图像分类入门 2-图像分类的基本方法
传统的图像分类方法
一般来说,图像分类通过手工特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法。词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为底层特征抽取、特征编码、分类器设计三个过程。
模型简介
图像识别领域大量的研究成果都是建立在PASCAL VOC、ImageNet等公开的数据集上,很多图像识别算法通常在这些数据集上进行测试和比较。PASCAL VOC是2005年发起的一个视觉挑战赛,ImageNet是2010年发起的大规模视觉识别竞赛(ILSVRC)的数据集,本节中我们基于这些竞赛介绍图像分类模型。
词袋模型(Bag-of-Words)
词袋模型(Bag-of- Words)最初产生于自然语言 处理领域,通过建模文档中单词出现的频率来对文 档进行描述与表达.Csurka等人于2004年首次 将词包的概念引入计算机视觉领域,由此开始大量 的研究工作集中于词包模型的研究。在2012年之前,词袋模型是VOC竞赛 中物体分类算法的基本框架,几乎所有的参赛算法 都是基于词袋模型。通常完整建立图像识别模型一般包括底层特征提取、特征编码、空间约束、分类器设计、模型融合等几个阶段。
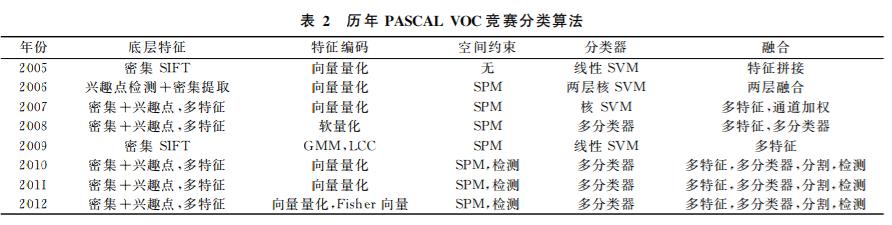
- 底层特征提取: 底层特征提取是物体分类框架中的第一步,底层特征提取方式有两种:一种是基于兴趣点检测,另一种是采用密集提取的方式。
- 兴趣点检测算法通过某种准则选择具有明确定义的、局部纹理特征比较明显的像素点、边缘、角点、区块等,并且通常能够获得一定的几何不变性,从而可以在较小的开销下得到更有意义的表达,最常用的兴趣点检测算子有Harris角点检测子、FAST(Features from Accelerated Segment Test)算子、 LoG(Laplacian of Gaussian)、DoG(Difference of Gaussian)等。
- 密集提取的方式则是从图像中按固定的步长、尺度提取出大量的局部特征描述,大量的局部描述尽管具有更高的冗余度,但信息更加丰富,后面再使用词包模型进行有效表达后通常可以得到比兴趣点检测更好的性能.常用的局部特征包括SIFT(Scale-Invariant Feature Transform,尺度不变特征转换)、HOG(Histogram of Oriented Gradient,方向梯度直方图)、LBP(Local Binary Pattern,局部二值模式)等等。
从上表可以看出,2012年之前历年最好的物体分类算法都采用了多种特征年采样方式上密集提取与兴趣点检测相结合,底层特征描述也采用了多种特征描述子,这样做的好处是,在底层特征提取阶段,通过提取到大量的冗余特征,最大限度的对图像进行底层描述,防止丢失过多的有用信息,这些底层描述中的冗余信息主要靠后面的特征编码和特征汇聚得到抽象和简并。事实上,近年来得到广泛关注的深度学习理论中一个重要的观点就是手工设计的底层特征描述子作为视觉信息处理的第一步,往往会过早地丢失有用的信息,直接从图像像素学习到任务相关的特征描述是比手工特征更为有效的手段。
-
特征编码: 密集提取的底层特征中包含大量的冗余与噪声,为提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,从而获得更具区分性、更加鲁棒的特征表达,这一步对物体识别的性能具有至关重要的作用,因而大量的研究工作都集中在寻找更加强大的特征编码方法,重要的特征编码算法包括向量量化编码、核词典编码、稀疏编码、局部线性约束编码、显著性编码、Fisher向量编码、超向量编码等。
- 向量量化编码:向量量化编码是简单的特征编码,它的出现甚至比词包模型的提出还要早.向量量化编码是通过一种量化的思想,使用一个较小的特征集合(视觉词 典)来对底层特征进行描述,达到特征压缩的目的. 向量量化编码只在最近的视觉单词上响应为1,因而又称为硬量化编码、硬投票编码,这意味着向量量化编码只能对局部特征进行很粗糙的重构.但向量量化编码思想简单、直观,也比较容易高效实现,因而从2005年第一届PASCAL VOC竞赛以来,就得到了广泛的使用.
- 软量化编码(核词典编码):在实际图像中,图像局部特征常常存在一定的模糊性,即一个局部特征可能和多个视觉单词差别很小,这个时候若使用向量量化编码将只利用距离最近的视觉单词,而忽略了其他相性很高的视觉单词.为了克服这种模糊性问题, van Gemert 等人提出了软量化编码(又称核视觉词典编码)算法:局部特征不再使用一个视觉单词描述,而是由距离最近的犓个视觉单词加权后进行描述,有效解决了视觉单词的模糊性问题,提高了物体识别的精度。
- 稀疏编码:稀疏表达理论近年来在视觉研究领域得到了大量的关注,稀疏编码通过最小二乘重构加入稀疏约束来实现在一个过完备基上响应的稀疏性。约束是最直接的稀疏约束,但通常很难进行优化,近年来更多使用的是约束, 可以更加有效地进行迭代优化,得到稀疏表达.2009年Yang等人将稀疏编码应用到物体分类领域, 替代了之前的向量量化编码和软量化编码,得到一 个高维的高度稀疏的特征表达,大大提高了特征表达的线性可分性,仅仅使用线性分类器就得到了当时最好的物体分类结果,将物体分类的研究推向了 一个新的高度上.稀疏编码在物体分类上的成功也不难理解,对于一个很大的特征集合(视觉词典),一个物体通常只和其中较少的特征有关,例如,自行车通常和表达车轮、车把等部分的视觉单词密切相关, 与飞机机翼、电视机屏幕等关系很小,而行人则通常在头、四肢等对应的视觉单词上有强响应.但稀疏编码存在一个问题,即相似的局部特征可能经过稀疏编码后在不同的视觉单词上产生响应,这种变换的不 连续性必然会产生编码后特征的不匹配,影响特征 的区分性能.
- 局部线性约束编码:为了解决稀疏编码产生的特征不匹配问题,研究人员又提出了局部线性约束编码。它通过加入局部线性约束,在一个局 部流形上对底层特征进行编码重构,这样既可以保 证得到的特征编码不会有稀疏编码存在的不连续问 题,也保持了稀疏编码的特征稀疏性.局部线性约束 编码中,局部性是局部线性约束编码中的一个核心 思想,通过引入局部性,一定程度上改善了特征编码 过程的连续性问题,即距离相近的局部特征在经过 编码之后应该依然能够落在一个局部流形上.局部 线性约束编码可以得到稀疏的特征表达,与稀疏编 码不同之处就在于稀疏编码无法保证相近的局部特 征编码之后落在相近的局部流形.从上表可以看出, 2009年的分类竞赛冠军采用了混合高斯模型聚类 和局部坐标编码(局部线性约束编码是其简化版 本),仅仅使用线性分类器就取得了非常好的性能.
- 显著性编码:显著性编 码引入了视觉显著性的概念,如果一个局部特征 到最近和次近的视觉单词的距离差别很小,则认为 这个局部特征是不“显著的”,从而编码后的响应也 很小.显著性编码通过这样很简单的编码操作,在 Caltech101/256,PASCAL VOC2007等数据库上 取得了非常好的结果,而且由于是解析的结果,编码 速度也比稀疏编码快很多.Huang等人发现显著 性表达配合最大值汇聚在特征编码中有重要的作 用,并认为这正是稀疏编码、局部约束线性编码等之 所以在图像分类任务上取得成功的原因.
- 超向量编 码与Fisher向量编码:超向量编 码,Fisher向量编码是近年提出的性能最好的 特征编码方法,其基本思想有相似之处,都可以认为 是编码局部特征和视觉单词的差.Fisher向量编码 同时融合了产生式模型和判别式模型的能力,与传 统的基于重构的特征编码方法不同,它记录了局部 特征与视觉单词之间的一阶差分和二阶差分.超向 量编码则直接使用局部特征与最近的视觉单词的差 来替换之前简单的硬投票.这种特征编码方式得到 的特征向量表达通常是传统基于重构编码方法的 M倍(M是局部特征的维度).尽管特征维度要高出 很多,超向量编码和Fisher向量编码在PASCAL VOC、ImageNet等极具挑战性、大尺度数据库上获 得了当时最好的性能,并在图像标注、图像分类、图 像检索等领域得到应用.2011年ImageNet分类竞 赛冠军采用了超向量编码,2012年VOC竞赛冠军 则是采用了向量量化编码和Fisher向量编码.
空间特征约束: 特征编码之后一般会经过空间特征约束,也称作空间特征汇聚。特征汇聚是指在一个空间范围内,对每一维特征取最大值或者平均值,可以获得一个紧致的、一定特征不变形的特征表达,同时也避免了使用特征 集进行图像表达的高额代价.金字塔特征匹配是一种常用的特征聚会方法,这种方法提出将图像均匀分块,在分块内做特征汇聚。
通过分类器分类: 经过前面步骤之后一张图像可以用一个固定维度的向量进行描述,接下来就是学习一个分类器对图像进行分类。通常使用的分类器包括K紧邻、神经网络、SVM(Support Vector Machine, 支持向量机)、随机森林等。而使用核方法的SVM是最为广泛的分类器,在传统图像分类任务上性能很好。
展开全文



