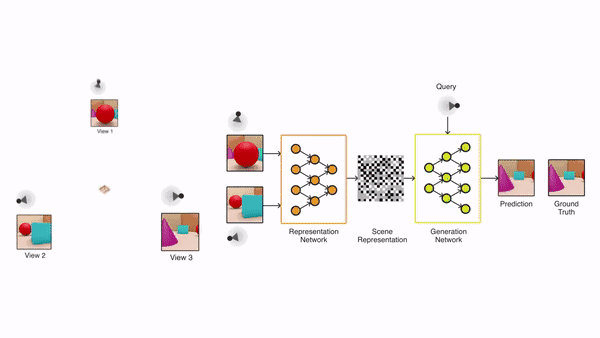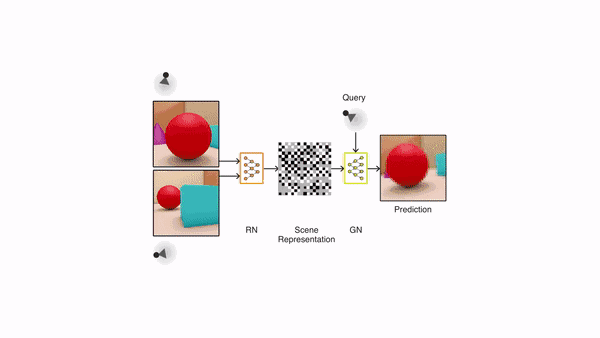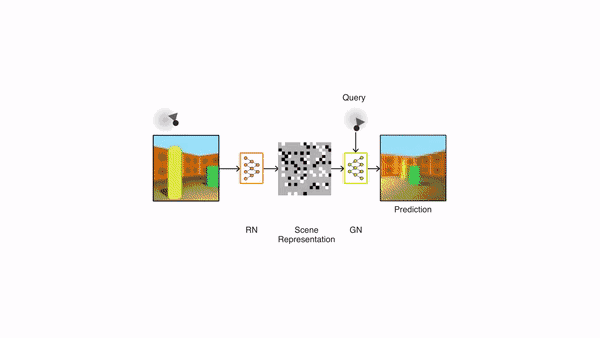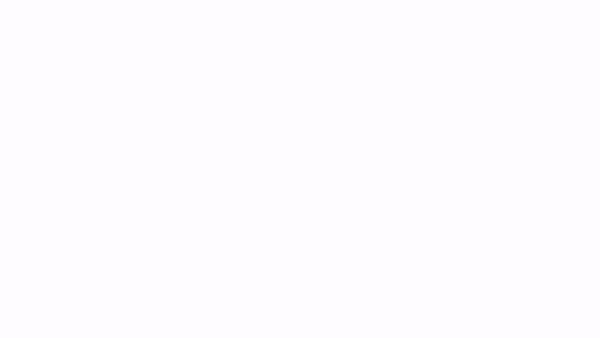
表示网络不知道生成网络将被要求预测哪些视角,因此必须找到尽可能准确描述场景真实布局的有效方法。表示网络能通过简明的分布式表示捕获最重要的元素,例如目标位置、颜色和房间布局。在训练过程中,生成器学习环境中的典型目标、特征、关系和规律。这组共享的「概念」使表示网络能够以高度压缩、抽象的方式来描述场景,让生成网络在必要时填写细节。例如,表示网络将把「蓝色立方体」简洁地表示为一个小的数值集合,生成网络将知道从特定的角度来看,这是如何以像素的形式表现出来的。
四大特性
DeepMind研究人员在程序生成的虚拟3D环境中对GQN做了多次试验,包括多种不同物体,被摆放在不同的位置,并且形状、颜色、材质都不相同,同时还改变了光线方向和遮挡程度。通过在这些环境上进行训练,他们用GQN的表示网络去生成一个从未见过的场景。在实验中人们发现GQN表现出的四个重要特性:
GQN 的生成网络可以从新的视角非常精确地「想象」以前未见过视角下的场景。当给定场景表征和新视角时,它会生成清晰的图像,而不需要预先规定角度、遮挡或照明的规律。因此,生成网络是从数据中学习的近似渲染器(renderer):
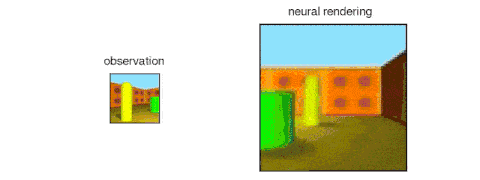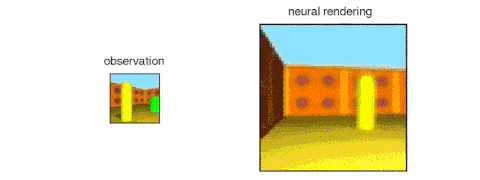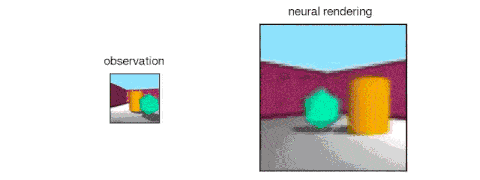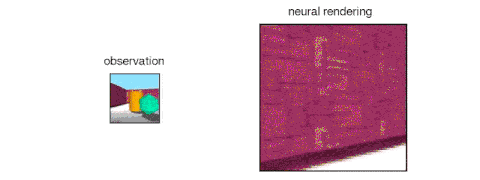
GQN的表示网络可以独自学习算数、定位、分类物体。就算在小型表示上,GQN也能在具体视角上做出非常精准的预测,和现实几乎一模一样。这说明了表示网络观察得非常仔细,例如下面这个由几个方块堆叠起来的场景:
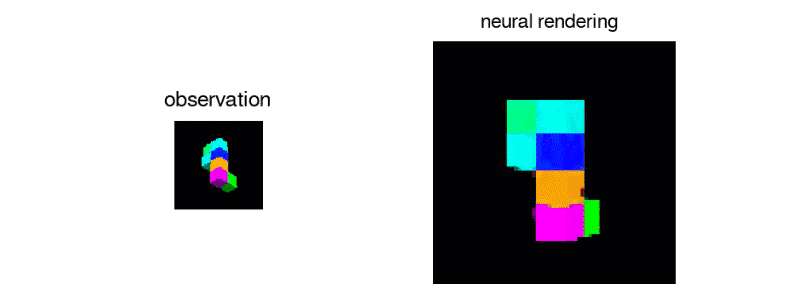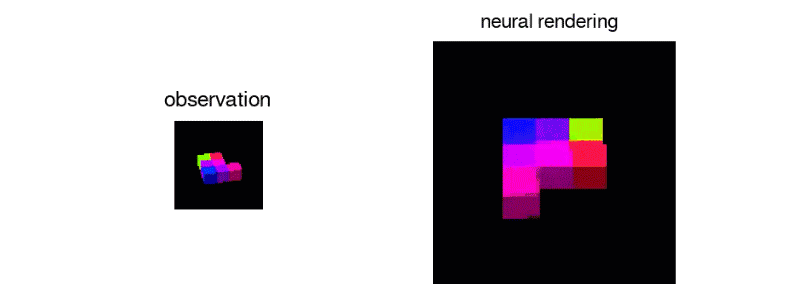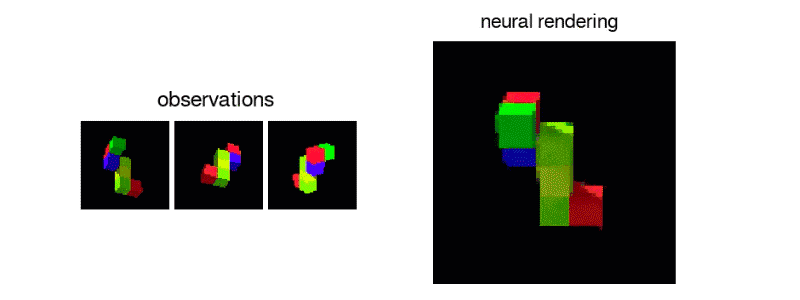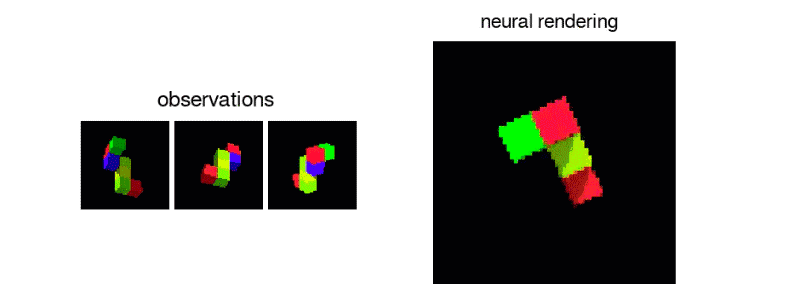
GQN能够表示、衡量和减少不确定性。即便内容不是完全可见,GQN也能应付场景中的不确定性,并将场景中的多个局部视图组合起来,形成一个整体。这事儿挺难,人都不一定能做好。GQN能力如何?见下图所示。有一类是第一人称视角的预测:
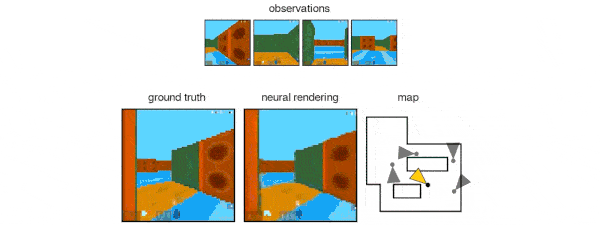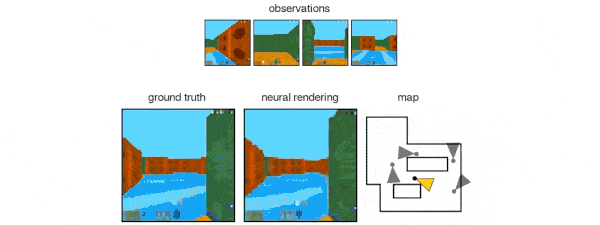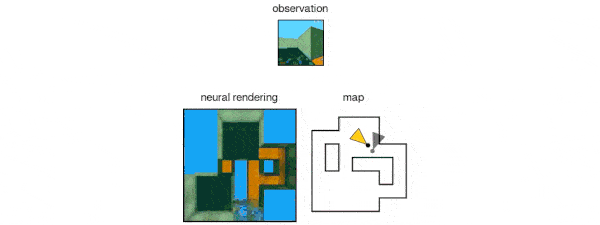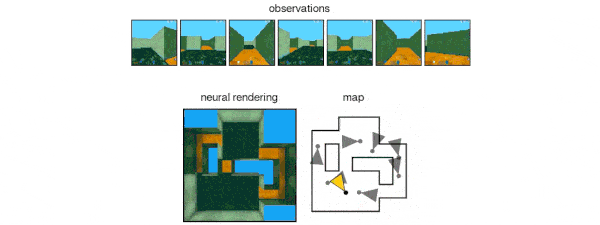
GQN的表示允许稳健的、数据有效(data-efficient)的强化学习。当给定GQN的紧凑表示时,与无模型基线agent相比, state-of-the-art的深度强化学习agent能够以更高的数据效率方式完成任务,如下图所示。对于这些agent,生成网络中编码的信息可以被看作是对环境的“先天”知识:
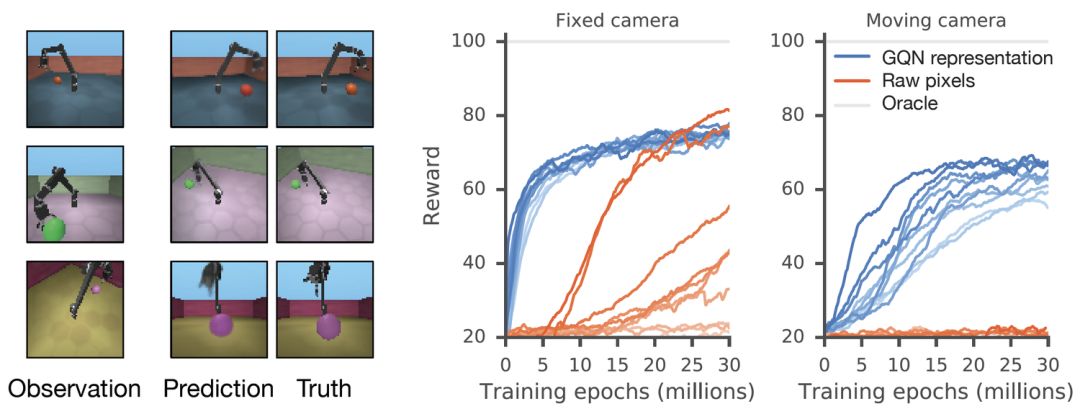
未来研究
GQN 建立在最近大量多视角的几何研究、生成式建模、无监督学习和预测学习的基础上,它展示了一种学习物理场景的紧凑、直观表征的全新方式。重要的是,提出的这种方法不需要特定域的工程以及消耗时间对场景内容打标签,使得同一模型能够应用到大量不同的环境。它也学习了一种强大的神经渲染器,能够产生准确的、全新视角的场景图像。
DeepMind 认为,相比于更多传统的计算机视觉技术,他们的方法还有许多缺陷,目前也只在合成场景下训练工作的。然而,随着新数据资源的产生、硬件能力的发展,DeepMind 希望探索 GQN 框架应用到更高分辨率真实场景图像的研究。未来,探索 GQN 应用到更广泛的场景理解的工作也非常重要,例如通过跨空间和时间的查询来学习物理和移动等常识概念,还有应用到虚拟和增强现实等。
论文原文
原文地址:http://science.sciencemag.org/content/360/6394/1204.full
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
展开全文



