DeepMind Nando(原牛津大学教授)强化学习最新进展,含图文、公式和代码,附102页PPT下载
【导读】在DeepMing任职的Nando de Freitas(原牛津大学教授)在KHIPU 2019上做了关于强化学习(RL)的教程,102页ppt。涵盖了强化学习RL基础概念、策略梯度、动态规划以及D4PG、R2D3等RL算法,并介绍了RL的应用。
在KHIPU 2019(Latin American Meeting In Artificial Intelligence)上,在DeepMing任职的Nando de Freitas做了教程《Reinforcement Learning》,用图文、公式等详细地介绍了强化学习的基础和一些进阶算法。
Nando de Freitas简介
Nando出生在津巴布韦,患有疟疾。他是莫坎比克战争的难民。他的父母借钱从贪官给他买一本护照,让他能够生活在葡萄牙马德拉的一个火山岩小屋,没有水和电,父母忙着偿还债务也不再身边,这种情况一直持续到欧盟到达那里。

他在威特沃特斯兰德大学(University of the Witwatersrand)获得了电气工程理学学士学位和控制理学硕士学位,后幸获得剑桥大学三一学院(Trinity College, Cambridge University)神经网络贝叶斯方法博士学位,这要归功于慈善人士提供的奖学金。
他在加州大学伯克利分校(UC Berkeley)获得了人工智能的博士后学位,并于2001年成为加拿大不列颠哥伦比亚大学(University of British Columbia)的教授,随后在2013年成为英国牛津大学(University of Oxford)的教授。2017年,他以首席科学家的身份加入了DeepMind的全职工作,帮助解决智能问题的愿景,让未来几代人能够过上更好的生活。Nando也是加拿大高级研究所的高级研究员,并获得了一些学术奖项。
主页介绍:
https://khipu.ai/03_nando_de_freitas/
《Reinforcement Learning》教程的内容
强化学习概念
策略梯度
动态规划
深度Q网络
分布式强化学习
D4PG(Distributed Distributional Deep Deterministic Policy Gradients)
PPO(Proximal Policy Optimization)和MPO(Maximum aposteriori Policy Optimisation)
R2D3(Recurrent Replay Distributed DQN from Demonstrations)
强化学习应用:
AlphaX
Batch强化学习
-
后台回复“KHIPURL” 就可以获取完整教程PPT的下载链接~
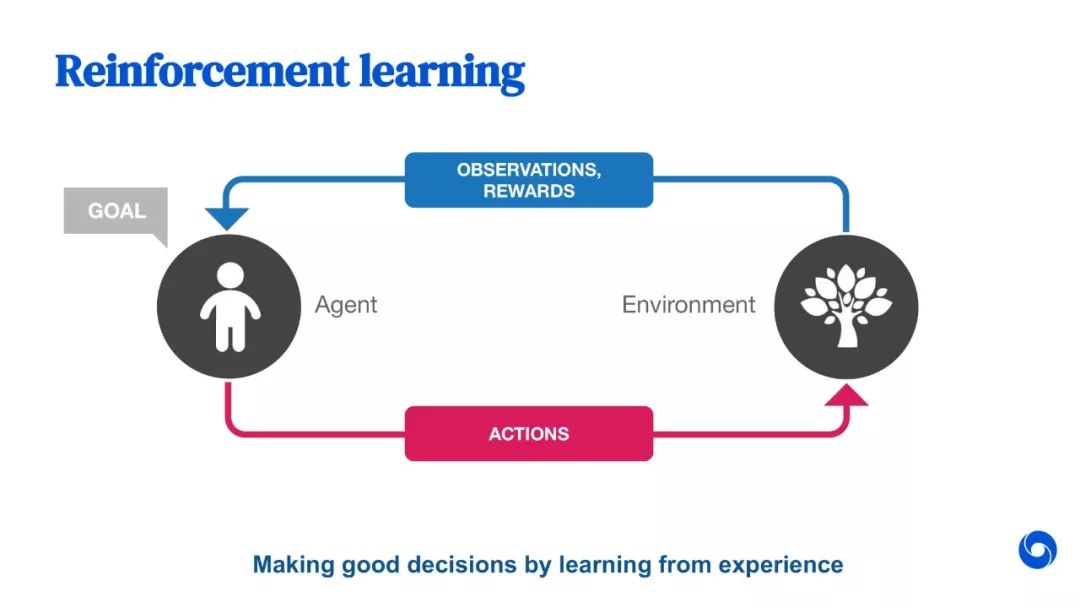
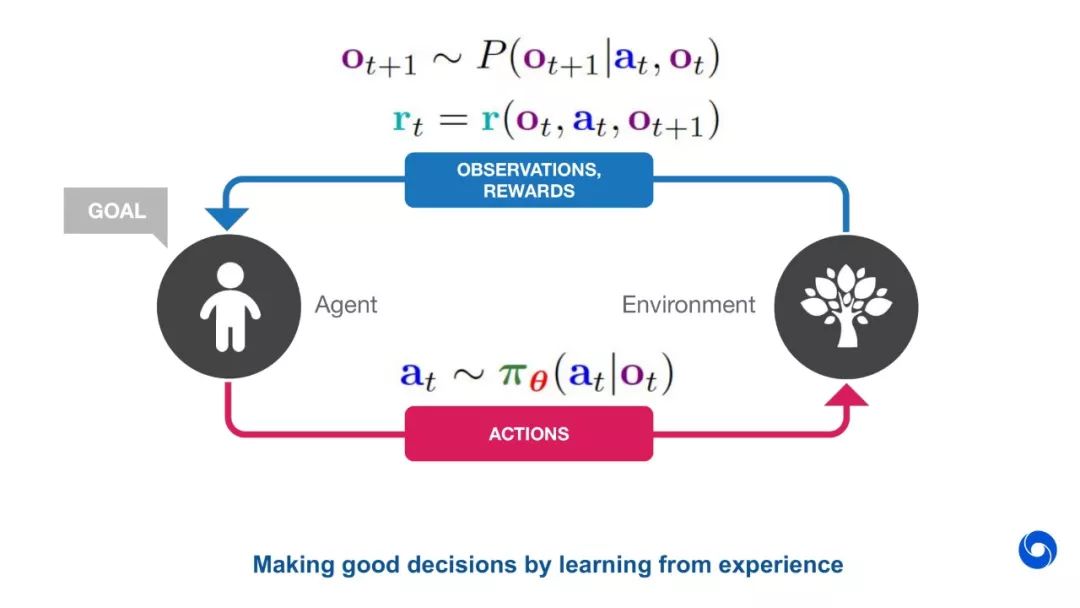
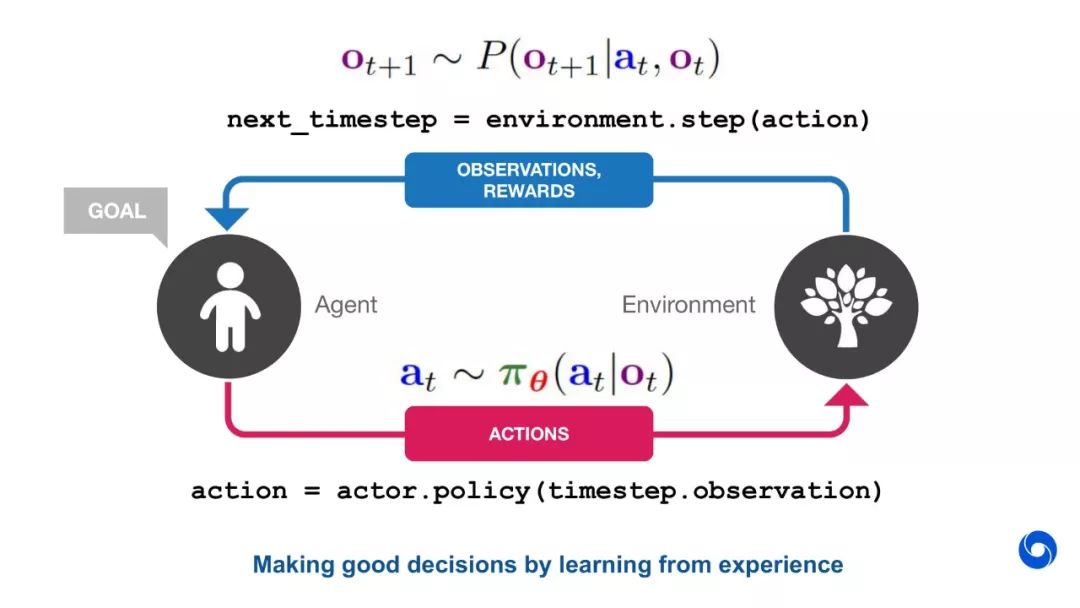
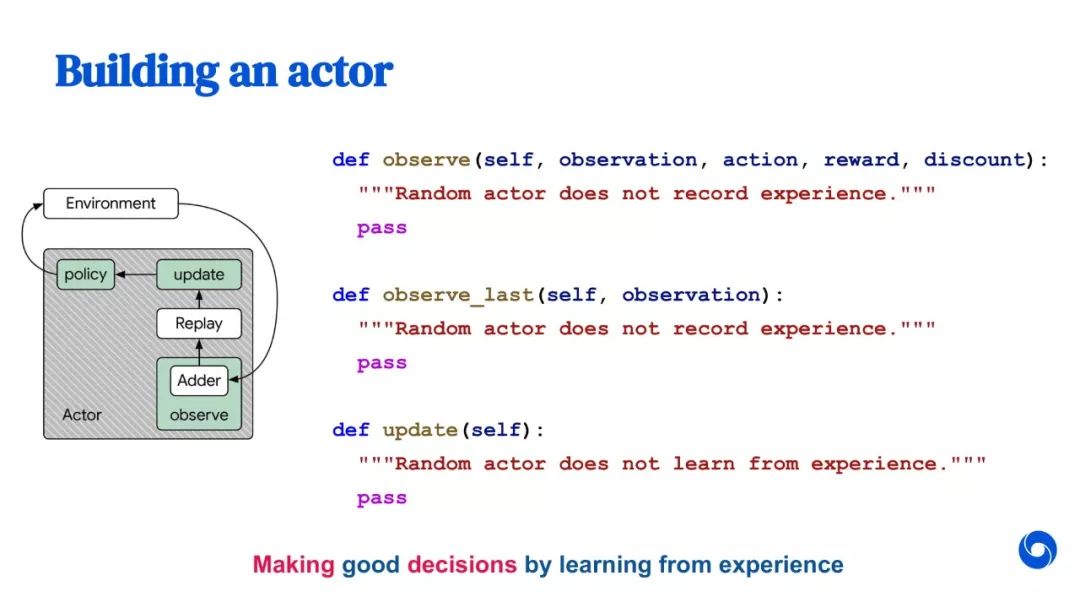
教程部分截图如下所示:










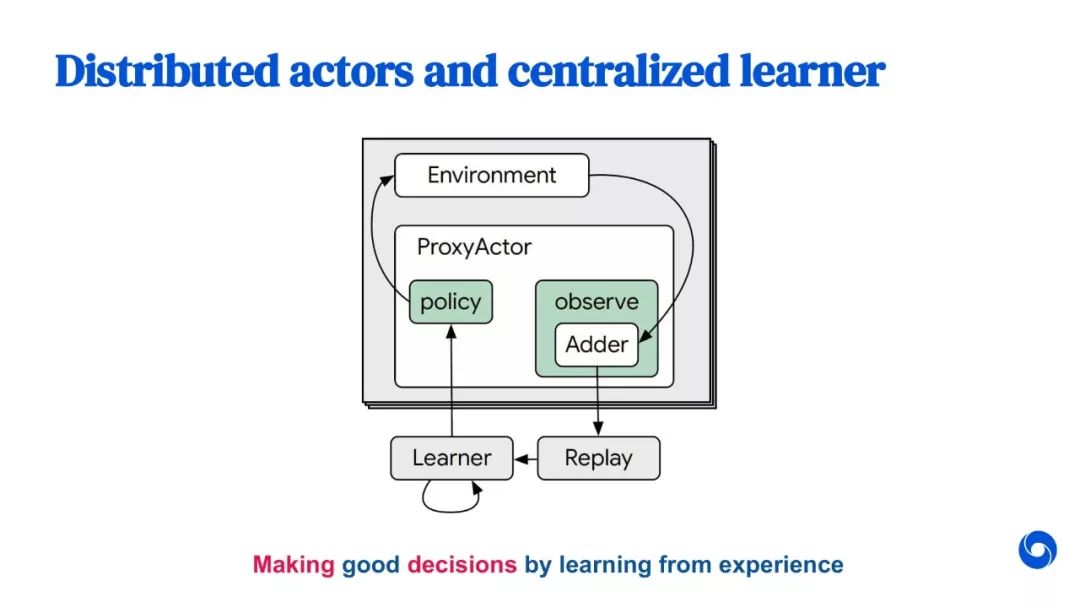
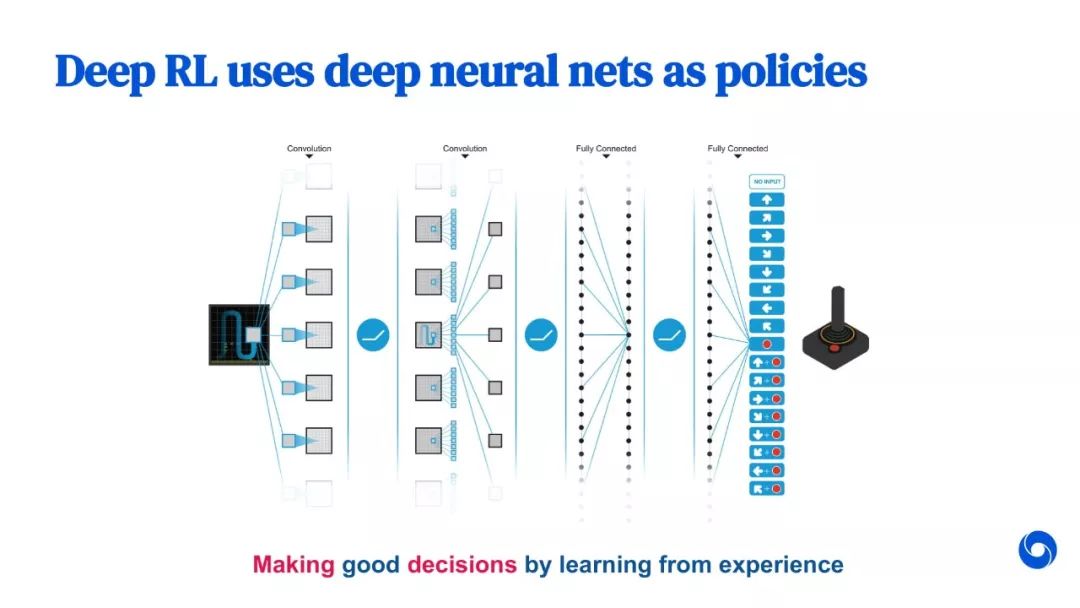




参考链接:
https://khipu.ai/program/
https://khipu.ai/03_nando_de_freitas/
https://drive.google.com/file/d/1kPc3fyOzt0I3Sdwt5EgHH5Bsn1Ng-h11/view?usp=sharing
更多关于“强化学习”的论文知识资料,请登录专知网站www.zhuanzhi.ai查看,或者点击“阅读原文”查看:
https://www.zhuanzhi.ai/topic/2001320766352755/awesome



展开全文



