最新《深度神经网络自监督视觉特征学习综述》论文(附24页全文下载)
【导读】为了更好的模型性能,大规模标注数据被广泛的应用于神经网络的训练过程中,以便在计算机视觉应用中获得更好的视觉特征。为了避免搜集、标注大规模数据集时的额外开销,自监督学习方法被提出来,帮助模型从大规模无标签数据中获得更加通用的图像于视频特征。这篇文章提供了一个基于深度学习自监督方法的通用视觉特征学习方法,帮助研究人员了解该领域最新进展。
介绍:
由于多级视觉特征的广泛应用价值,深度神经网络已经在许多计算机视觉任务中,作为一种基础结构而存在,例如目标检测、语义分割、图像描述等。从大规模数据集(如ImageNet等)中训练得出的模型,被广泛的作为预训练模型使用,进而根据特定任务,进行模型fine-tuned。导致这一现象的原因有两个:1、从大规模数据集中获取的参数是为模型提供了一个非常高质量的起始点,因而,网络可以更快的收敛;2、网络已经从大规模数据集上学习到了层次特征,特别是当特定任务数据集过小,或者是训练标签缺乏的情况下,可以有效减少其他任务训练过程中的过拟合问题。
深度卷积神经网络的性能依赖于学习能力与训练数据,因为越来越多的网络架构(如AlexNet、VGG、GoogleNet、ResNet与DenseNet)与训练数据集(如ImageNet、OpenImage等)被开发出来。随之而来的是卷积网络性能的大幅度提升。
但是,数据集的收集与标注是非常耗时且昂贵的。作为一个广泛应用的数据集,ImageNet包含13亿标注图片,涵盖1000类标签,均为人工标注。与图像数据相比,图像数据集的标注过程,更加的昂贵。用于人类动作识别任务的Kinetics数据集中,包含了50000条10秒左右的视频,涵盖600个类别标签。这一数据的标注,花费了许多亚马逊Turk工人非常多的时间。
许多自监督方法被提出来,以避免耗时耗力的数据标注过程。为了从无标签数据中学习视觉特征,一中流行的方案是根据网络要解决的多种pretext任务,并通过训练pretext任务的过程,来学习各类特征。如colorizing grayscale images,image inpainting,image jigsaw puzzle等。pretext任务共享了2个通用特点:图像与视频特征通过卷积神经网络捕获特征,以解决pretext任务;2、在这一过程中,会自动生成图像或视频的伪标签。
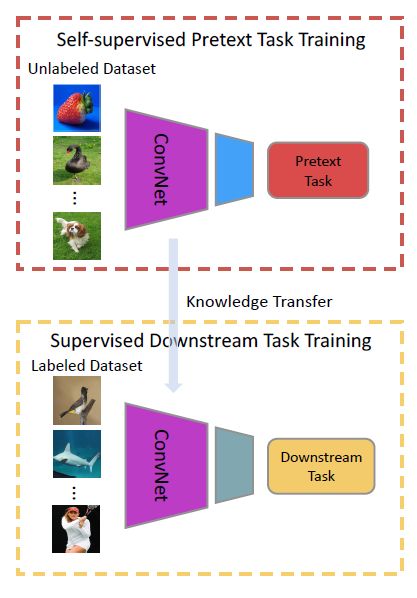
上图中是自监督学习的通用架构,在自监督寻来你阶段,预定义的pretext任务被设计为基于卷积网络来解决,进而基于数据某些数据来自动生成伪标签。在自监督训练结束后,视觉特征将被迁移至下游任务中,来帮助提升任务性能,以及解决过拟合问题。
本文几点贡献:
据我们所知,这一第一篇关于自监督视觉特征学习的综述,有利于帮助研究者快速了解这一领域。
深度介绍了自监督学习方法与数据集的近期发展。
针对已有方法的性能量化分析与对比。
自监督学习未来的发展方向。
【自监督视觉特征学习方法最新综述论文下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“SLVF” 就可以获取自监督视觉特征学习综述论文的下载链接~
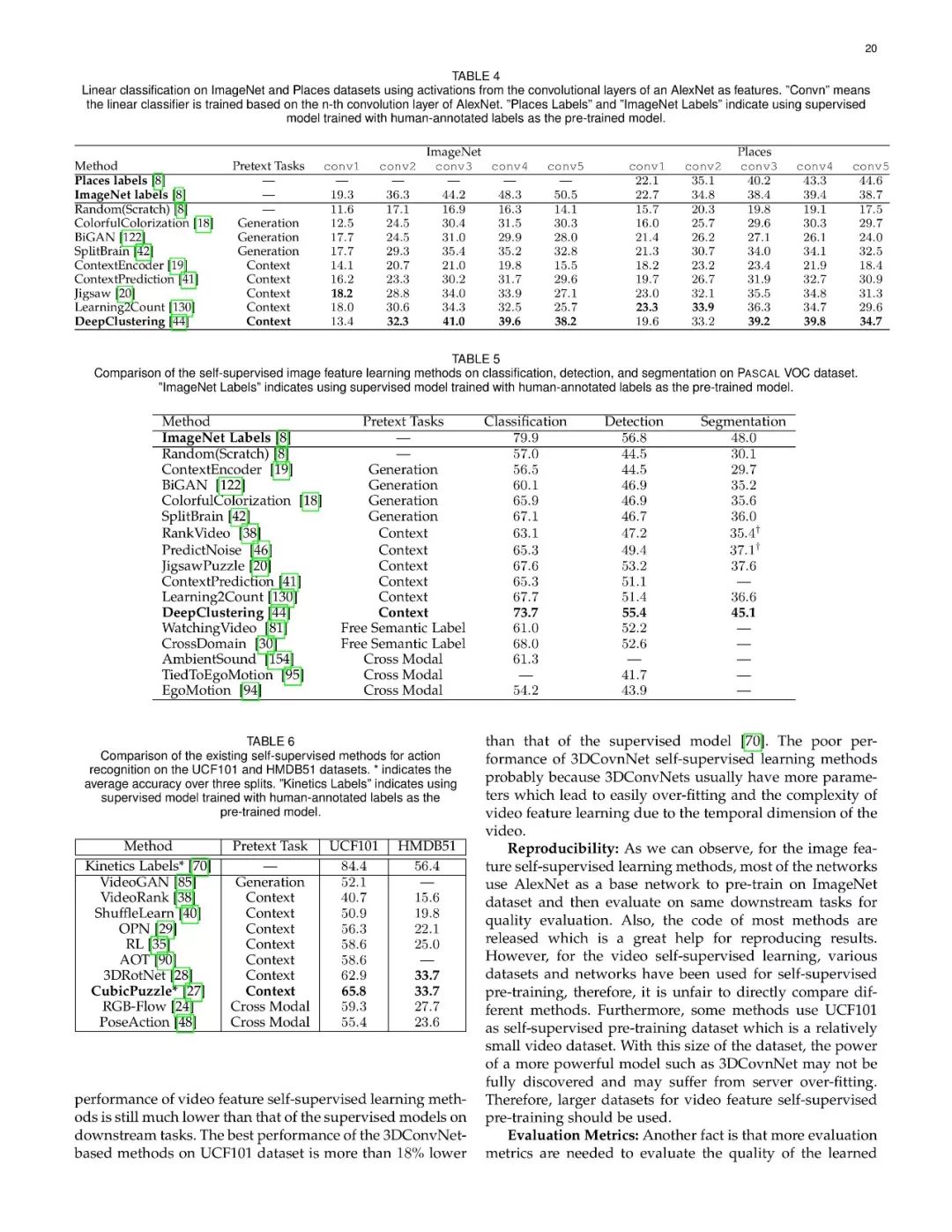
附论文全文:























-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!480+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



