【AlphaGo Zero 核心技术-深度强化学习教程代码实战05】SARSA(λ)算法实现
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天实践五 SARSA(λ)算法实现
在实践四中我们编写了一个简单的个体(Agent)类,并在此基础上实现了SARSA(0)算法。本篇将主要讲解SARSA(λ)算法的实现,由于前向认识的SARSA(λ)算法实际很少用到,我们将只实现基于反向认识的SARSA(λ)算法,本文后续如未特别交代,均指的是基于反向认识的SARSA(λ)。
SARSA(λ)算法的实现
该算法的流程图如下:

其特点是需要额外维护一张E表,来衡量一个Episode内个体早期经过的状态对后续状态行为价值贡献的重要程度。在《强化学习》第五讲中,已经用文字描述详细比较了SARSA(0)和SARSA(λ)之间的区别,我们来看看这些区别是如何反映在代码中的。
我们在上一篇使用的Agent类的基础上作些针对性的修改,主要表现在:添加一个字典成员变量E(也可以将其设为learning方法里的局部变量),支持对E的初始化、查询、更新、重置操作;修改learning方法。至于个体执行策略、执行行为的方法不需更改。完整的代码如下:
#!/home/qiang/PythonEnv/venv/bin/python3.5# -*- coding: utf-8 -*-# An agent powered by Sarsa(lambda) for discrete ovservation # and action spaces# Author: Qiang Ye# Date: July 25, 2017# License: MITfrom random import randomfrom gym import Envimport gymfrom gridworld import *class SarsaLambdaAgent(object):
def __init__(self, env: Env):
self.env = env
self.Q = {} # {s0:[,,,,,,],s1:[]} 数组内元素个数为行为空间大小
self.E = {} # Eligibility Trace
self.state = None
self._init_agent()
return
def _init_agent(self):
self.state = self.env.reset()
s_name = self._name_state(self.state)
self._assert_state_in_QE(s_name, randomized = False)
# using simple decaying epsilon greedy exploration
def _curPolicy(self, s, num_episode, use_epsilon):
epsilon = 1.00 / (num_episode + 1) # 衰减的epsilon-greedy
Q_s = self.Q[s]
rand_value = random()
if use_epsilon and rand_value < epsilon:
return self.env.action_space.sample()
else:
return int(max(Q_s, key=Q_s.get))
# Agent依据当前策略和状态生成下一步与环境交互所要执行的动作
# 该方法并不执行生成的行为
def performPolicy(self, s, num_episode, use_epsilon=True):
return self._curPolicy(s, num_episode, use_epsilon)
def act(self, a): # Agent执行动作a
return self.env.step(a)
def learning(self, lambda_, gamma, alpha, max_episode_num):
total_time = 0
time_in_episode = 0
num_episode = 1
while num_episode <= max_episode_num:
self._resetEValue()
s0 = self._name_state(self.env.reset())
a0 = self.performPolicy(s0, num_episode)
# self.env.render()
time_in_episode = 0
is_done = False
while not is_done:
s1, r1, is_done, info = self.act(a0)
# self.env.render()
s1 = self._name_state(s1)
self._assert_state_in_QE(s1, randomized = True)
a1= self.performPolicy(s1, num_episode)
q = self._get_(self.Q, s0, a0)
q_prime = self._get_(self.Q, s1, a1)
delta = r1 + gamma * q_prime - q
e = self._get_(self.E, s0,a0)
e = e + 1
self._set_(self.E, s0, a0, e) # set E before update E
state_action_list = list(zip(self.E.keys(),self.E.values()))
for s, a_es in state_action_list:
for a in range(self.env.action_space.n):
e_value = a_es[a]
old_q = self._get_(self.Q, s, a)
new_q = old_q + alpha * delta * e_value
new_e = gamma * lambda_ * e_value
self._set_(self.Q, s, a, new_q)
self._set_(self.E, s, a, new_e)
if num_episode == max_episode_num:
print("t:{0:>2}: s:{1}, a:{2:10}, s1:{3}".
format(time_in_episode, s0, a0, s1))
s0, a0 = s1, a1
time_in_episode += 1
print("Episode {0} takes {1} steps.".format(
num_episode, time_in_episode))
total_time += time_in_episode
num_episode += 1
return
def _is_state_in_Q(self, s):
return self.Q.get(s) is not None
def _init_state_value(self, s_name, randomized = True):
if not self._is_state_in_Q(s_name):
self.Q[s_name], self.E[s_name] = {},{}
for action in range(self.env.action_space.n):
default_v = random() / 10 if randomized is True else 0.0
self.Q[s_name][action] = default_v
self.E[s_name][action] = 0.0
def _assert_state_in_QE(self, s, randomized=True):
if not self._is_state_in_Q(s):
self._init_state_value(s, randomized)
def _name_state(self, state):
'''给个体的一个观测(状态)生成一个不重复的字符串作为Q、E字典里的键 '''
return str(state)
def _get_(self, QorE, s, a):
self._assert_state_in_QE(s, randomized=True)
return QorE[s][a]
def _set_(self, QorE, s, a, value):
self._assert_state_in_QE(s, randomized=True)
QorE[s][a] = value
def _resetEValue(self):
for value_dic in self.E.values():
for action in range(self.env.action_space.n):
value_dic[action] = 0.00def main():
# env = gym.make("WindyGridWorld-v0")
env = WindyGridWorld()
# directory = ""
# env = gym.wrappers.Monitor(env, directory, force=True)
agent = SarsaLambdaAgent(env)
print("Learning...")
agent.learning(lambda_ = 0.01,
gamma = 0.9,
alpha = 0.1,
max_episode_num = 1000)if __name__ == "__main__":
main() 这次我们使用的是有风格子世界,”格子世界“下方的数字表明该列格子上存在的风力等级,具体对个体状态的影响表现为:个体在打算离开某位置时将受到该位置风力的影响继而沿着风向偏离原行为指向位置的格子数。
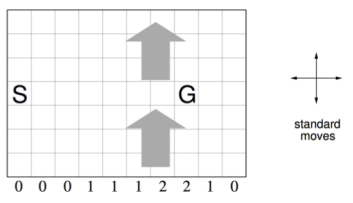
我们默认设置个体只能采取标准移动方式,也就是只能沿着水平或垂直方向移动一格,而不能斜向移动。个体在这样的环境下其最优路径如下图所示,一共15步。
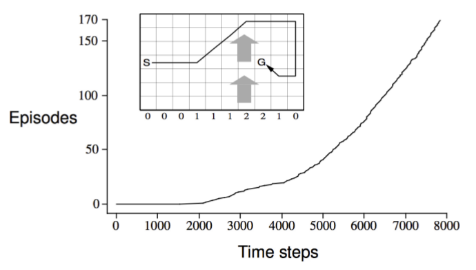
程序实际运行效果也是这样,在早期由于个体对环境中的风向一无所知,所以经常被迫吹至世界上方的边界位置,要花费很长时间才能到达目标位置:

不过当个体尝试过足够多的次数后,便找到最优路径了,同时随着衰减的epsilon逐渐减小至0,个体采取随机行为的可能性也逼近0,策略将逐渐收敛值最优策略。下面的视频展示了最优路径:

读者可以通过修改环境设置,将目标位置即时奖励设为1,所有其它位置的即时奖励设为0,初始化QE时也设为0,在个体第一个Episode的每一步移动时,查看两种算法:SARSA(0)和SARSA(λ)下Q、E值的区别,加深对这两种算法的理解。关于对Agent类的完善由于与本篇内容关系不大,留到后续需要的时候再介绍。
理想与现实之差——格子世界毕竟是格子世界
SARSA(λ)算法就讲到这里了,基本上强化学习基础理论部分最最重要的算法已经介绍完毕。对于格子世界来说,个体的观测空间是离散的,相当于是一维的,行为空间也是一维的。我们只需针对状态维护一张表来存储每一个观测(状态)对应的行为价值(Q值)就可以很方便的对其进行查询、更新。这种做法同样适用用于多维离散观测空间。但是当观测空间的某一个维度不再是离散变量而是连续变量时,情况就不同了。像gym提供的许多经典环境其观测空间都是连续的多维空间,比如我们之前提到的“小车爬山”,它的观测空间的二维都是连续的,其中之一是小车距离目标位置的水平距离,另一个维度是小车的速度。真实世界大多数观测也是连续。因此,在这两讲介绍的代码不能直接用在连续多维观测空间中,对于多维但是每个维度都是离散值的观测,我们可以将其转化为1维就可以沿用这些代码,具体怎么修改留给读者自己思考。但是当观测空间是多维并且其中某一(些)维度是连续变量时,问题怎么解决呢?
一个可能思路是把连续变量近似转化为离散变量,比如在小车爬山问题中,把小车速度落在某个小区间内看成是一个离散的观测,也就是微分的思想。不过这种近似的表示方法有不少缺点:如果我们需要更高的精确度,那么我们需要的描述该空间的离散值就越多,代表着状态数越多。这样会增加存储Q值的表的大小,如果问题非常复杂,则有可能使得该表异常的庞大,同时降低算法的性能,甚至问题无法得到解决。
对于这种具备连续变化特点的某一空间维度,我们可以另辟蹊径,即将Q值设计成为该连续变化的量的函数,如果我们找到这样的一个函数,那么该维度每一个确定的值都对应一个确定的Q值,就不需要再依赖查表(table lookup)的操作了,这就是《强化学习》 第六讲“价值函数的近似表示”的主要内容。
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



