【干货】对抗自编码器PyTorch手把手实战系列——对抗自编码器学习笔迹风格
即使是非计算机行业, 大家也知道很多有名的神经网络结构, 比如CNN在处理图像上非常厉害, RNN能够建模序列数据. 然而CNN, RNN之类的神经网络结构本身, 并不能用于执行比如图像的内容和风格分离, 生成一个逼真的图片, 用少量的label信息来分类图像, 或者做数据压缩等任务. 因为上述几个任务, 都需要特殊的网络结构和训练算法 .
有没有一个网络结构, 能够把上述任务全搞定呢? 显然是有的, 那就是对抗自编码器Adversarial Autoencoder(AAE) . 在本文中, 我们将构建一个AAE, 从MNIST数据集中学习里面的笔迹, 然后给定任意的内容, 去生成这个字体的图像。
本系列文章, 专知小组成员Huaiwen一共分成四篇讲解,这是第三篇:
自编码器实例应用: 被玩坏的神经画风迁移(没办法太典型了)
自编码器实例应用: 用极少label分类MNIST
每一个人都有自己独特的笔迹风格(或者说字体), 我们写字时的力度, 笔锋, 甚至我们遣词造句的习惯都会反映在字体上. 因此伪造一个人的字体是一个很难的事情.
本文, 我们尝试从MNIST数据集中学习里面的笔迹, 然后给定任意的内容, 去生成这个字体的图像.
首先让我们先搞清楚一张笔迹的字体和内容分别是什么:
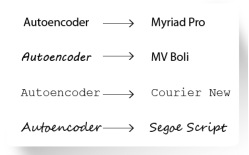
上图中的所有的笔迹, 内容都是Autoencoder, 但是字体多变, 比如: Segoe script, Courier New等等.
将字体和内容分割出来, 是表示学习的一个重要内容。
我们用的Adversarial Autoencoder一直都是以无监督的方式训练的. 在本文中, 为了让AAE专注于学习字体的表示, 而减轻内容的学习, 我们将图片中的标签加入进去.
我们设计了如下的AAE架构:
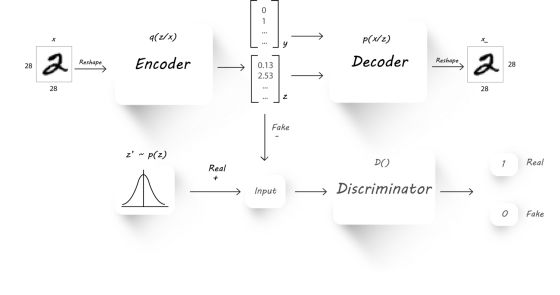
注意, 除了直接用隐层编码之外, 我们将标签信息 也加入了进来, 在这里是一个one-hot向量, 因为是MNIST数据集, 所以是十维的.
训练上述模型, 需要在优化重建误差的时候稍稍做一些修改:
• 将图像输入到Encoder, 得到隐变量
• 将隐变量和标签 组合成一个新变量, 然后输入到Decoder中
• 这样, Encoder专心于学习字体, Decoder会根据学习出的字体表示加上笔迹内容 去生成笔迹
其他部分跟上一篇文章一样. 唯一的不同是Decoder的输入变成下图了:
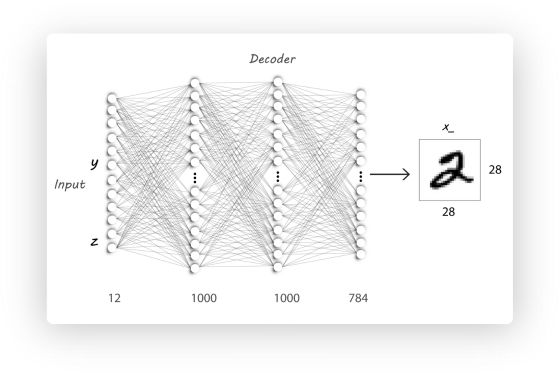
基于上一篇文章, 我们要改的地方有两个:
Decoder的输入维度扩充n_labels:
# p(x|z)
class P_net(nn.Module):
def __init__(self,X_dim,N,z_dim,n_labels):
super(P_net, self).__init__()
self.lin1 = nn.Linear(z_dim + n_labels, N)
self.lin2 = nn.Linear(N, N)
self.lin3 = nn.Linear(N, X_dim)
def forward(self, x):
x = F.dropout(self.lin1(x), p=0.25, training=self.training)
x = F.relu(x)
x = F.dropout(self.lin2(x), p=0.25, training=self.training)
x = self.lin3(x)
return F.sigmoid(x)
训练过程要把labels加进去
EPS = 1e-15
# 学习率
gen_lr = 0.0001
reg_lr = 0.00005
# 隐变量的维度
z_red_dims = 15
# 类别数
n_labels = 10
# encoder
Q = Q_net(784, 1000, z_red_dims).cuda()
# decoder
P = P_net(784, 1000, z_red_dims, n_labels).cuda()
# discriminator
D_gauss = D_net_gauss(500, z_red_dims).cuda()
# encode/decode 优化器
optim_P = torch.optim.Adam(P.parameters(), lr=gen_lr)
optim_Q_enc = torch.optim.Adam(Q.parameters(), lr=gen_lr)
# GAN部分优化器
optim_Q_gen = torch.optim.Adam(Q.parameters(), lr=reg_lr)
optim_D = torch.optim.Adam(D_gauss.parameters(), lr=reg_lr)
# 数据迭代器
data_iter = iter(data_loader)
iter_per_epoch = len(data_loader)
total_step = 50000
for step in range(total_step):
if (step + 1) % iter_per_epoch == 0:
data_iter = iter(data_loader)
# 从MNSIT数据集中拿样本
images, labels = next(data_iter)
images = to_var(images.view(images.size(0), -1))
y = torch.zeros(batch_size, n_labels).scatter_(1, labels.unsqueeze(1), 1)
y = to_var(y)
# 把这三个模型的累积梯度清空
P.zero_grad()
Q.zero_grad()
D_gauss.zero_grad()
################ Autoencoder部分 ######################
# encoder 编码x, 生成z
z_sample = Q(images)
# decoder 解码z和y, 生成x'
X_sample = P(torch.cat((z_sample, y), dim=1))
# 这里计算下autoencoder 的重建误差|x' - x|
recon_loss = F.binary_cross_entropy(X_sample + EPS, images + EPS)
# 优化autoencoder
recon_loss.backward()
optim_P.step()
optim_Q_enc.step()
################ GAN 部分 #############################
# 从正太分布中, 采样real gauss(真-高斯分布样本点)
z_real_gauss = V(randn(images.size()[0], z_red_dims) * 5.).cuda()
# 判别器判别一下真的样本, 得到loss
D_real_gauss = D_gauss(z_real_gauss)
# 用encoder 生成假样本
Q.eval() # 切到测试形态, 这时候, Q(即encoder)不参与优化
z_fake_gauss = Q(images)
# 用判别器判别假样本, 得到loss
D_fake_gauss = D_gauss(z_fake_gauss)
# 判别器总误差
D_loss = -mean(log(D_real_gauss + EPS) + log(1 - D_fake_gauss + EPS))
# 优化判别器
D_loss.backward()
optim_D.step()
# encoder充当生成器
Q.train() # 切换训练形态, Q(即encoder)参与优化
z_fake_gauss = Q(images)
D_fake_gauss = D_gauss(z_fake_gauss)
G_loss = -mean(log(D_fake_gauss + EPS))
G_loss.backward()
# 仅优化Q
optim_Q_gen.step()
# 训练结束后, 存一下encoder的参数
torch.save(Q.state_dict(), 'Q_encoder_weights.pt')
训练完之后, 我们可以随机一个, 让后让 从0到9变化, 可以生成如下的图:

横轴是 从0到9, 纵轴是一个内容的不同字体, 是不是很有意思, 自己动手试一下吧.
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知
展开全文



