【最新PyTorch0.4.0教程01】PyTorch的动态计算图深入浅出
【导读】PyTorch在GitHub发布0.4.0版本,专知成员Huaiwen详细讲解了PyTorch新版本的变动信息,也计划更新一系列新版PyTorch简单上手, 今天推出第一篇《PyTorch的动态计算图深入浅出》,希望大家持续关注。
专知成员Huaiwen以前推出一系列PyTorch教程:
不只是支持Windows, PyTorch 0.4新版本变动详解与升级指南
PyTorch的动态计算图深入浅出
PyTorch 构建神经网络的机制非常独特,官方称之为 Tape-based,直译为:基于磁带的。
所谓基于磁带,是指PyTorch构建神经网络,就像在磁带上记录音乐,而对神经网络进行求导,就像磁带的倒带过程。直白的说, PyTorch是执行到了这句代码, 才开始构建这句代码所描述的网络节点, 然后把这一节点挂在计算图上, 而反向求导的时候, 根据网络节点之间的联系,比如torch.add,从后往前反向传播求导。
目前大多数的框架,如Tensorflow、Caffe都采用静态构建方式。这意味着用户需要先构建神经网络结构,然后,在给定的结构上填入数据,再进行一次又一次的运行。 这种方式的好处是框架能够对预先定义的网络进行多种优化处理,从而运行的更高效。但缺点也非常明显,即不够灵活,而且被优化后的网络,对用户不友好,调试时难以轻松知道程序的状态, 而且一旦用户想要根据计算的状态,动态的修改神经网络结构,那么实现起来会非常困难。
PyTorch可以让用户在动态改变神经网络时,不产生任何滞后和开销。这是因为, 当用户在代码里做抉择的时候, 比如if, for, while 等等,这些控制语句的各种情况里写的代码, 还没开始构建成网络节点呢。这也是动态计算图的灵活所在,它直观, 精简, 极度灵活。 当然,缺点也非常明显,那就是运行效率和开销。
当你需要对构建网络的那几毫秒锱铢必较的时候,显然是没有静态图那么高效的。 这也决定了PyTorch这一工具的定位: 帮助科研人员和工程师, 快速探索和调整模型, 快速构建实验 。可以说动态计算图, 比如PyTorch更适合从0到1的创新工作, 而静态图Tensorflow,更适合已经有了模型, 我们要运用到某些高强度的训练和测试的应用环境下。
1. 下面我们来深入理解PyTorch的Tape-based神经网络构建。
在PyTorch中构建动态计算图, 其实是一个隐式的操作。
import torch
........
........
# 只要将Tensor类的requires_grad设成True
# 就会为这些节点构建计算图
x = torch.tensor(data_x, requires_grad=True)
W_x = torch.tensor(data_wx, requires_grad=True)
h = torch.tensor(data_h, requires_grad=True)
W_h = torch.tensor(data_wh, requires_grad=True)
i2h = torch.mm(W_x, x.t())
h2h = torch.mm(W_h, h.t())
next_h = h2h + i2h
next_next_h = next_h.tanh()
next_next_h.backward()
上述代码运行到第16行后, 构建了一个如下的计算图:
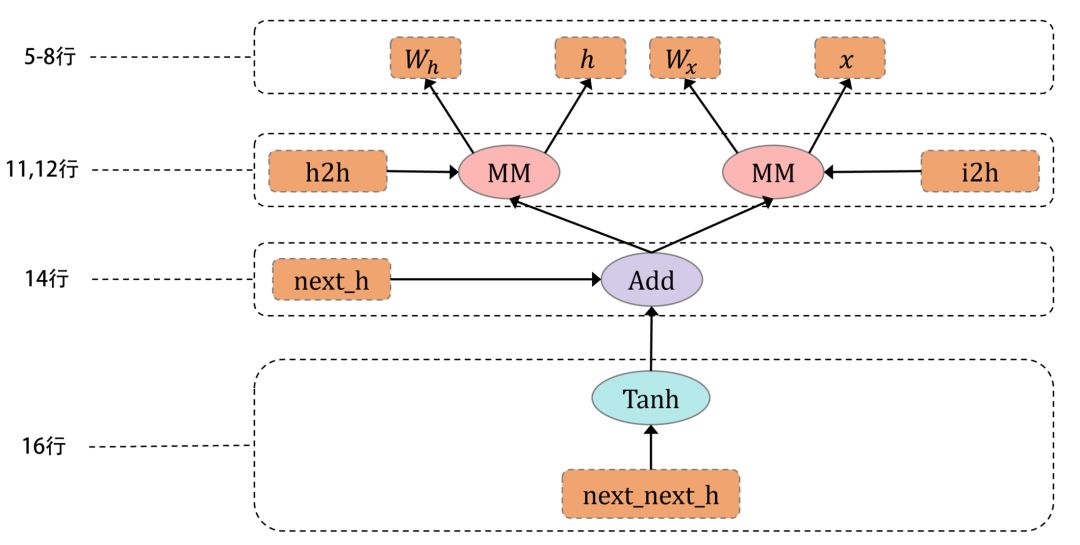
即:
数据和图的构建是协同的, 节点带着数据往前走。(使用静态图,需要先构建图再填数据)
当运行完前8行, 就构建完了W_h, h, W_x, x ,如此往下。
当运行完11,12行, 此时内存中有两个计算图, 左边部分和右边部分。
只有运行到该行代码, 才开始解析和构建, 如上图:当运行完第12行, 14,16行的计算图还没有构建,你有充足的灵活性去进行流程控制(使用静态图,当数据流入第12行,很难再去改变14,16行的节点,因为它们已经构建完了)。
相信,你已经感受到了动态图的魅力。
2. PyTorch怎么根据计算图怎么反向传播的呢?
上图中第19行代码, 在做什么?
这涉及到了 PyTorch怎么构建计算图。
Tensor 对象, 将谁创建了我, 记在它的grad_fn属性上。
比如 :
>>> next_next_h.grad_fn
<TanhBackward object at 0x000002613A402898>
>>> # 一个位于0x000002613A402898 Tanh 创建了next_next_h
>>> # 以此类推
>>> next_h.grad_fn
<AddBackward1 object at 0x000002613A4028D0>
>>> h2h.grad_fn
<MmBackward object at 0x000002613A402860>
>>> i2h.grad_fn
<MmBackward object at 0x000002613A402898>
>>> W_h.grad_fn # 没有输出, 因为它是有用户创建的,
>>> W_h.grad_fn == None
True
>>> x.grad_fn == None
True
这些个 TanhBackward, AddBackward1 是由torch.autograd.Function包下的函数, 在上图中, 可以理解成是椭圆形的节点。显然,Tensor是其中的矩形节点
PyTorch中, 将用户创建的Tensor称之为叶子节点, 由叶子节点,加减乘除出来的Tensor成为非叶子节点, 调用非叶子节点的backward函数, 就会沿着非叶子节点,一路回溯到叶子节点。
这样就很清晰了。 我们可以根据上述代码, 推测出next_next_h.backward()的反向传播路线:
next_next_h --> TanhBackward next_h.tanh()
--> AddBackward1 h2h + i2h
--> MmBackward h2h = torch.mm(W_h, h.t())
--> None W_h
--> TBackward h.t()
--> None h
--> MmBackward i2h = torch.mm(W_x, x.t())
--> None W_x
--> TBackward x.t()
--> None t
我们也可以使用grad_fn对象的next_functions来验证自己的推测:
>>> next_next_h.grad_fn.next_functions
((<AddBackward1 object at 0x000002613A402860>, 0),)
>>> next_next_h.grad_fn.next_functions[0][0].next_functions
((<MmBackward object at 0x000002613A402940>, 0),
(<MmBackward object at 0x000002613A402898>, 0))
>>> ... # 读者可以自行验证
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



